ICP4 - PardhaSaradhi74/Python GitHub Wiki
Studentname
PARDHA SARADHI,RAMINENI
CLASSID
38
In this class we dealt with introduction to machine learning like supervised, unsupervised and reinforcement learning the introduction to classification algorithms like KNN algorithm, Naive Bayes, Support Vector Machine with some use cases to get hands-on experience.
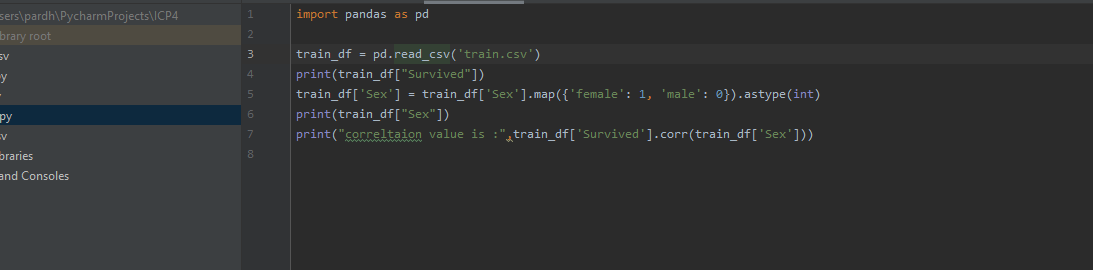
Problem1: find the correlation between ‘survived’(target column) and ‘sex’ column for the Titanic use case in class.Do you think we should keep this feature?
Answer:
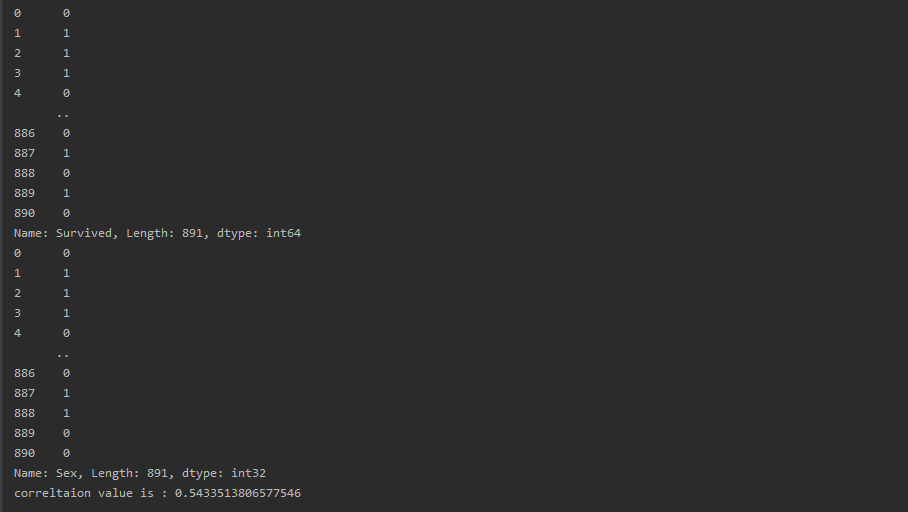
Using Pandas read the use case data and mapped the 'Sex' column categorical values to numerical values then found correlation of Survived column against Sex column using corr() function. Below is the screenshot attached of working code and output.
Problem2: Implement Naïve Bayes method using scikit-learn library.Use dataset available in https://umkc.box.com/s/ea6wn1cidukan67t02j60nmp1ljln3kd.Use train_test_split to create training and testing part.Evaluate the model on testing partusing score and classsification report.
Answer))
In this initially imported basic libraries like pandas and scikit learn library then read csv file for data and for training the model dropped a column named 'Type' and assigned to X and used column 'Type' and assigned to y then using train_test_split splitted the data to training set(80%) and testing set(20%). Imported gaussianNB method and fitted our train data to it and predicted using test data. At the end accuracy is found using accuracy_score on test and predicted data and classification report is generated similarly. Below is screenshot attached of working code and output.
