[Chapter 7] 过拟合优化: 正则化Regularization - Linjiayu6/Machine-Learning-Practice GitHub Wiki
对过拟合问题的优化, 分别着眼于线性回归和逻辑回归
- 为什么会出现过拟合问题? 如何优化? 解决什么问题?
- 优化后cost function 会变成如何? 下降梯度变化如何? 导数又如何变化?
规则化就是...向你的模型加入某些规则,加入先验,缩小解空间,减小求出错误解的可能性。
7.1 过拟合的问题
- 我们创建模型的时候, 会出现underfitting 或 overfitting的情况
- **多项式次幂约高, 拟合测试数据越好**, 但是预测功能越差.
- 如何control这种情况?
7.2 代价函数 - 如何优化cost function
- 通过例子理解为什么修改代价函数
- 代价函数修改成什么样子呢? 为啥修改代价函数? (1) 代价函数最小 (2) $\theta$值最小 (3) $\lambda$ 又是什么作用?
7.3 正则化线性回归 - 针对cost function的优化, $\theta$是如何变化?
- **优化后: 对于每一个$\theta$是如何变化的**
7.4 正则化逻辑回归
- 同理和线性回归是差不多的
$\theta$的值就是为了多项式, 拟合数据用的
7.1 过拟合的问题
The Problem of Overfitting
7.1.1 例子I
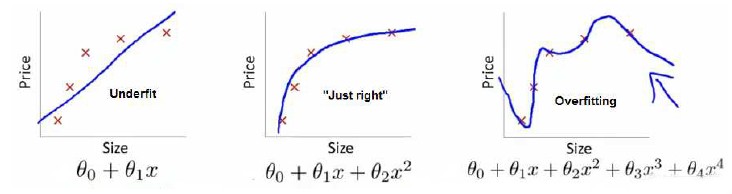 例子是在说
(1) 第一个图, 拟合程度不好
underfit = high bias
例子是在说
(1) 第一个图, 拟合程度不好
underfit = high bias
(2) 第三个图, 四次方的模型, 过于强调拟合原始数据, 丢失算法的本质, 这样是不能很好的预测数据的。 overfit = high variance 如果我们有很多features, 是非常容易过拟合的。
(3) 中间的图看起来是比较合适的
7.1.2 例子II

- 左图: underfitting
- 右图: overfitting
7.1.3 如何解决过拟合?
(1)多项式的次幂约高, 拟合越好 - 但同时会存在预测能力越差
(1.5) 多项式阶次不能很好的解决问题, 如果你有100个 features(即x)-很多变量的模型, 是很难用多项式阶次解决问题的。
(2) 如何解决overfit 的问题呢?
-
减少features 数量 (2.1) 100个features, 肯定有不需要的吧, 人工manually 检出. (2.2) 后续会讲到 模型选择算法
-
Regularization 正则化(2.3) features保留(即使有100个), 减少parameters $\theta$ 的值
7.2 代价函数
Cost Function
7.2.1 例子说问题

图:
- 左边的图是刚刚好的例子, 右图是: overfitting. 原因是右侧的次幂项太高了, 导致, 过度拟合了训练的数据, 无法很好地做好预测功能。
线性回归求解代价函数的公式:
J(\theta) = 1/2m \displaystyle\sum_{i=1}^n Cost(h_\theta(x^{(i)}), y^{(i)}))
Cost(h_\theta(x^{(i)}), y^{(i)})) = (h_\theta(x^{(i)}) - y^{(i)}) ^2
目标: $min(J(\theta)) = 0$
变个思路想
- 我们将$(J(\theta))$后加入 $1000\theta_3^2 + 1000\theta_4^2$
- 如何让$(J(\theta))$最小, 肯定是让新加入的 $1000\theta_3^2 + 1000\theta_4^2$ 这个部分也是接近于0了。
- 也就是说 $\theta_3, \theta_4 \approx 0$
- 这不也就是相当于没有了$\theta_3, \theta_4$ 约等于 左图的公式
- 以一定的限制条件, 约束和控制features的数量。(让他们所占的权重都很小)
7.2.2 Regularization正则化
参考上面的例子
(1) 将 $\theta_0, \theta_1, \theta_2, ...$ small values
* 参数的值越小, 约能得到光滑的函数
* 也就是说: less prone to overfitting 不容易发生拟合问题
7.2.3 正则化例子
Features: $x_1, x_2, ...., x_{100}$ Parameters: $\theta_0, \theta_1, ...., \theta_{100}$
- 这里我们有100个特征值, 我们不知道, 哪个是关联度最小的特征
- 对于parameters, 我们也不知道该 缩小shrink 哪个参数$\theta$
我们需要做的就是: 根据上面的 ## 7.2.1 例子说问题 修改$J(\theta)$ 代价函数总表达式
7.2.4 修改cost function
$min(J(\theta))$

加入正则化项: 会让我们所有的参数都收缩(变小)
Regularization Term $= (1/2m) * \lambda\displaystyle\sum_{j=1}^n \theta_j^2$
这里注意: $\theta_0$是没有加入到上面公式里面的, $j=1$开始, $\theta_0$的值还是最大的- $\lambda$ 是正则化的参数: regularization parameter
- $\lambda$
是用来权衡关系的: - (1) 我们需要训练的数据需要适当的拟合函数
- (2) keep 保持$\theta$值 较小 (最小化各个参数)
说明
- 第一项 原cost function需要最小化
- 第二项 减少各个参数的值
- 由于不清楚是那些参数对应的是最高次项, 因此选择减少他们的平方和
- $\lambda$是控制平方和在新cost function的比重
$\lambda$值 太大的话:
- 如果$\lambda$ 过大: 那么所有的 $\theta_j \approx 0$ (j从1开始), 只剩下$y = \theta_0$ 是一条水平线, 显然不对
- 这种情况就是underfitting

你肯定有这样的疑问? 如何合理的取值$\lambda$?
7.3 正则化 - 线性回归(linear)
Regularized Linear Regression
7.3.1 $\theta$ 导数变化
(1) 线性回归 - 下降梯度运算

(2) $\theta_0$不变 从$\theta_1$开始, 代价函数要有所变化, 所以下降梯度变化如下

(3) 公式变化(就是个提取公共因素) - 最下面公式

- 除了这个部分外, $(1-\alpha \lambda / m)$ 其他部分均一样`
必要条件:
$(1-\alpha \lambda / m) < 1$
$(1-\alpha \lambda / m) < 1$
假如 $(1-\alpha \lambda / m) = 0.90$ 意味着每次$\theta_j$ 都比未变换前小一些, 更快收敛到最小值。
必要条件: $(1-\alpha \lambda / m) < 1$
因为前面的式子(左边一个粉色框), theta * 0.9, 那么theta在缩小, 后面的式子(右边一个粉色框和原来一样不变的).
加了L2正则, 整个式子说明, theta每次梯度下降在减少。

7.3.2 整体$\theta$变化公式

矩阵是 $(n+1) * (n+1)$ 说明: 有n个$\theta$ 从1到n, 再加上个$\theta_0$
7.4 正则化的 逻辑回归 (logistic)
Regularized Logistic Regression
之前, 针对逻辑回归, 使用梯度下降法来优化代价函数。

- g(....): sigmoid function
- 图上是过拟合的逻辑回归
 方块部分是, 逻辑回归 cost function 加入的正则化内容
方块部分是, 逻辑回归 cost function 加入的正则化内容
 下降梯度的公式和线性一样的, 唯一不同的是 $h_\theta(x)$ 是sigmoid function
下降梯度的公式和线性一样的, 唯一不同的是 $h_\theta(x)$ 是sigmoid function