ICP7 - PardhaSaradhi74/Python GitHub Wiki
NAME: Pardha Saradhi,Ramineni
CLASS ID: 38
Python ICP7
In this class we dealt with text processing using Natural Language Toolkit(NLTK) by applying different methods on text data like unigram, bigram, trigram, tokenization, pos tagging, lemmatization, normalization, entity extraction, language model.
Problem1:
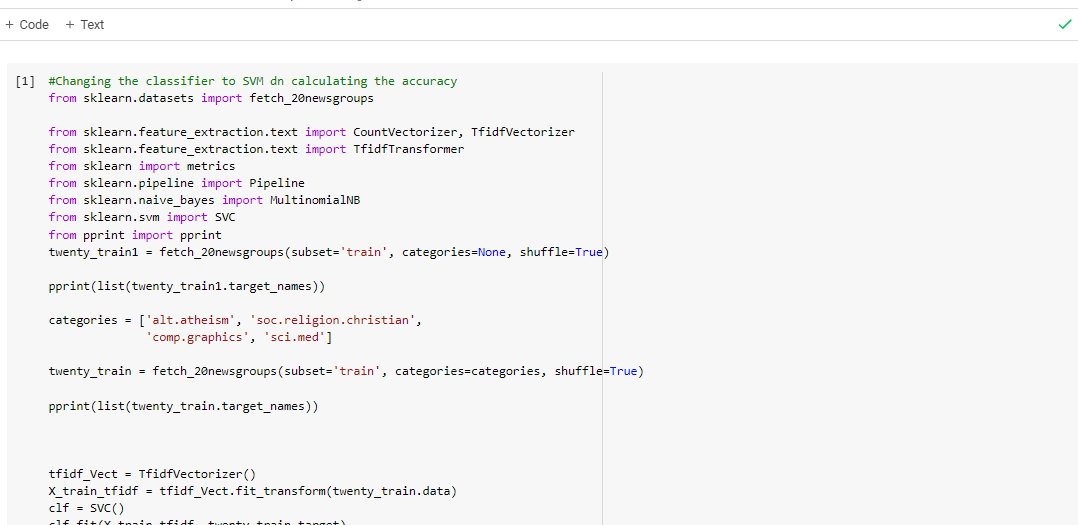
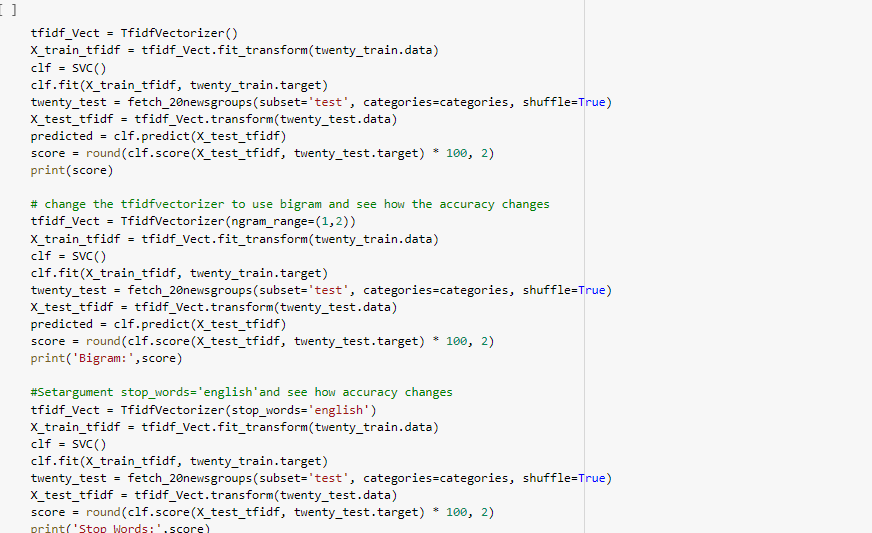
Change the classifier in the given code to a. SVM and see how accuracy changes
Solution:
Imported required libraries and read a dataset from sklearn datasets then prepared training and testing data and transformed the data using TF-IDF vectorizer.Below is the screenshot working code.
b. change the tfidfvectorizer to use bigram and see how the accuracy changes
c. Set argument stop_words='english' and see how accuracy changes
Now using argument stop words as english in TF-IDF vectorizer and calculating accuracy score.
