Architecture - OpenDiabetes/OpenDiabetesVault-engine GitHub Wiki
The OpenDiabetesVault architecture follows a (gather,) import, process, export(, visualize) approach (illustrated by the figure below).
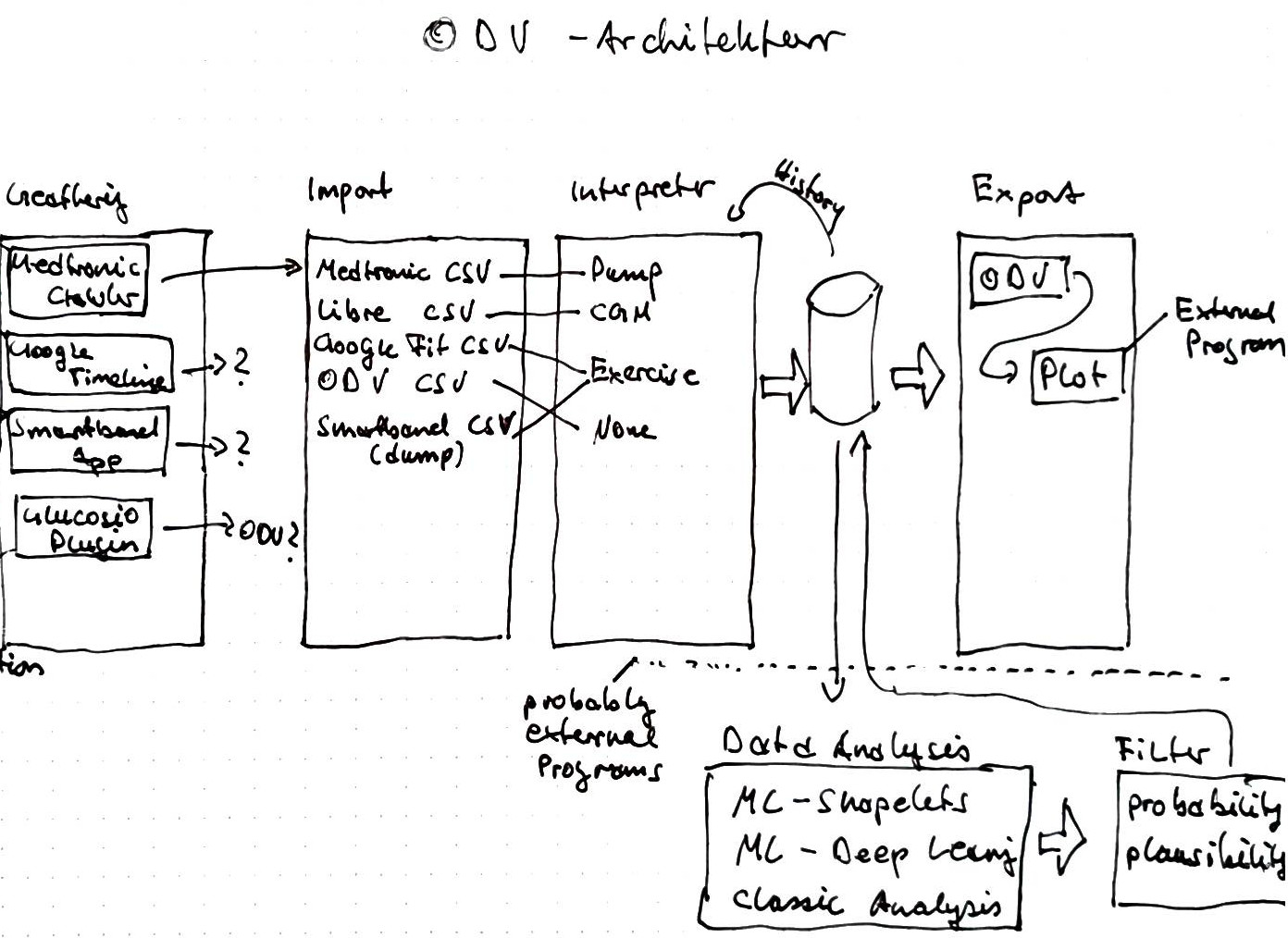
- Gather Data: Currently we are not able to geather data automatically.
- Import Data: Currently we support several devices for data import: Medtronic CSV, Freestyle Libre CSV, Google Fit CSV, Sony Smartband 3 SWT12 database dumps. Every importer works in two stages: parsing and interpretation. A parser reads values from one data point and converts it into the internal data format. The interpreter annotates data points and does very basic filtering on a data series. It also adds semantic implications (e.g. when a pump suspend is read, the interpreter would add a basal value 0).
- Process Data: Currently we have no data processing implemented.
- Export Data: Data can be exported to our csv data format. Also, a compressed (deflate) and signed format is available ".odv" (it's basically a zip archive with the csv file and signature file). Furthermore slicing (produced by the DataSlicer) information can be exported as csv for our plotting script.
- Visualize Data: The odv-CSV data can be visualized by our plotting script using matplotlib (separate project).