Fetching the Google Website - LucPrestin/Hidden-Modularity GitHub Wiki
Description
One of the main features of Squeak are its capabilities to access network resource. Part of it is the WebClient class. It offers an interface to make different http request to web resources. We chose to trace an http get request in its construction, postulation and result parsing. Here we have examined two different manifestations. On the one hand, we simply make the request and receive the response. On the other hand, we also access the content of the response.
Fetching With Content Access
Code
(WebClient httpGet: 'https://google.com') content
Hypotheses
- The WebClient plays a comparatively small role, as it only needs to create a request object and send it
- The WebRequest is the central part of this trace. It should encapsulate the request generation, result parsing and so on
- String parsing should be a big cluster as well
Evaluation
Graphs
Communication Graphs
 |
 |
|---|---|
| node size equal for all nodes | node size calculated by amount of incoming and outgoing edges |
 |
 |
| node size calculated by amount of incoming edges | node size calculated by amount of outgoing edges |
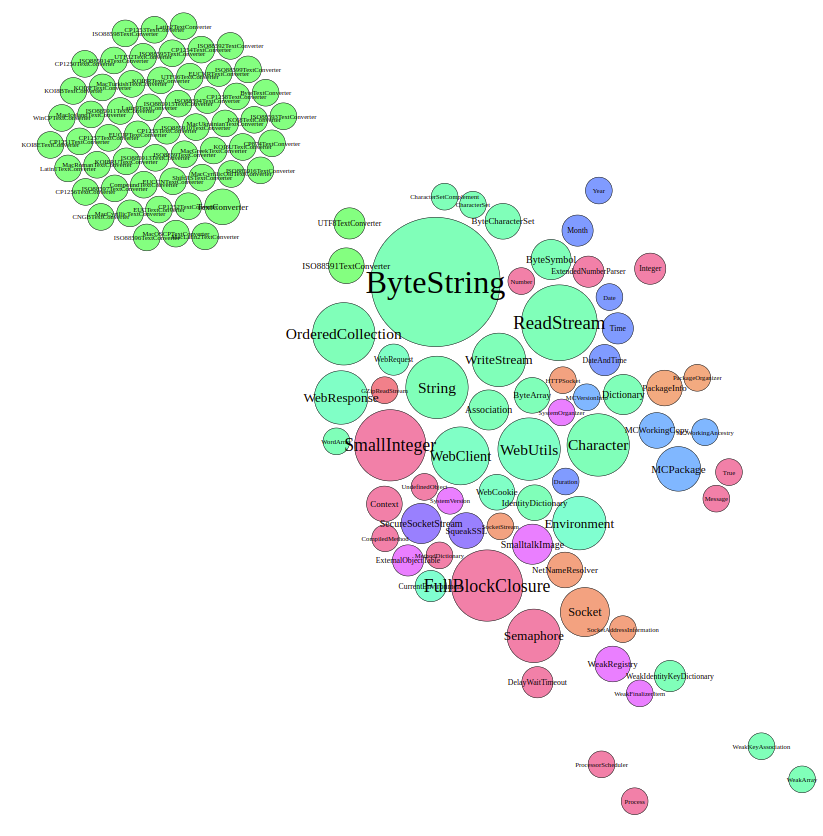
Hypothesis 1: The WebClient plays a small role
For this, we can have a look at the graph with node sized adjusted by the amount of incoming and outgoing edges.