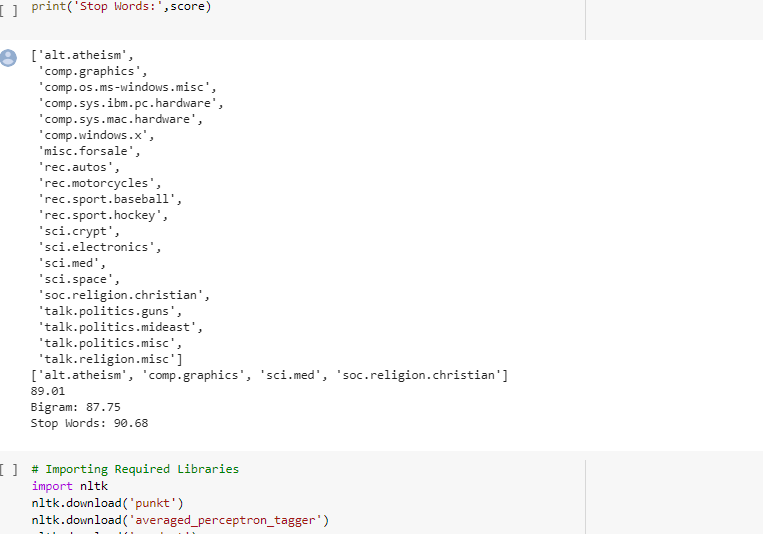
All scores are printed like this below.
Problem 2.
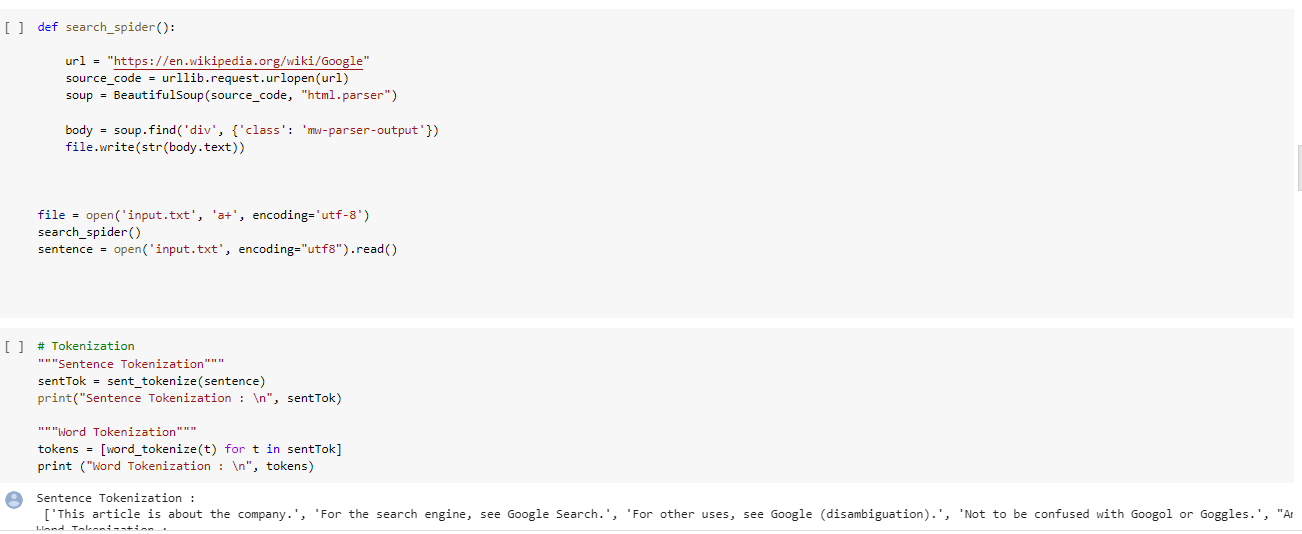
Extract the following web URL text using BeautifulSoup https://en.wikipedia.org/wiki/Google
Solution:
Extracted text content of google wikipedia web page using beautiful soup get_tetx() method and performed some operations like removing spaces, splitting words and at the end appending to a file. Below is screenshot of working code.
Problem 3.
