Multiple GPUs - Paxoo/PyTorch-Best_Practices GitHub Wiki
DataParallel
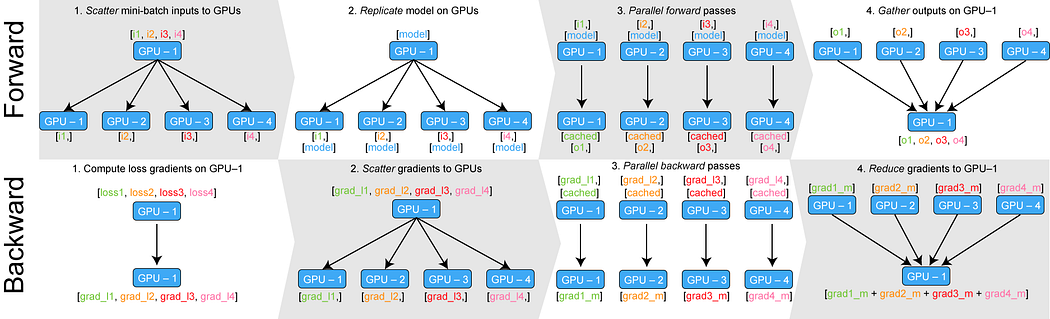
Forward
- The mini-batch is split on GPU:0, move min-batch to all different GPUs
- Copy model out to GPUs
- Forward pass occurs in all different GPUs
- Gather Outputs on GPU:0
Backward
- Compute loss with regards to the network outputs on GPU:0
- Return losses to the different GPUs
- Calculate gradients on each GPU
- Sum up gradients on GPU:0 and use the optimizer to update model on GPU:0
DistributedDataParallel
Official Guide for DDP: Getting Started with Distributed Data Parallel
DPP with ZeroRedundancyOptimizer for less memory usage: Shard Optimizer States with ZeroRedundancyOptimizer
Blog Post: how-to-scale-training-on-multiple-gpus

- DDP uses multiple processes, one process per GPU; Use for single or multiple machines
- Only gradients are passed between the processes
- Each process loads its own mini-batch from disk and passes it to its GPU.
- Each GPU does its forward pass, loss and gradient calculation.
- At the end of the backwards pass, every node has the averaged gradients, ensuring that the model weights stay synchronized.
Code
import argparse
import torch.multiprocessing as mp
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--distributed', type=str2bool, default=False, help='use DistributedDataParallel instead of DataParallel for better speed')
parser.add_argument('--n_GPUs', type=int, default=1, help='the number of GPUs for training')
parser.add_argument('--rank', type=int, default=0, help='rank of the distributed process (gpu id). 0 is the master process.')
parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run')
args = parser.parse_args()
mp.spawn(train, nprocs=args.n_GPUs, args=(args,), join=True)
Demo
import os
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
def init_process(rank, args):
if args.distributed:
torch.manual_seed(0)
torch.cuda.manual_seed(0)
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '8888'
# initialize the process group
# single-node training / single machine
dist.init_process_group('nccl', rank=args.rank, world_size=args.n_GPUs)
def cleanup(args):
if args.distributed:
dist.destroy_process_group()
def train(rank, args):
init_process(rank, args)
print(f"Rank {rank}/{n_GPUs} training process initialized.\n")
# create model and move it to GPU with id rank
torch.cuda.set_device(rank)
model = ConvNet().cuda(rank)
model = DDP(model, device_ids=[rank])
# define loss function (criterion) and optimizer
criterion = nn.MSELoss().cuda(rank)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=args.n_GPUs,
rank=rank
)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(rank, non_blocking=True)
labels = labels.cuda(rank, non_blocking=True)
...
cleanup()
Save and load
def save_checkpoint(state, save_path: str, is_best: bool = False):
torch.save(state, save_path)
if is_best:
shutil.copyfile(save_path, os.path.join(save_dir, 'best_model.ckpt'))
# save
if torch.distributed.get_rank() == 0:
is_best = val_top1 > best_prec1
best_prec1 = max(val_top1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'arch': args.arch,
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer': optimizer.state_dict(),
}, is_best, writer.log_dir)
# load
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
checkpoint = torch.load(args.resume, map_location = lambda storage, loc: storage.cuda(args.gpu))
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
print("=> loaded checkpoint '{}' (epoch {})".format(args.resume, checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(args.resume))
dist.barrier()
Shard Optimizer States
from torch.distributed.optim import ZeroRedundancyOptimizer
...
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
if args.use_zero:
optimizer = ZeroRedundancyOptimizer(
ddp_model.parameters(),
optimizer_class=torch.optim.Adam,
lr=0.01
)
else:
optimizer = torch.optim.Adam(ddp_model.parameters(), lr=0.01)
....
# forward pass
# backward pass
# update parameters
optimizer.step()