 |
 |
 |
|---|---|---|
| Incoming Edges | Outgoing Edges | Incoming and Outgoing Edges |
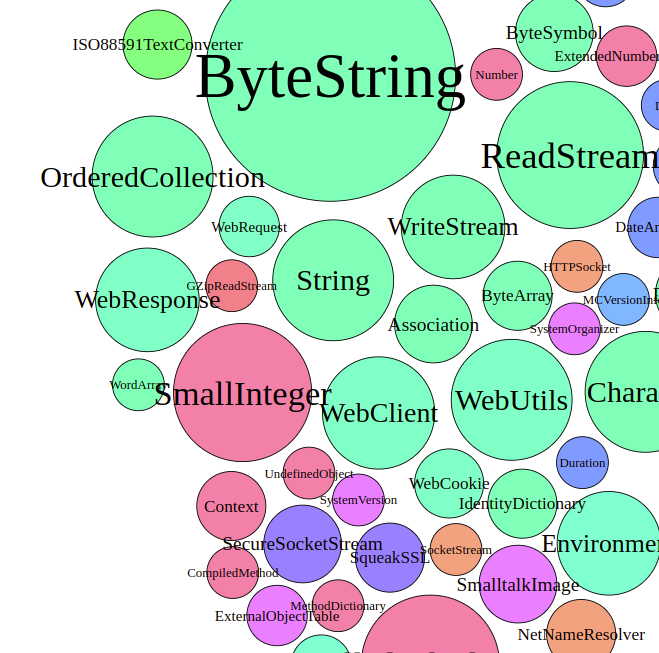
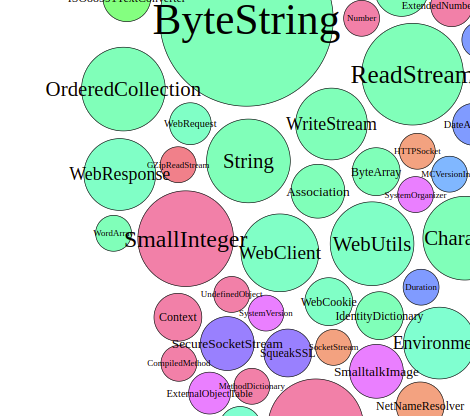
Interestingly, the WebClient seems to be as big as the WebResponse and bigger than the WebRequest. The way that these sizes are calculated suggests, that there were more method calls from and to the WebClient than the WebRequest. This indicates that the WebClient is in fact quite important and the Hypothesis is false.
Hypothesis 2: The WebRequest is the central part
For this, we can haave a look at the graph with node sized adjusted by the amount of incoming and outgoing edges.
|
|
|
|---|---|---|
| Incoming Edges | Outgoing Edges | Incoming and Outgoing Edges |
Interestingly, the WebRequest is comparatively small in each of these graphs. This suggests that it actually does less than the WebClient or WebResponse.
An explanation for why the WebRequest is smaller than the WebResponse is that the Trace is not only about the request, but also the result parsing. A new trace without the result parsing should be made.
