Class Activity 3.1 DNS Enumeration - Oliver-Mustoe/Oliver-Mustoe-Tech-Journal GitHub Wiki
In the activity, we learned about DNS, and the treasure trove of information it can provide (hostnames, naming conventions, namespaces.)
Notes
First I modified my portscanner.sh script to repeat the scan over a inputted network prefix (assuming /24 netid) targeting a specific TCP port (in this case associated with DNS.)
Below is the script (and a picture of a test run), Link to source ('portscanner2')
#!/bin/bash
# Author: Oliver Mustoe
# Check if 2 parameters are inputted
if [ -n $1 ](/Oliver-Mustoe/Oliver-Mustoe-Tech-Journal/wiki/--n-$1-) && [ -n $2 ](/Oliver-Mustoe/Oliver-Mustoe-Tech-Journal/wiki/--n-$2-); then
# Read input for whether to make .csv or not
read -p "Would you like to export this as a .csv?[y/N] " FileOrNo
# Make that input uppercase
FileOrNoUP=${FileOrNo^^}
# If .csv yes, echo certain results to console and screen
if [ $FileOrNoUP == "Y" ]] ](/Oliver-Mustoe/Oliver-Mustoe-Tech-Journal/wiki/|-[[-$FileOrNoUP-==-"YES"-); then
echo "Saving result to 'Scanresult.csv'"
echo "host,port" >> Scanresult.csv
fi
# Assign input into variables
hostprefix=$1
port=$2
for prefix in $(seq 1 254); do
# Assign the host variable to the host prefix with prefix
host=$hostprefix.$prefix
timeout .1 bash -c "echo >/dev/tcp/$host/$port" 2>/dev/null && # && is important here to keep errors away from data
# Echo the port if above command is successful
echo "
HOST: $hostprefix.$prefix
OPEN PORT: $port" &&