Save it in input.txt
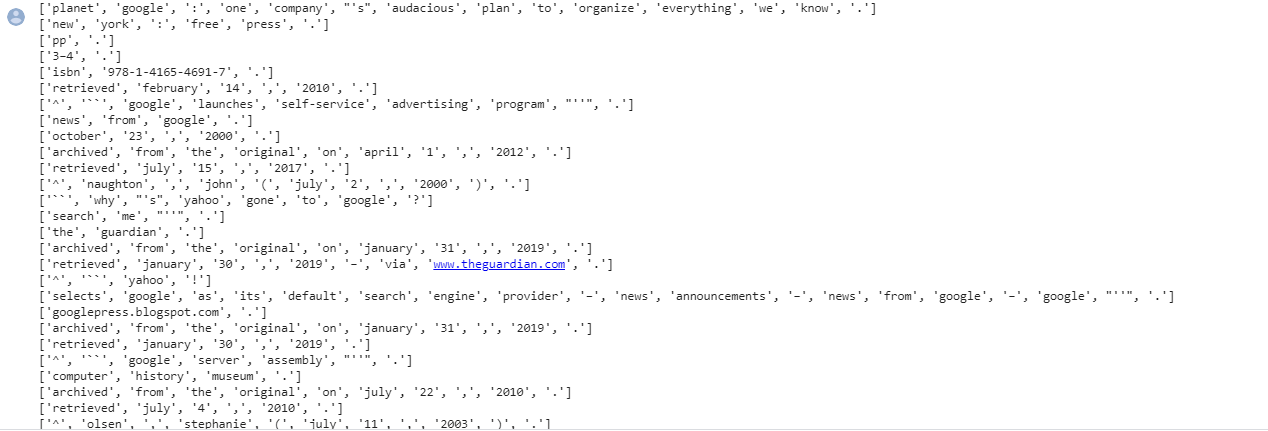
Below is screenshot of output text extracted from link.
Problem 4.
Apply the following on the “input.txt”and show output:
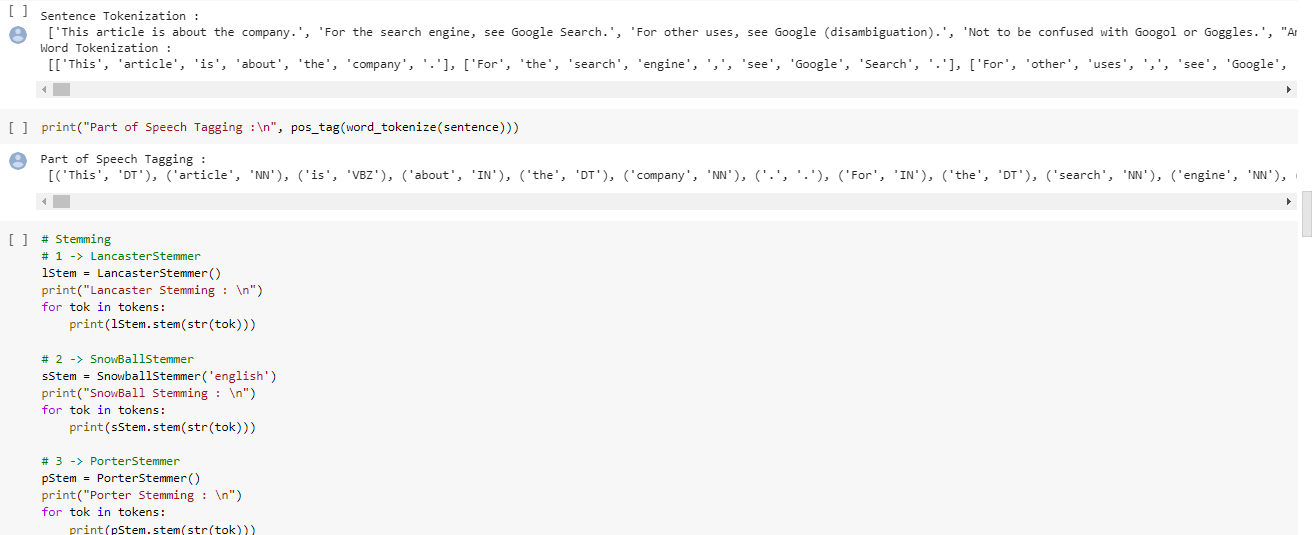
a. Tokenization b. POS c. Stemming d. Lemmatization e. Trigram f. Named Entity Recognition
Solution:
Tokenization: Tokenization is process of breaking complete text into words known as tokens and below is screenshot of working code.
POS: This is the process of classifying text into parts-of-speech and labelling them, below is screenshot of working code.
Stemming: Stemming reduces a word into their root form, below is screenshot of working code.
Lemmatization: It is process of defining POS and applying normalization rules on each POS, below is screenshot of working code.
Trigram: It states continuous sequence of words from given text, below is screenshot of working code.
Named Entity Recognition: It states that classifying elements in text into pre-defined categories, below is screenshot of working code.