Android NN Survey - PaddlePaddle/Mobile GitHub Wiki
Introduction
The Android Neural Networks API (NNAPI) is an Android C API designed for running computationally intensive operations for machine learning on mobile devices. NNAPI is designed to provide a base layer of functionality for higher-level machine learning frameworks (such as TensorFlow Lite, Caffe2, or others) that build and train neural networks. The API is available on all devices running Android 8.1 (API level 27) or higher.
Architecture
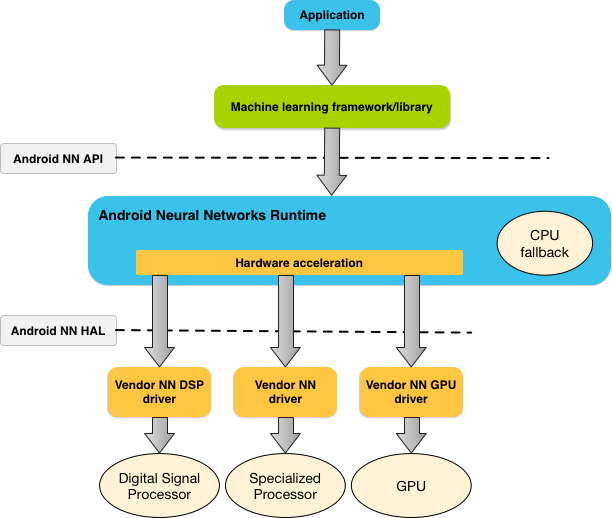
- NNAPI supports inferencing by applying data from Android devices to previously trained, developer defined models.
- Apps typically would not use NNAPI directly, but would instead directly use higher-level machine learning frameworks. For example, Android apps could use PaddlePaddle mobile, which will internally use NNAPI to perform hardware-accelerated inference operations on supported devices.
- Based on App requirements and the hardware capability on the Android device, NNAPI can distribute computation on the following on-device processors:
- dedicated neural networks hardware
- Graphic Processing Units (GPU)
- Digital Signal Processing Unit (DSP)
- For devices that lack a specialized vendor driver, the NNAPI runtime relies on optimized code to execute requests on the CPU.
Neural Networks API Programming Model
The following diagram shows the basic programming flow
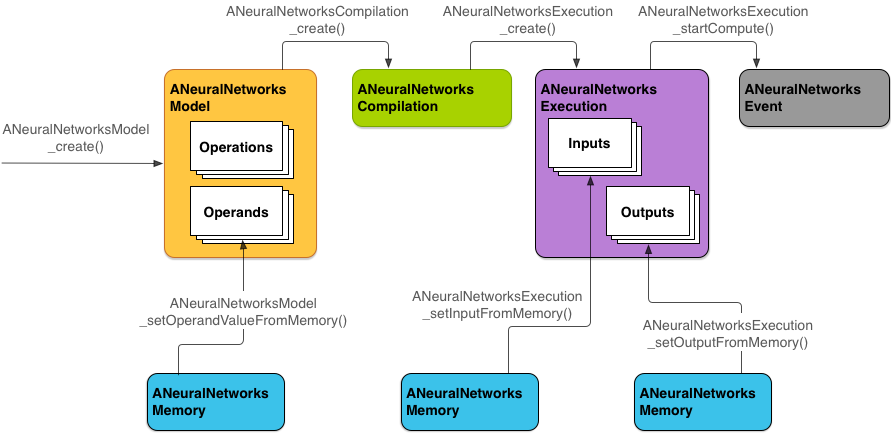
The NNAPI has 4 main abstractions:
- Model: A model is a computational graph that defines the computations. Model creation is a synchronous process. Once a model is created successfully, it can be reused across threads and compilations.
- Compilation: Represents a configuration for compiling an NNAPI model into lower-level code. Creating a compilation is a synchronous operation, but once successfully created, it can be reused across threads and executions.
- Memory: Represents shared memory, memory mapped files, and similar memory buffers. Memory buffers are used by the NNAPI runtime for efficient transfer of data to drivers. Typically, an app creates one shared memory buffer that contains every tensor needed to define the model.