# Append to file if above command is successful
# if .csv yes, echo host and port in csv format to file
if [ $FileOrNoUP == "Y" ]] ](/Oliver-Mustoe/Oliver-Mustoe-Tech-Journal/wiki/|-[[-$FileOrNoUP-==-"YES"-); then
echo "$host,$port" >> Scanresult.csv
fi
done # End of prefix loop
echo "DONE"
else
echo "Need 2 inputs; current inputs are $1 and $2"
fi # End of if for parameters
# Sources Used:
# https://stackoverflow.com/questions/14840953/how-to-remove-a-character-at-the-end-of-each-line-in-unix
# https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays
# https://linuxhint.com/bash_append_array/
# https://linuxhint.com/bash_lowercase_uppercase_strings/
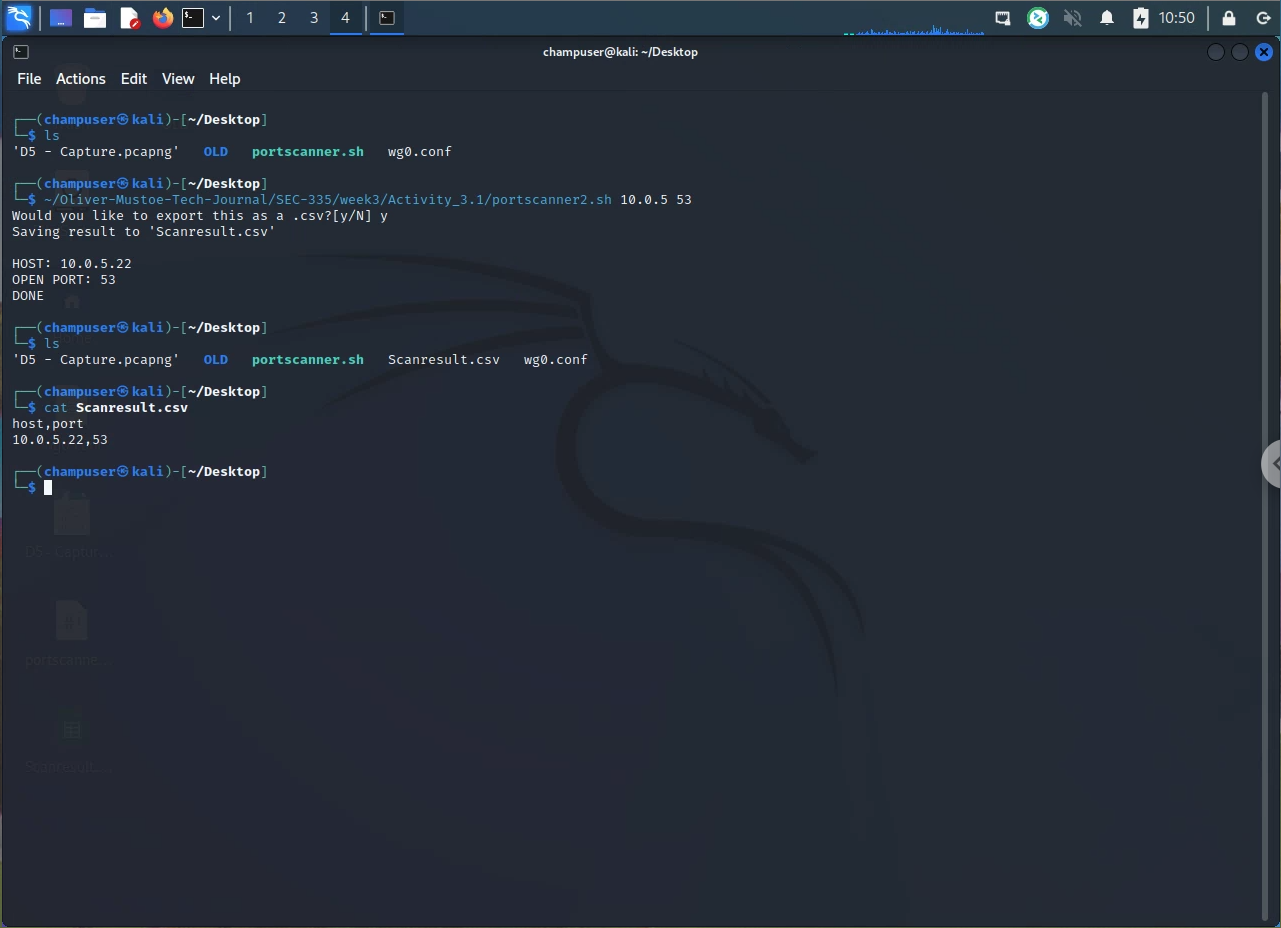
(NOTE: Make sure to keep up file structure found in SEC-335)
I then wrote a script to take a network prefix and a specific DNS server and performs a lookup (assumption network is /24):
Below is the script (and a picture of a test run), Link to source ('dns-resolver')
#!/bin/bash
netprefix=$1
dns_server=$2
# Check if variables are empty
if [ -n $netprefix ](/Oliver-Mustoe/Oliver-Mustoe-Tech-Journal/wiki/--n-$netprefix-) && [ -n $dns_server ](/Oliver-Mustoe/Oliver-Mustoe-Tech-Journal/wiki/--n-$dns_server-); then
echo "DNS resolution for $netprefix"
# For every number between 1-254
for prefix in $(seq 1 254); do
# nslookup for variables combined to IP, throw errors in /dev/nul
nslookup $netprefix.$prefix $dns_server 2>/dev/null | egrep '^[:digit:](/Oliver-Mustoe/Oliver-Mustoe-Tech-Journal/wiki/:digit:)' # Checks if digit starts line
done # end of prefix loop
echo "
DONE"
else
echo "NEED 2 INPUTS, CURRENT INPUTS ARE: $1 and $2!"