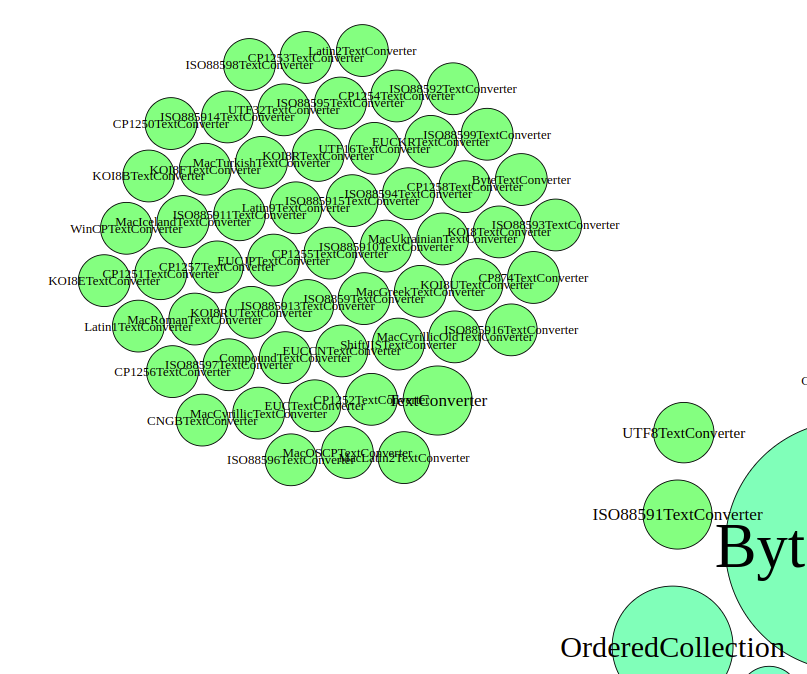
Hypothesis 3: String parsing is a big cluster
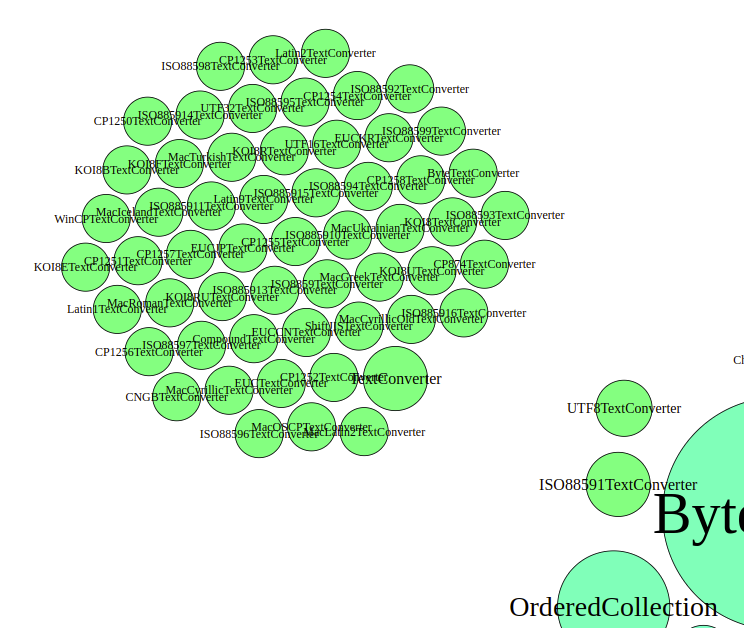
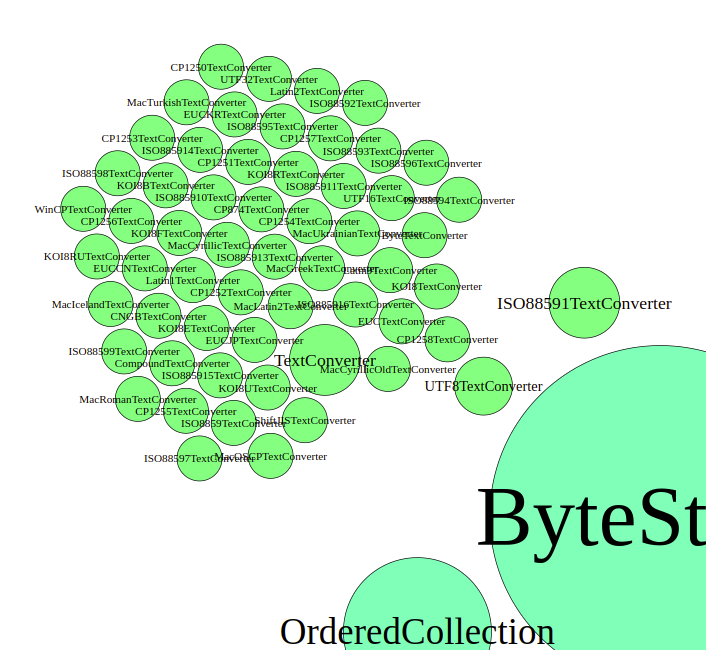
From the general graph above, we can see that many different Text converters are part of the communication. But it does not show, how much they actually communicate. For this, we can use a graph that calculates the node sizes by incoming, outgoing, or both kind of edges.
 |
 |
 |
|---|---|---|
| Incoming Edges | Outgoing Edges | Incoming and Outgoing Edges |
We can see, that most text converter subclasses stay at the same size. Only the super class TextConverter, the UTF8TextConverter, and the ISO88591TextConverter are drawn larger, which suggests that only those actually play some role in the scenario. As the incoming and outgoing edges based graphs look similar, it seems as if those three really are communicating and the rest not.
