The Kepler architecture - OrangeOwlSolutions/General-CUDA-programming GitHub Wiki
The Kepler architecture is the third to last NVIDIA architecture introduced in early 2102. It features 7.1 billion transistors and its principal design goals were improving, over Fermi, power efficiency, simplify parallel program design and increase the double precision performance. In particular, the important innovations of such an architecture have been:
- enhanced SMs;
- additional caching capabilities;
- more bandwidth at each level of the memory hierarchy;
- faster DRAM;
- Dynamic Parallelism;
- Hyper-Q.
As a result, the K20X is able to offer more than 1 TFLOPS of peak double-precision computing power with 3 times the performance per Watt compared to Fermi designs.
In the sequel, its description is incremental against Fermi. Please, have a look at The Fermi architecture article.

Cores running at a high clock rate enable achieving a high throughput, but are demanding in terms of power. To improve the performance per Watt, Kepler uses a slower, and thus less power consuming, clock. The computational performance loss of a slower clock is compensated by a larger number of cores. The Kepler architecture introduces also a feature called “GPU Boost” that dynamically increases the clock speed to improve performance.
Each SM, addressed to as SMX in Kepler, features 192 single-precision CUDA cores, 64 double-precision units, 32 SFUs and 32 load/store units. Kepler supports the full IEEE 754‐2008 compliant single‐ and double‐precision arithmetics as in Fermi, including FMA operation. A Kepler GPU features 15 (or 13, or 14, depending on the model) SMXs and six 64‐bit memory controllers. In particular, the above figure illustrates the Kepler K20X chip block diagram, containing 15 streaming multiprocessors (SMs) and six 64-bit memory controllers.
One of the design targets of Kepler was significantly increasing the double precision performance, since double precision arithmetics is crucial for many computational applications.
Each SMX has 8 times the number of SFUs of the Fermi architecture.

As in Fermi, a warp consists of 32 parallel threads.
Each SMX has four warp schedulers, each with dual instruction dispatch unit. Overall, eight instruction dispatch units allow four warps to be executed concurrently. The quad warp scheduler selects four warps, and two independent instructions per warp can be forwarded per cycle. Unlike Fermi, the Kepler architecture allows double precision instructions to be paired with other instructions. The Kepler K20X architecture (compute capability 3.5) can schedule 64 warps per SM for a total of 2,048 threads resident in a single SM at a time. Of those 64 warps, only 4 will run concurrently.
Previously to Kepler, sharing data between threads in a warp required passing the data through shared memory, so involving shared memory load-store operations. Shuffle instructions allow threads within a warp to share data, by reading values from any other thread in the warp.
Shuffle operations are convenient over shared memory since load-store operations are performed in a single step. Shuffle instructions can also reduce the amount of shared memory required per block, since shared memory is no longer needed to exchange data within a warp. In the case of FFT, which requires data sharing within a warp, a 6% performance gain has been observed.
The throughput of atomic operations is substantially improved over Fermi. More in detail, the throughput of such operations as applied to a common global memory address is improved by 9x. Atomic operations can often run at speeds close to those of global load operations. This speed increase makes atomics fast enough to be used more frequently than before, especially in kernel inner loops.
In Fermi, using a texture required manually binding and unbinding the texture references to memory addresses. This was needed since textures had to be assigned a “slot” in a fixed‐size binding table. The number of slots in that table limited the number of textures (128) a program could simultaneously deal with. Also, texture references could only be declared as static global variables and could not be passed as function arguments.
Kepler changes the way textures are managed. More in detail, Kepler GPUs and CUDA 5.0 introduce a bindless textures not requiring manual texture binding/unbinding. Texture objects use now the cudaTextureObject_t class, so that textures can be passed as arguments just as if they were pointers. There is no need to know at compile time which textures will be used at run time, which makes binding tables obsolete, execution more dynamic, programming more flexible and texture objects not subject to the hardware limit of 128 texture references.
Finally, each SMX contains 16 texture units with a 4x increase as compared to Fermi.
Memory hierarchy in Kepler is organized likewise Fermi.
The number of registers accessible by each thread has been quadrupled as compared to Fermi, so that each thread can now access up to 255 registers. This can speedup codes that exhibit high register pressure or spilling in Fermi.
Each SMX has 64KB of chip memory configurable as 48KB of shared memory and 16KB of L1 cache or the reverse. In addition, Kepler enables a configuration with 32KB of shared memory and 32KB of L1 cache. To guarantee the increased throughput of each SMX, the shared memory bandwidth for 64 bit or larger operations has been doubled as compared to Fermi.
Kepler cards feature 1536KB of L2 cache, so doubling the amount of L2 cache available for Fermi. Also its bandwidth is doubled as compared to Fermi.
As for Fermi, Kepler’s memory system is protected by SECDED ECC code. ECC checkbit fetch handling has been optimized and the performance gap between ECC on-vs-off has been reduced of 66%, on average.
Compute capability 3.5 cards (as Tesla K20c/K20X and GeForce GTX Titan/780, for example) introduce the possibility for read-only global memory data to be loaded through the same cache used by the texture. Each SMX has a 48KB read-only cache and this feature is enabled by simply employing a standard pointer without the need to bind a texture. With Fermi, this cache was accessible only by the texture unit and the data were to be loaded through this path explicitly by mapping them data as textures, but this approach had the limitations already evidenced above.
Since read-only cache has a separate memory pipe and relaxed memory coalescing rules, using this feature can improve memory-bound kernels. Furthermore, the use of such a cache is beneficial because it takes loads off of the L1 cache path.
The compiler automatically exploits read-only cache when possible. Since such a cache is incoherent with respect to writes, a necessary condition is that the data must be read-only. To inform the compiler of this condition, the pointers used for loading such data should be decorated with both the const and __restrict__ qualifiers. Obviously, adding these qualifiers can improve the quality of the disassembled code via other mechanisms already on previous GPUs. It should be noticed that there can be cases when the code is too complex for the compiler to be able to detect that the read-only data cache is safe to use. In these circumstances, the __ldg() intrinsic can be used to force the load to go through the read-only data cache. It should be also noticed that the read-only data cache we are talking about is different from the constant cache accessed via the __constant__ qualifier. Data loaded through the latter cache are generally relatively small in size and are accessed uniformly (namely, all threads in a warp should access the same datum at any given time) to have satisfactory performance. Opposite to that, data loaded through the read-only data cache can be much larger and can be accessed in non-uniformly.
Finally, the read-only data cache performs error correction through parity check. In case of a parity error, the failed line is automatically invalidated and the data read from L2 is activated.
One of the goals of Kepler has been to simplify programmability. With dynamic parallelism, kernels can invoke other kernels and so they have the capability to independently launch additional workloads as needed at runtime without returning control to the host, so freeing the CPU for other tasks, or communicating with the host with possible data exchanges.