fi # end of non-zero check
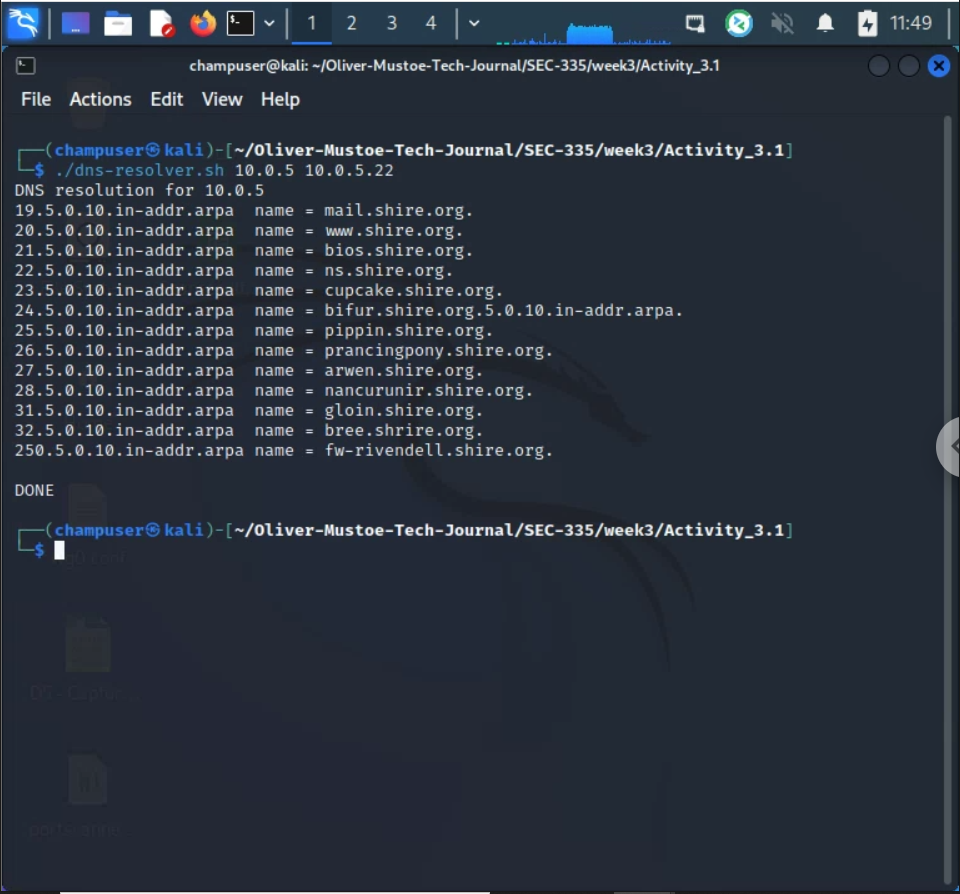
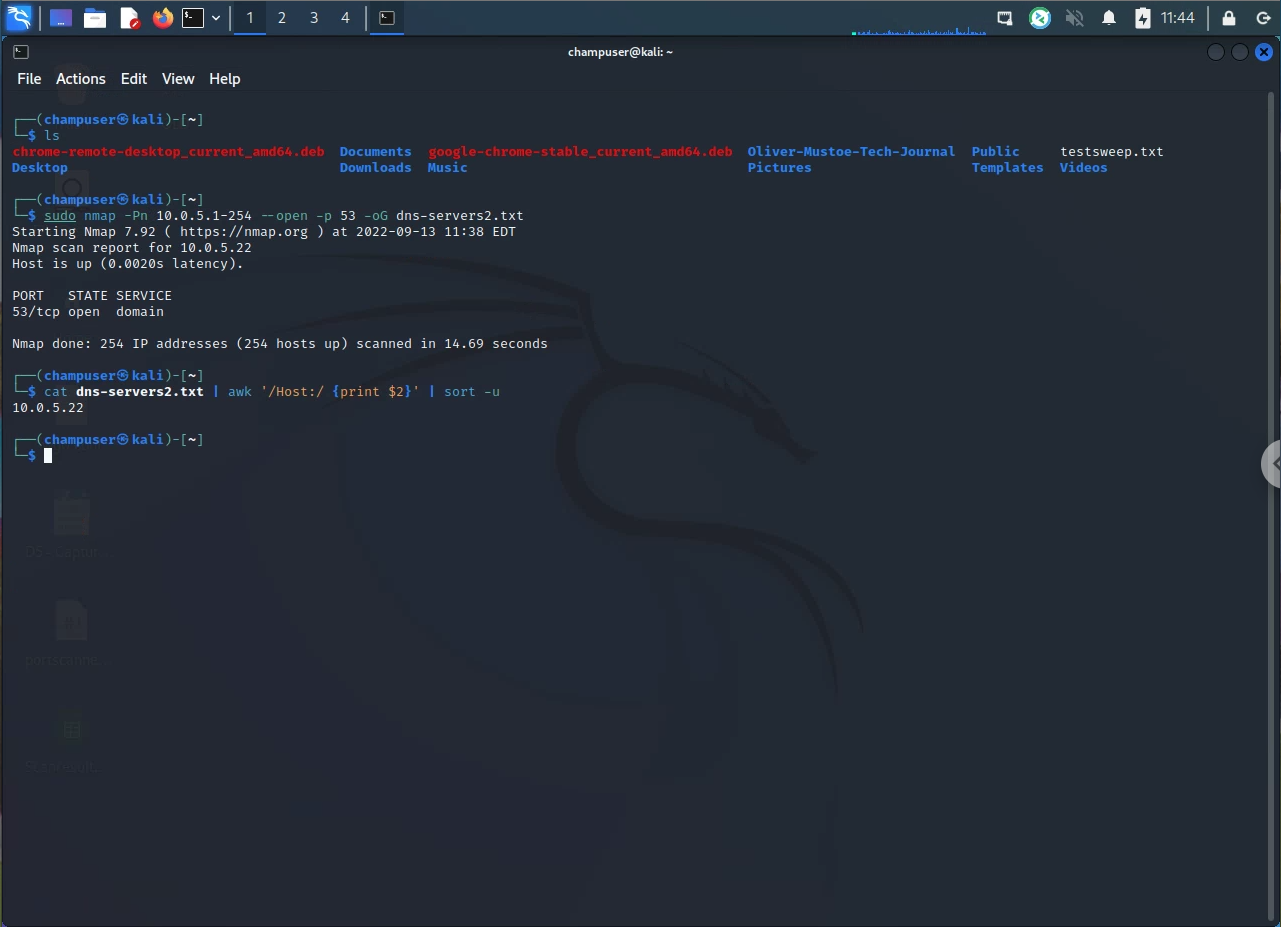
I then used nmap to find my DNS servers with the command:
sudo nmap -Pn 10.0.5.1-254 --open -p 53 -oG dns-servers2.txt-
- further breakdown of one-liner can be found in the Dedicated NMAP commands and techniques page
This generates a file, "dns-servers2.txt", which I parsed with the following command:
cat dns-servers2.txt | awk '/Host:/ {print $2}' | sort -u-
- Open file,
cat, and pipe that into awk to look for the line with "Host:",/Host:/, and print the 2nd field, whitespace delimited, then use sort with the unique,-u, flag.
- Open file,
Example of above:
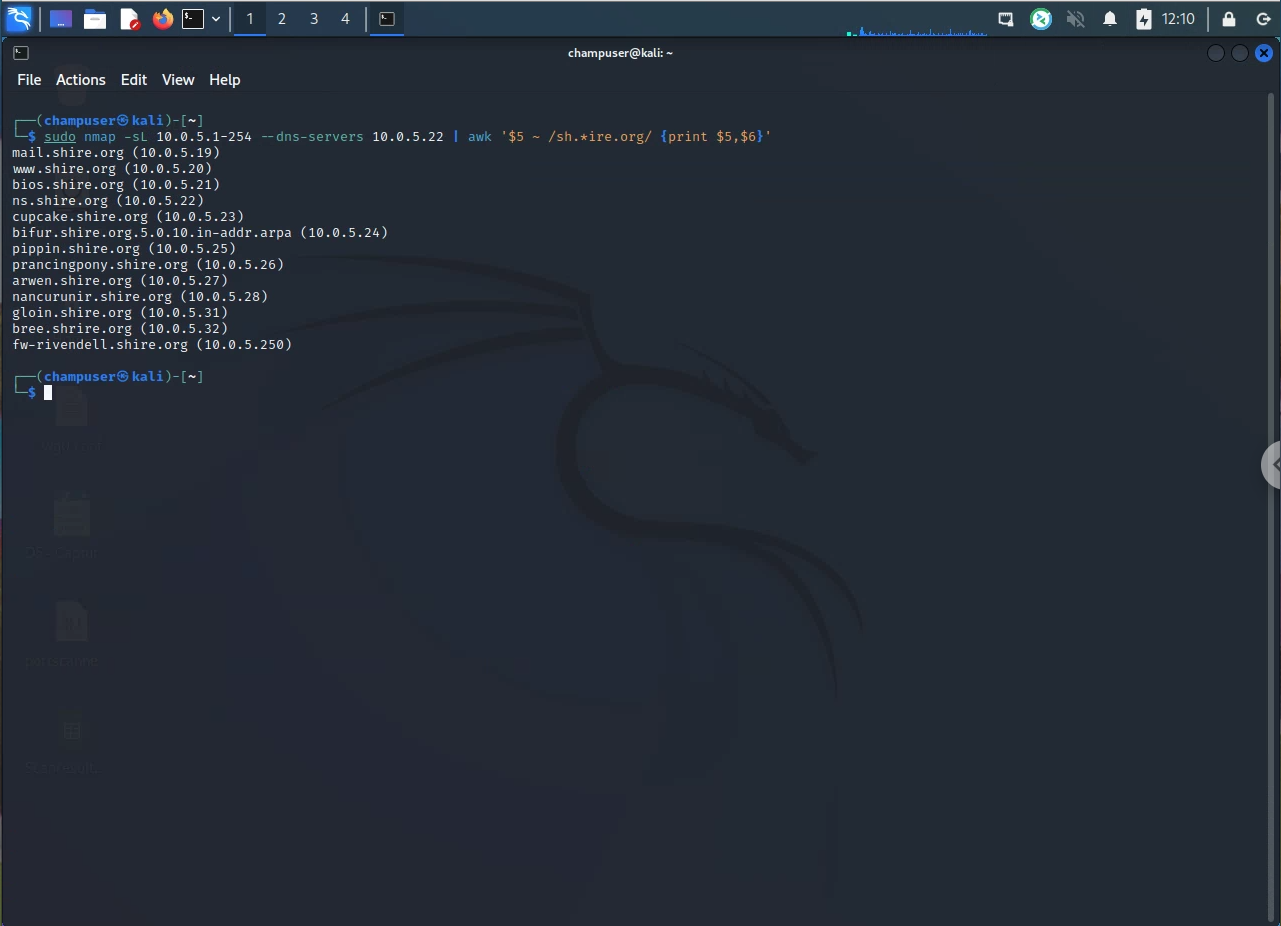
