Apache Kafka - OpenData-tu/documentation GitHub Wiki
| Version | Date | Name | Changes |
|---|---|---|---|
| 0.1 | 2017-05-20 | Oliver Bruski | Initial Version |
| 0.2 | 2017-05-28 | Oliver Bruski | added definitions of components + some general description |
| 0.3 | 2017-07-02 | Oliver Bruski | added part about partitioning and bootstrapping |
Apache Zookeeper
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. ZooKeeper aims at distilling the essence of these different services into a very simple interface to a centralized coordination service. The service itself is distributed and highly reliable. Consensus, group management, and presence protocols will be implemented by the service so that the applications do not need to implement them on their own. For more go to Apache Zookeeper.
Run a replicated Zookeeper Quorum
Running ZooKeeper in standalone mode is convenient for evaluation, some development, and testing. But in production, you should run ZooKeeper in replicated mode. A replicated group of servers in the same application is called a quorum, and in replicated mode, all servers in the quorum have copies of the same configuration file. The file is similar to the one used in standalone mode, but with a few differences. Here is an example:
tickTime=2000
dataDir=/var/zookeeper
clientPort=2181
clientPortAddress=localhost
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
The new entry, initLimit is timeouts ZooKeeper uses to limit the length of time the ZooKeeper servers in quorum have to connect to a leader. The entry syncLimit limits how far out of date a server can be from a leader. With both of these timeouts, you specify the unit of time using tickTime. In this example, the timeout for initLimit is 5 ticks at 2000 milleseconds a tick, or 10 seconds.
The dataDir entries gives the location where ooKeeper will store the in-memory database snapshots and, unless specified otherwise, the transaction log of updates to the database. clientPortAddress is the address (ipv4, ipv6 or hostname) to listen for client connections; that is, the address that clients attempt to connect to. This is optional, by default we bind in such a way that any connection to the clientPort for any address/interface/nic on the server will be accepted.
The entries of the form server.X list the servers that make up the ZooKeeper service. When the server starts up, it knows which server it is by looking for the file myid in the data directory. That file has the contains the server number, in ASCII.
Finally, note the two port numbers after each server name: " 2888" and "3888". Peers use the former port to connect to other peers. Such a connection is necessary so that peers can communicate, for example, to agree upon the order of updates. More specifically, a ZooKeeper server uses this port to connect followers to the leader. When a new leader arises, a follower opens a TCP connection to the leader using this port. Because the default leader election also uses TCP, we currently require another port for leader election. This is the second port in the server entry.
Apache Kafka
For more detailed information go to Apache Kafka or Kafka Benchmark
Download at: https://www.apache.org/dyn/closer.cgi?path=/kafka/0.10.2.1/kafka-0.10.2.1-src.tgz
Apache Kafka is a distributed streaming platform. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a "massively scalable pub/sub message queue architected as a distributed transaction log, making it highly valuable for enterprise infrastructures to process streaming data. Additionally, Kafka connects to external systems (for data import/export) via Kafka Connect and provides Kafka Streams, a Java stream processing library.
- It lets you publish and subscribe to streams of records. In this respect it is similar to a message queue or enterprise messaging system.
- It lets you store streams of records in a fault-tolerant way.
- It lets you process streams of records as they occur.
It gets used for two broad classes of application:
- Building real-time streaming data pipelines that reliably get data between systems or applications
- Building real-time streaming applications that transform or react to the streams of data
Kafka is designed for distributed high throughput systems. Kafka has better throughput, built-in partitioning, replication and inherent fault-tolerance, which makes it a good fit for large-scale message processing applications. Apache Kafka is responsible for transferring data from one application to another, so the applications - importer and database writer - can focus on data, but not worry about how to share it. Kafka is a publish-subscribe broker. Consumers can subscribe to one or more topic and consume all the messages in that topic. In the Publish-Subscribe system, message producers are called publishers and message consumers are called subscribers. Apache Kafka is a distributed publish-subscribe messaging system and a robust queue that can handle a high volume of data and enables you to pass messages from one end-point to another. Apache Kafka is a distributed publish-subscribe messaging system and a robust queue that can handle a high volume of data and enables you to pass messages from one end-point to another. Kafka is built on top of the ZooKeeper synchronization service. Kafka supports low latency message delivery and gives guarantee for fault tolerance in the presence of machine failures. It has the ability to handle a large number of diverse consumers. Kafka is very fast, performs 2 million writes/sec. Kafka persists all data to the disk, which essentially means that all the writes go to the page cache of the OS (RAM). This makes it very efficient to transfer data from page cache to a network socket. In the above diagram, a topic is configured into three partitions. Partition 1 has two offset factors 0 and 1. Partition 2 has four offset factors 0, 1, 2, and 3. Partition 3 has one offset factor 0. The id of the replica is same as the id of the server that hosts it. Assume, if the replication factor of the topic is set to 3, then Kafka will create 3 identical replicas of each partition and place them in the cluster to make available for all its operations. To balance a load in cluster, each broker stores one or more of those partitions. Multiple producers and consumers can publish and retrieve messages at the same time.