Dynamic parallelism broadens the range of applications that can benefit of GPU acceleration since small and medium sized parallel workloads can be launched dynamically where it was too expensive to do so before. It also enables setting up and optimizing recursive and data-dependent execution patterns.
Besides making programs easier to be created, by providing the flexibility to adapt to the amount and form of parallelism during execution, a wider range of parallel work kinds can be exposed and a more efficient use of the GPU can be made as a computation evolves. This capability allows less‐structured, more complex tasks to run easily and effectively, enabling larger portions of an application to run entirely on the GPU.
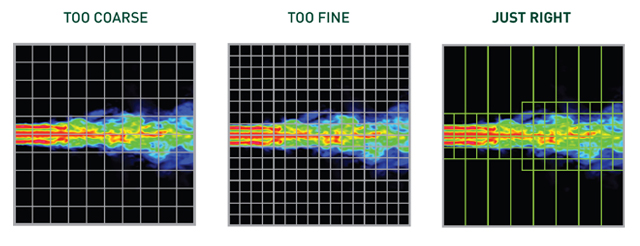
The classical example illustrating when dynamic parallelism could be of interest is performing a numerical simulation requiring a non-uniform computational grid with mesh refinements in the regions with higher spatial changes. With previous architectures, the alternative was using a uniformly coarse grid to prevent requiring too many GPU resources or a uniformly fine grid to capture all the features of the solution. However, these possibilities were connected to a risk of missing simulation features or spending to many resources of regions of faint interest. With dynamic parallelism, the grid resolution can be dynamically determined at runtime. Although this would be accomplished even using a sequence of CPU-launched kernels, dynamic parallelism makes programming much simpler in this case and reduces interruptions of the CPU and host-device data transfers.
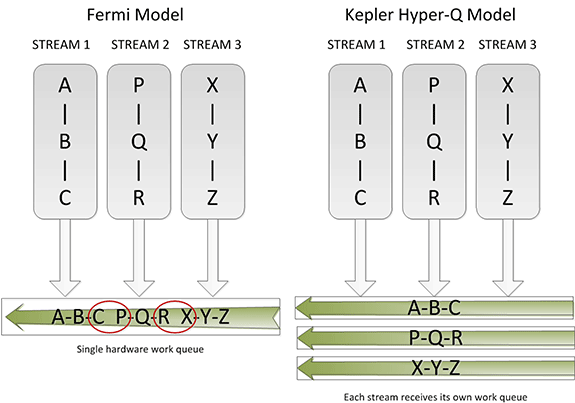
Hyper-Q enables more concurrency on the GPU, thereby maximizing GPU utilization, reducing CPU idle times and increasing overall performance.

Hyper‐Q enables multiple CPU cores to launch work on a single GPU simultaneously, thereby increasing GPU utilization and reducing CPU idle times. Hyper‐Q increases the total number of connections (work queues) between the host and the GPU by allowing 32 simultaneous connections, which is much more if compared to the single connection available with Fermi. Applications that were previously limited by false dependencies, thereby limiting achieved GPU utilization, can see performance improvements, in principle, up to a 32x without changing any existing code.
[1] NVIDIA’s Next Generation CUDA Compute Architecture: Kepler TM GK110