AIDA Parallelization - PNapi90/DESPEC-Analysis-Framework GitHub Wiki
Due to the large amount of data in AIDA, almost all calculations of the clusterization process are parallelized.
For all events e_i, the time difference to all following events e_j with j > i is calculated. This can be expressed as a triangular matrix with dimensions n x n where n is the total amount of events in the AIDA MBS stream event for a certain strip type (x,y,z).
In total, N time differences have to be calculated.
N = [sum_{i = 0}^{n} (n-i)] - n
Since the time difference of e_i <-> e_i is 0, n events are subtracted from the total amount of calculations.
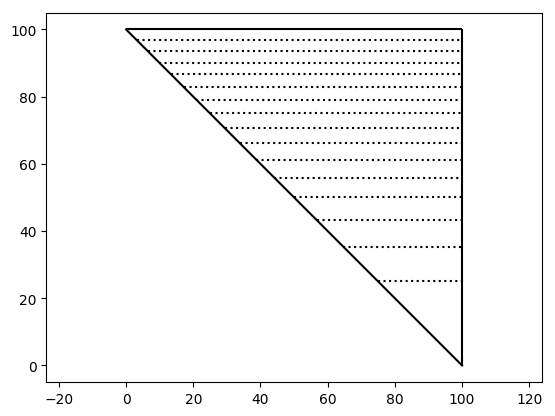
To get a (roughly) equal amount of calculations per thread, the triangular matrix is cut into pieces with almost the same area. In the picture below, a cut of a triangle with n=100 into 16 parts of quasi-equal areas can be seen.
This is achieved via
//area of triangular matrix
double A_triangular = pow(amount_of_data_points,2)/2.;
std::vector<double> spacingTmp(am_threads,0);
//aOld is upper edge-length of old trapezoid
//(beginning: full length of triangular matrix)
double aOld = (double) amount_of_data_points;
double n = (double) am_threads;
//spacingTmp describes edge-length of trapeziod in triangular matrix
//of equal area Ai with sum(Ai) = A_triangular
for(int i = 0;i < am_threads-1;++i){
spacingTmp[i] = aOld - sqrt((aOld*aOld*n - 2.*A_triangular)/n);
aOld -= spacingTmp[i];
}
//last area is traingle, not trapezoid (=> Ai = 0.5*aOld^2)
spacingTmp[am_threads-1] = aOld;
int tmpPos = 0;
int delta = 0;
//threads have to calculate integer value of rows
//=> calculate integer spacing (may yield slightly unequal areas Ai)
tmpPos = (int) spacingTmp[0];
delta = (tmpPos > 0) ? tmpPos : 1;
//first trapezoid starting at 0
spacing_per_thr[0][0] = 0;
spacing_per_thr[0][1] = delta;
//integer spacing with distance at least = 1
for(int i = 1;i < am_threads-1;++i){
tmpPos = (int) spacingTmp[i];
delta = (tmpPos > 0) ? tmpPos : 1;
spacing_per_thr[i][0] = spacing_per_thr[i-1][1];
spacing_per_thr[i][1] = spacing_per_thr[i][0] + delta;
}
//last thread (triangle) goes up to amount_of_data_points
spacing_per_thr[am_threads-1][0] = spacing_per_thr[am_threads-2][1];
spacing_per_thr[am_threads-1][1] = amount_of_data_points;
where spacing_per_thr is the array that holds the length (in y direction) of the trapezoids(spacing_per_thr[][0] is the beginning of the trapezoid, spacing_per_thr[][1] the end). This part of the code can be found in TX_Matrix.cxx.
After the time differences are calculated, all strip number values of each event e_j coincident to event e_i are written into an array x. This array is then sorted in ascending order via std::sort(x,x+len) (where len is the amount of coincident events of event e_i).
Since neighboring events have a strip number difference of 1, strip cluster can be built directly by going through the list x from left to right. The parallelization of this processed is also performed using the same triangular approach. However, the areas for each thread are not almost equal anymore. Due to the strongly reduced amount of data that has to be calculated by each thread, this is not a severe problem performance-wise.