Definitions and components
Topics
A stream of messages belonging to a particular category is called a topic. Data is stored in topics. Topics are split into partitions. For each topic, Kafka keeps a mini-mum of one partition. Each such partition contains messages in an immutable ordered sequence. A partition is implemented as a set of segment files of equal sizes.
Partition
Topics may have many partitions, so it can handle an arbitrary amount of data.
Partition offset
Each partitioned message has a unique sequence id called as "offset".
Replicas of partition
Replicas are nothing but "backups" of a partition. Replicas are never read or write data. They are used to prevent data loss.
Brokers
Brokers are simple system responsible for maintaining the published data. Each broker may have zero or more partitions per topic. Assume, if there are N partitions in a topic and N number of brokers, each broker will have one partition. Assume if there are N partitions in a topic and more than N brokers (n + m), the first N broker will have one partition and the next M broker will not have any partition for that particular topic. Assume if there are N partitions in a topic and less than N brokers (n-m), each broker will have one or more partition sharing among them. This scenario is not recommended due to unequal load distribution among the broker.
Each broker holds a number of partitions and each of these partitions can be either a leader or a replica for a topic. All writes and reads to a topic go through the leader and the leader coordinates updating replicas with new data. If a leader fails, a replica takes over as the new leader.
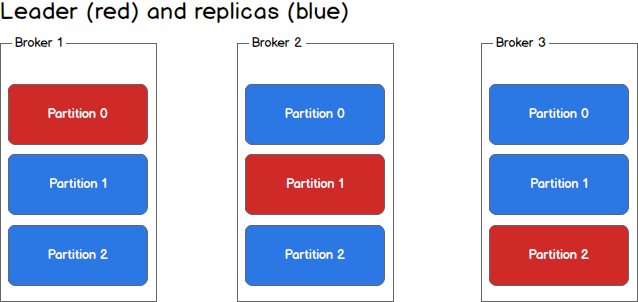
Kafla Cluster
Kafka’s having more than one broker are called as Kafka cluster. A Kafka cluster can be expanded without downtime. These clusters are used to manage the persistence and replication of message data.
Producers
Producers are the publisher of messages to one or more Kafka topics. Producers send data to Kafka brokers. Every time a producer pub-lishes a message to a broker, the broker simply appends the message to the last segment file. Actually, the message will be appended to a partition. Producer can also send messages to a partition of their choice.
Consumers
Consumers read data from brokers. Consumers subscribes to one or more topics and consume published messages by pulling data from the brokers.
Topics and Logs
Let's first dive into the core abstraction Kafka provides for a stream of records — the topic. A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it. For each topic, the Kafka cluster maintains a partitioned log that looks like this:
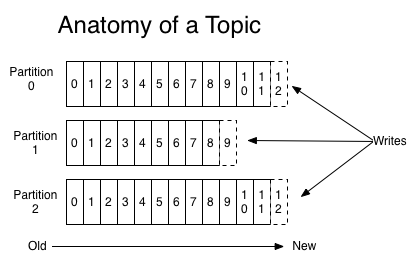
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
The Kafka cluster retains all published records—whether or not they have been consumed—using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka's performance is effectively constant with respect to data size so storing data for a long time is not a problem.