- Execution: This is an interface that is used for applying the NNAPI model to user data and get results. Execution is an asynchronous operation. Multiple threads can wait on the same execution. When the execution completes, all threads will be released.
Operands and Operations
Operands
Operands are data objects used in defining the computational graph. These include the input of the model, output of the model, constants and intermediate data that flows from one operation to the other. There are two types of operands in NNAPI:
- Scalars: Scalars are single numbers. NNAPI supports scalar values in 32-bit floating point, 32-bit integer, and unsigned 32-bit integer format.
- Tensors: Tensors are n-dimensional arrays(The maximum Tensor dimension supported by most operations is 4). NNAPI supports tensors with 32-bit integer, 32-bit floating point, and 8-bit quantized values.
Operations
An operation specifies the computations to be performed. Each operation consists of these elements:
- an operation type (for example, addition, multiplication, convolution)
- a list of indexes of the operands that the operation uses for input
- a list of indexes of the operands that the operation uses for output
See the NNAPI API reference for each operation's expected inputs and outputs.
C++ API
The programming model of the C NNAPI can be understood by an example. The diagram below represents a model with two operations: an addition followed by a multiplication. The model takes an input tensor and produces one output tensor.
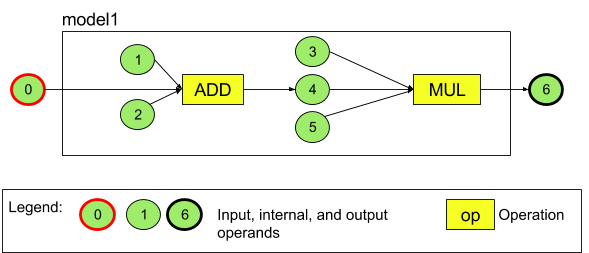
- Load Model Parameters
// Create a memory buffer from the file that contains the trained data.
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
-
Create Model: A model is the fundamental unit of computation in NNAPI. Each model is defined by one or more Operands and Operations. In order to build a model, follow these steps:
- Define an empty Model:
ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);- Add operands to the model:
// In our example, all our tensors are matrices of dimension [3, 4]. ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are useful for quantized tensors. tensor3x4Type.zeroPoint = 0; // These fields are useful for quantized tensors. tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims; // We also specify operands that are activation function specifiers. ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL; // Now we add the seven operands, in the same order defined in the diagram. ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6- Set parameter values from the loaded file:
// In our example, operands 1 and 3 are constant tensors whose value was // established during the training process. const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize. ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor); // We set the values of the activation operands, in our example operands 2 and 5. int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));- Add every computation operation to the model:
// We have two operations in our example. // The first consumes operands 1, 0, 2, and produces operand 4. uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes); // The second consumes operands 3, 4, 5, and produces operand 6. uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multInputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);- Identify input and output operands
// Our model has one input (0) and one output (6). uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);- Finish definition of model:
ANeuralNetworksModel_finish(model); -
Compile the Model: Compilation determines the processors on which the model will be executed and also asks the corresponding drivers to prepare for execution. To compile, follow the following steps:
- Create compilation instance:
// Compile the model. ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);- Set compilation preferences:
// Ask to optimize for low power consumption. ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);A list of valid preferences can be found here.
- Finalize compilation definition:
ANeuralNetworksCompilation_finish(compilation); -
Execute the model: Execution step applies the model to a set of inputs and stores the computation result to user buffers or memory spaces allocated by the application. Follow the following steps for execution:
- Create a new execution instance:
ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);- Specify from where the input values are read:
// Set the single input to our sample model. Since it is small, we won’t use a memory buffer. float32 myInput[3, 4] = { ..the data.. }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));- Specify where the output values are written:
// Set the output. float32 myOutput[3, 4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));- Schedule the execution to start asynchronously:
ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);- Wait for the execution to complete:
ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1); -
Cleanup: The cleanup step handles the freeing of internal resources used for the computation.
ANeuralNetworksCompilation_free(compilation);
ANeuralNetworksModel_free(model);
ANeuralNetworksMemory_free(mem1);