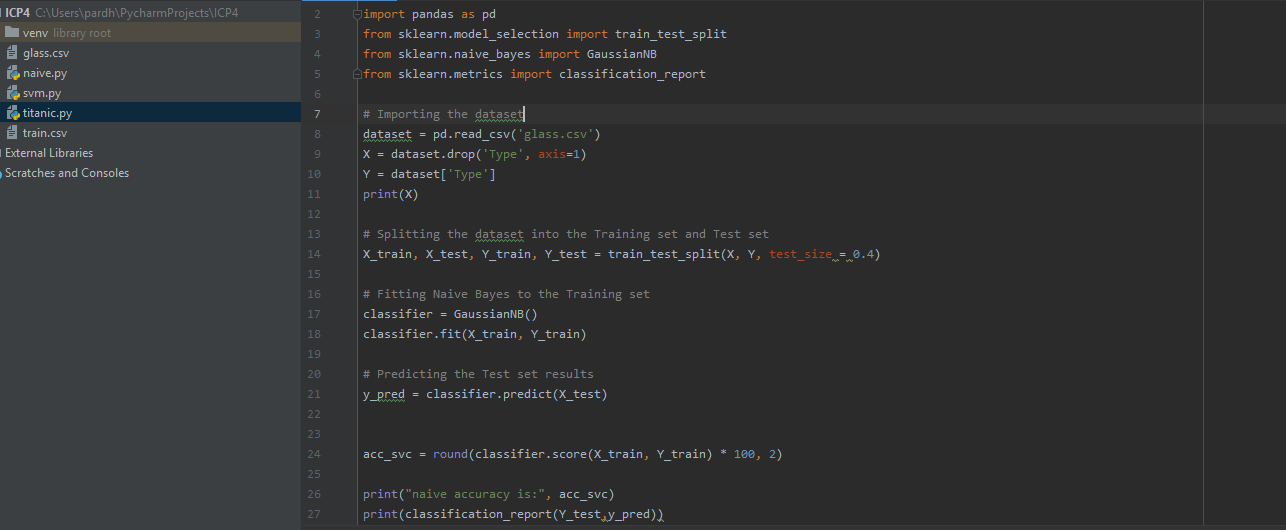
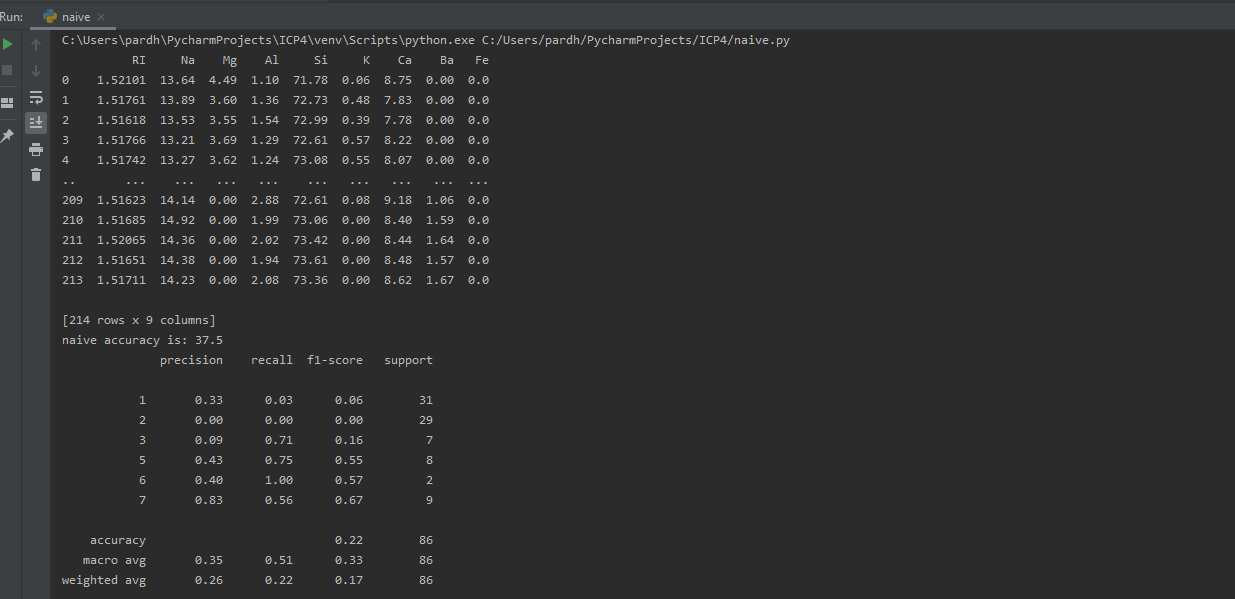
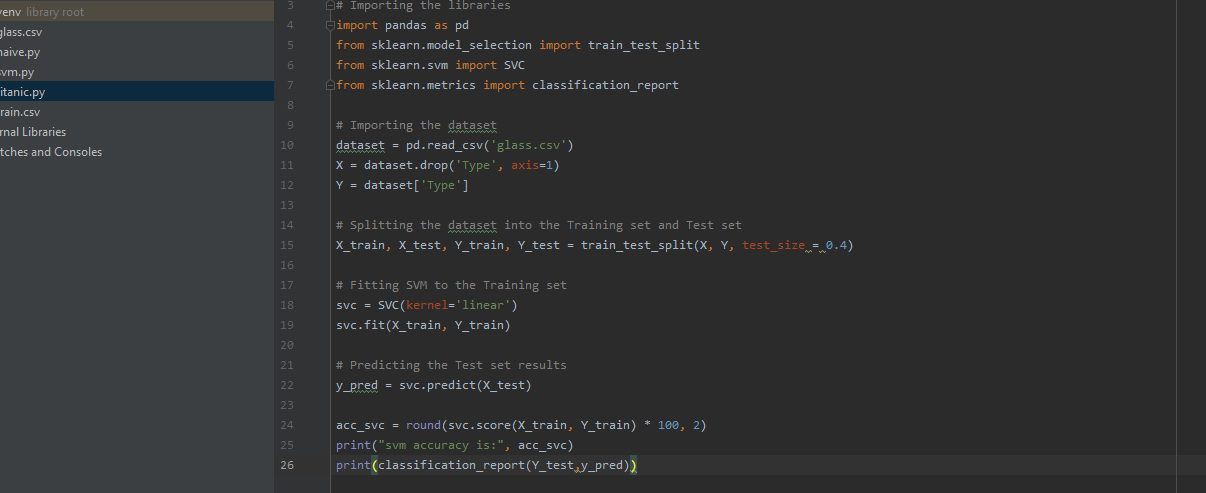
Problem3: Implement Linear SVM method using scikit-learn library.Use dataset available in https://umkc.box.com/s/ea6wn1cidukan67t02j60nmp1ljln3kd.Use train_test_split to create training and testing part.Evaluate the model on testing partusing score and classsification report.
Answer))
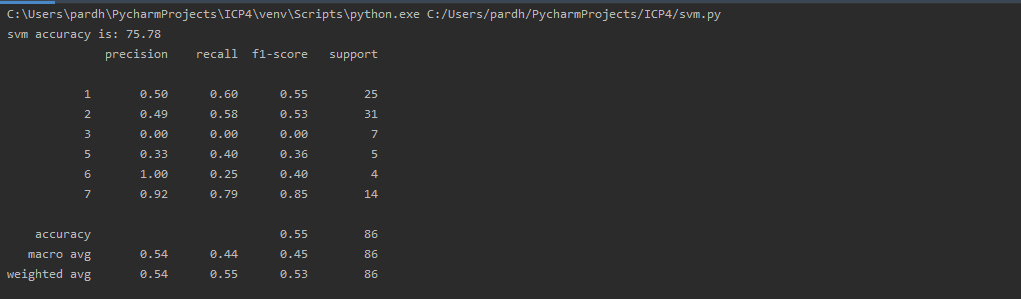
This task is performed same as task 2 but used SVM algorithm to check the accuracy score. In SVM we used linear model and fitted our training data to it and predicted using testing data.Accuracy score and classification reports are generated at the end.Below is the screenshot attached of working code and output.