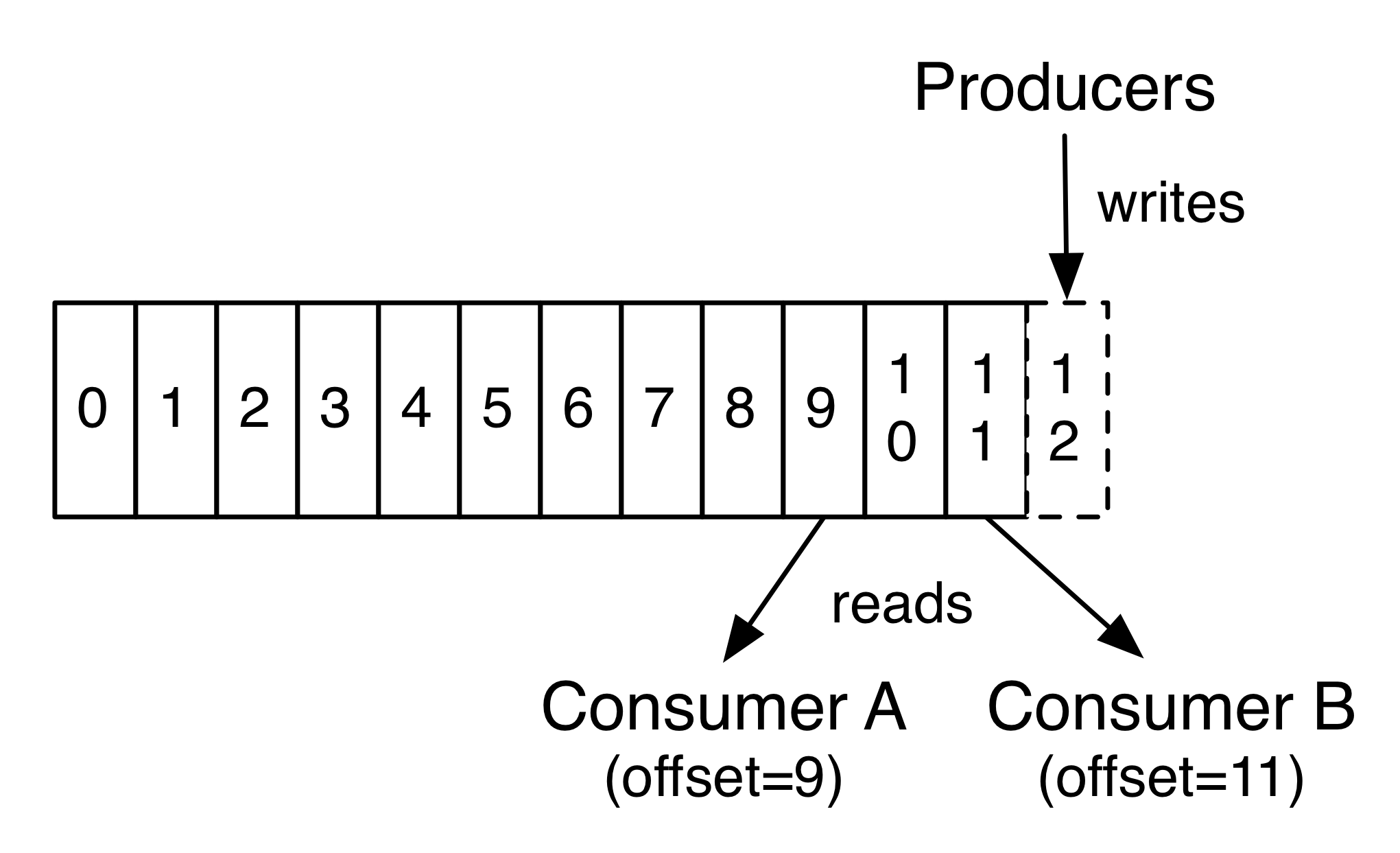
In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from "now".
This combination of features means that Kafka consumers are very cheap—they can come and go without much impact on the cluster or on other consumers. For example, you can use our command line tools to "tail" the contents of any topic without changing what is consumed by any existing consumers.
The partitions in the log serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Second they act as the unit of parallelism—more on that in a bit.
Partitioning and bootstrapping
Kafka is a partitioned system so not all servers have the complete data set. Instead recall that topics are split into a pre-defined number of partitions, P, and each partition is replicated with some replication factor, N. Topic partitions themselves are just ordered "commit logs" numbered 0, 1, ..., P.
All systems of this nature have the question of how a particular piece of data is assigned to a particular partition. Kafka clients directly control this assignment, the brokers themselves enforce no particular semantics of which messages should be published to a particular partition. Rather, to publish messages the client directly addresses messages to a particular partition, and when fetching messages, fetches from a particular partition. If two clients want to use the same partitioning scheme they must use the same method to compute the mapping of key to partition.
These requests to publish or fetch data must be sent to the broker that is currently acting as the leader for a given partition. This condition is enforced by the broker, so a request for a particular partition to the wrong broker will result in an the NotLeaderForPartition error code (described below).
How can the client find out which topics exist, what partitions they have, and which brokers currently host those partitions so that it can direct its requests to the right hosts? This information is dynamic, so you can't just configure each client with some static mapping file. Instead all Kafka brokers can answer a metadata request that describes the current state of the cluster: what topics there are, which partitions those topics have, which broker is the leader for those partitions, and the host and port information for these brokers.
In other words, the client needs to somehow find one broker and that broker will tell the client about all the other brokers that exist and what partitions they host. This first broker may itself go down so the best practice for a client implementation is to take a list of two or three urls to bootstrap from. The user can then choose to use a load balancer or just statically configure two or three of their kafka hosts in the clients.