Afterwards, I ran the following one liner to list targets while specifying a dns server:
sudo nmap -sL 10.0.5.1-254 --dns-servers 10.0.5.22 | awk '$5 ~ /sh.*ire.org/ {print $5,$6}'-
- Explanations of the nmap command (flags) can be found in the Dedicated NMAP commands and techniques page
-
- The nmap command is piped into awk and it uses regex to match,
~, field 5, delimited by space, and if the field contains “shire.org” with anything between the "h" and the "i",/sh.*ire.org/, prints field 5 and 6,{print $5,$6}.
- The nmap command is piped into awk and it uses regex to match,
Example of above:
Then after attempting zone transfer of 2 intentionally weak DNS servers (commands are dig axfr @nsztm1.digi.ninja zonetransfer.me > zt.txt and dig axfr @nsztm2.digi.ninja zonetransfer.me >> zt.txt) I parsed them using the following one-liner:
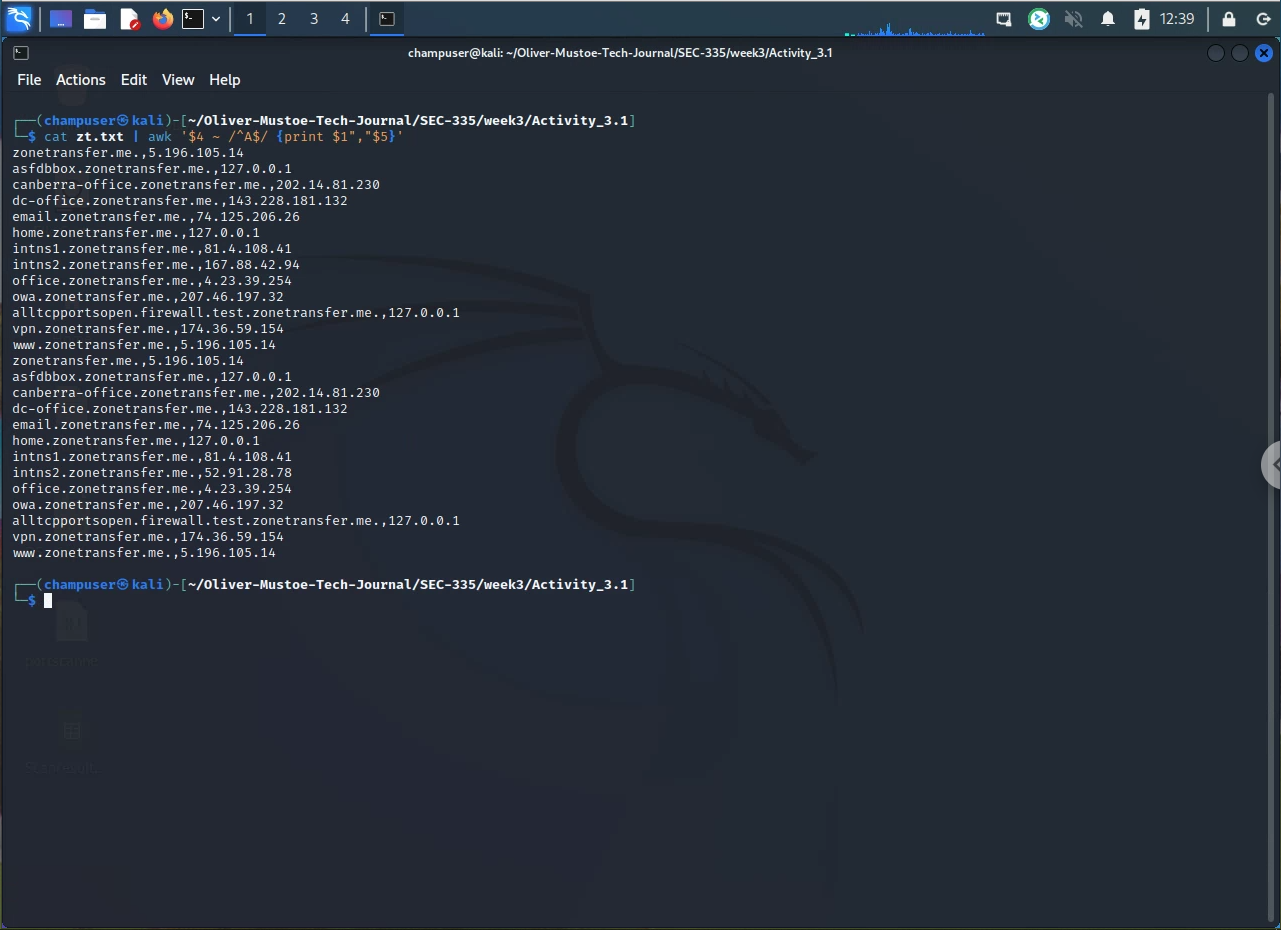
cat zt.txt | awk '$4 ~ /^A$/ {print $1","$5}'-
- Open zt.txt,
cat, and pipe it into awk and use regex to match,~, field 4, delimited by space, and if the field begins and ends with A,/^A$/, then print field 1 comma field 5,{print $1","$5}.
- Open zt.txt,
Example of above:
Reflection
A major takeaway I have from this week is the power of text formatting. Using awk and grep can make information from recon SIGNIFICANTLY more readable and usable (maybe in a report?!?!) This week, I especially found awk with regex to be useful, as you see in the commands above, and may have a dedicated page for it's continued use in the future. In my free time, I also study a bit of regex, which was extremely helpful this week and I plan to keep it up! Error handling, particularly in bash, is not something I have dealt much with before, but with scans it is very helpful and I plan to keep exploring it.
Sources:
- https://linuxize.com/post/regular-expressions-in-grep/
- https://security.stackexchange.com/questions/227492/how-to-only-display-open-ports
- https://man7.org/linux/man-pages/man1/awk.1p.html
- https://www.gnu.org/software/gawk/manual/html_node/Regexp-Usage.html
- https://en.wikibooks.org/wiki/Regular_Expressions/POSIX_Basic_Regular_Expressions
- https://nmap.org/book/host-discovery-dns.html