When looking at the code, this is also what we can see there. When building the content string, the WebResponse asks the TextConverter class for a new converter specialized for its encoding. The TextConverter class object then iterates over all its subclasses to ask them whether they can handle that encoding. The first one that answers that it can is then used for the actual conversion. This can also be seen when drawing the edges of the graph. This time, all edges are taken into account for the node size calculation.
The converters that are actually used thus seem to be the UTF8TextConverter and the ISO88591TextConverter. To check on that, we can also adjust the node sizes for the edge weights. When doing this, the image spreads more apart. The ISO88591TextConverter is arranged in the middle of the other classes, whereas the UTF8TextConverter hard to even be found.
Thus, we conclude that of the text converters, only the ISO88591TextConverter is used and that to a substancial part.
Further insights (optionally)
Fetching Without Content Access
Code
(WebClient httpGet: 'https://google.com')
Hypotheses
We assume that the response's body gets lazily parsed at access. Therefore Classes that to string parsing should be less relevant than in the other manifestation. The rest should be about the same.
Evaluation
The layouted graph now looks like this (node size adjusted by incoming and outgoing edges):
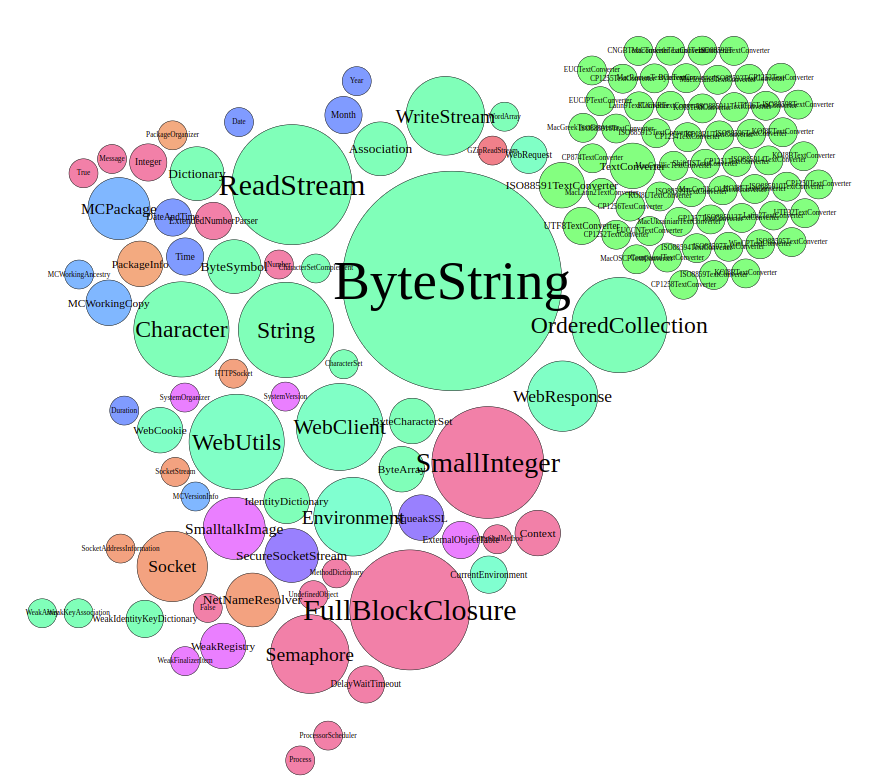
The change in layout suggests that there actually is a difference between the two scenarios. But all the TextConverter classes are still here, probably because at least the header needs to be parsed anyways. Just from looking at the bubble sizes, we cannot say whether the TextConverters are used more or less. Here, a way to substract the two graphs and compare the difference would be handy. For an idea on how to achieve this, have a look at issue #62.