The client does not need to keep polling to see if the cluster has changed; it can fetch metadata once when it is instantiated cache that metadata until it receives an error indicating that the metadata is out of date. This error can come in two forms: (1) a socket error indicating the client cannot communicate with a particular broker, (2) an error code in the response to a request indicating that this broker no longer hosts the partition for which data was requested. Cycle through a list of "bootstrap" kafka urls until we find one we can connect to. Fetch cluster metadata. Process fetch or produce requests, directing them to the appropriate broker based on the topic/partitions they send to or fetch from. If we get an appropriate error, refresh the metadata and try again.
Partitioning Strategies
As mentioned above the assignment of messages to partitions is something the producing client controls. That said, how should this functionality be exposed to the end-user?
Partitioning really serves two purposes in Kafka:
- It balances data and request load over brokers
- It serves as a way to divvy up processing among consumer processes while allowing local state and preserving order within the partition. We call this semantic partitioning.
For a given use case you may care about only one of these or both.
To accomplish simple load balancing a simple approach would be for the client to just round robin requests over all brokers. Another alternative, in an environment where there are many more producers than brokers, would be to have each client chose a single partition at random and publish to that. This later strategy will result in far fewer TCP connections.
Semantic partitioning means using some key in the message to assign messages to partitions. For example if you were processing a click message stream you might want to partition the stream by the user id so that all data for a particular user would go to a single consumer. To accomplish this the client can take a key associated with the message and use some hash of this key to choose the partition to which to deliver the message.
Create a local kafka instance
Download and untar the downloaded kafka folder and navigate to the bin folder. Start zookeeper first and thereafter the kafka instance.
Start zookeeper
zookeeper/bin/zookeeper-server-start.sh config/zookeeper.properties
Start kafka
kafka/bin/kafka-server-start.sh config/server.properties
2.Use the spotify docker for kafka
Start zookeeper and kafka
docker run -p 2181:2181 -p 9092:9092 --env ADVERTISED_HOST=`docker-machine ip \`docker-machine active\`` --env ADVERTISED_PORT=9092 spotify/kafka
Start a producer and send messages
export KAFKA=`docker-machine ip \`docker-machine active\``:9092 kafka-console-producer.sh --broker-list $KAFKA --topic test
Start a consumer and read messages
export ZOOKEEPER=`docker-machine ip \`docker-machine active\``:2181 kafka-console-consumer.sh --zookeeper $ZOOKEEPER --topic test
Start using kafka in the console
List all topics
/bin/kafka-topics.sh --zookeeper {zookeeper ip}:{zookeeper port} --list
/bin/kafka-topics.sh --zookeeper 54.93.86.196:2181 --list
Create a topic
/bin/kafka-topics.sh --create --zookeeper {zookeeper ip}:{zookeeper port} --replication-factor N --partitions N --topic topicName
/bin/kafka-topics.sh --create --zookeeper 54.93.86.196:2181 --replication-factor 1 --partitions 1 --topic testTopic
Start a producer and create messages
/bin/kafka-console-producer.sh --broker-list {kafka-server ip}:{kafka port} --topic topicName
/bin/kafka-console-producer.sh --broker-list 54.93.86.196:9092 --topic testTopic
Start a consumer and read all messages of a topic
/bin/kafka-console-consumer.sh --zookeeper {zookeeper ip}:{zookeeper port} --topic topicName [--from-beginning]
/bin/kafka-console-consumer.sh --zookeeper 54.93.86.196:2181 --topic testTopic --from-beginning
/bin/kafka-console-consumer.sh --zookeeper 54.93.86.196:2181 --topic testTopic
Using the Java API
TODO
How make kafka reachable on AWS
To connect to Kafka and Zookeeper from a different machine, you must open ports 9092 and 2181 for remote access. On an AWS hosted Kafka instance enter the EC2 Dashboard. Go to Network & Security and to Security Groups. Here pick the Security Group assigned to the EC2 instance running Kafka. In the Inbound tab check for the open ports and allowed source IP addresses. Add the ports 9092 and 2181 if necessary.
Change of config files
In /kafka/config/server.properties add or edit the entry about listeners to listeners=PLAINTEXT://:9092. Second possibility is to declare a specific IP-address for example listeners=PLAINTEXT://host IP:9092. In case Zookeeper is running on a different machine you have to edit the zookeeper.connect entry to
zookeeper.connect=zookeeper-ip:2181
In the Zookeeper folder go to /zookeeper/conf/zoo.cfg. The following entry gives you the port where the clients have to connect. The default value of 2181 should work best.
# the port at which the clients will connect
clientPort=2181
Further comment out the following line using a # to eliminate the restriction to localhost clients!
#clientPortAddress=localhost
Using this configuration you will be able to access your kafka service from a different machine and IP than localhost.