Understanding V8’s Bytecode - Lee-hyuna/33-js-concepts-kr GitHub Wiki
Understanding V8’s Bytecode
번역 : https://medium.com/dailyjs/understanding-v8s-bytecode-317d46c94775
V8은 구글의 오픈소스 자바스크립트 엔진입니다. Chrome, Node.js, 그리고 많은 다른 어플리케이션들이 V8을 사용하고 있습니다. 이 글은 V8의 bytecode 형식에 대해서 설명합니다. 이건 아주 한번 읽어서 이해하기 쉬운 기본적인 컨셉입니다.

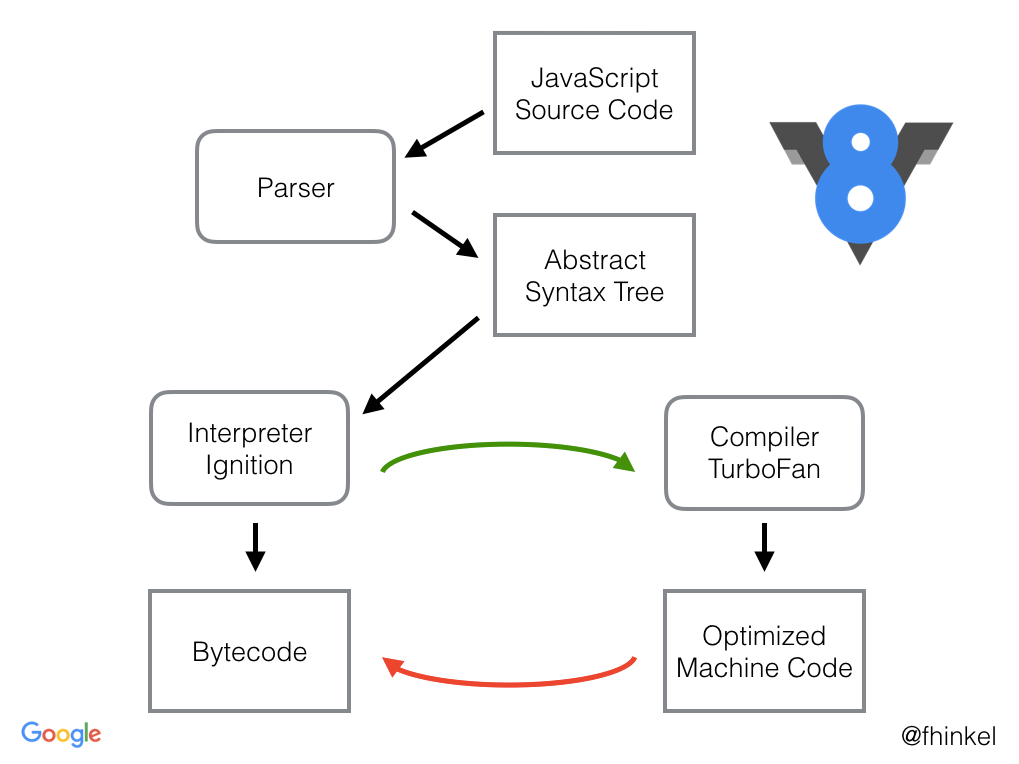
V8이 자바스크립트 코드를 컴파일 할때, parser는 추상적인 문법 트리를 생성합니다. 이 문법트리는 자바스크립트의 문법구조의 트리를 나타냅니다. Ignition(the interpreter) 해석기 는 이 문법 트리로부터 바이트 코드를 생성합니다. TurboFan (the optimizing compiler)컴파일러는 결국 이 바이트 코드를 갖게되고 optimized된 머신코드를 이거로부터 생성하게 됩니다.
만약 왜 이런 두가지의 실행모드를 갖고있는지 알고 싶다면 JSConfEU에서 발표했던 내 비디오를 확인해보세요.
Bytecode는 머신 코드의 추상화입니다. 만약 바이트 코드가 물리적 CPU와 같은 계산적인 모델과 같게 디자인되었다면 바이트 코드를 머신 코드로 컴파일링 하는 것은 쉽습니다. 그래서 인터프리터가 종종 레지스터이거나 스택 머신인 이유입니다. Ignition은 누산기 레지스터를 지닌 레지스터 머신입니다.(데이터를 기억시키기 전에 보관하는 레지스터 또는 기억 장소에서 호출되어 보관되는 레지스터.)

V8의 바이트 코드를 함께 구성 할 때 JavaScript 기능을 구성하는 작은 빌딩 블록으로 생각할 수 있습니다.
V8은 수백개의 바이트 코드를 지니고 있습니다. 이것들은 연산자( Add 와 TypeOf 와 같은 ) 들에 대한 바이트 코드 또는 프로퍼티를 불러오는 것(LdaNamedProperty 같은)들에 대한 바이트 코드들이 있습니다.
V8은 또한CreateObjectLiteral 나SuspendGenerator와 같은 꽤 특별한 바이트 코드를 가지고 있습니다. 헤더 파일 [bytecodes.h] (https://github.com/v8/v8/blob/master/src/interpreter/bytecodes.h)는 V8의 바이트 코드의 전체 목록을 정의합니다.
각 바이트 코드는 입력 및 출력을 레지스터 피연산자로 지정합니다.
Ignition은 register r0, r1,r2, ..들을 사용하고 누산기 레지스터를 사용합니다. 대게 모든 바이트 코드들은 누산기 레지스터를 사용합니다. 바이트 코드가 지정하지 않는다는 점을 제외하고는 일반 레지스터와 같습니다. 예를 들면, Add r1은 register r1안에 있는 값을 누산기 안에 있는 값에 더합니다. 이것은 짧은 바이트 코드들로 유지하고 메모리에 저장합니다.
많은 바이트 코드들은 Lda 또는 Sta로 시작합니다. Lda와 Sta 안에 있는 a는 누산기를 나타냅니다. 예를 들면, LdaSmi [42] 는 작은 인티져(Smi) 42를 누산기에 로드 합니다.
Star r0 는 현재 값을 누산기 안에 있는 레지스터 r0에 저장합니다.
지금까지 기본, 실제 함수에 대한 바이트 코드를 볼 시간입니다.
function incrementX(obj) {
return 1 + obj.x;
}
incrementX({x: 42}); // V8’s compiler is lazy, if you don’t run a function, it won’t interpret it.
V8의 자바 스크립트 코드 바이트 코드를보고 싶다면 D8 또는 Node.js (8.3 이상)를 -print-bytecode 플래그로 호출하여 인쇄 할 수 있습니다. Chrome의 경우 명령 줄에서 --js-flags = "- print-bytecode"를 사용하여 Chrome을 시작하고 플래그가있는 Chromium 실행을 참조하십시오.
$ node --print-bytecode incrementX.js
...
[generating bytecode for function: incrementX]
Parameter count 2
Frame size 8
12 E> 0x2ddf8802cf6e @ StackCheck
19 S> 0x2ddf8802cf6f @ LdaSmi [1]
0x2ddf8802cf71 @ Star r0
34 E> 0x2ddf8802cf73 @ LdaNamedProperty a0, [0], [4]
28 E> 0x2ddf8802cf77 @ Add r0, [6]
36 S> 0x2ddf8802cf7a @ Return
Constant pool (size = 1)
0x2ddf8802cf21: [FixedArray] in OldSpace
- map = 0x2ddfb2d02309 <Map(HOLEY_ELEMENTS)>
- length: 1
0: 0x2ddf8db91611 <String[1]: x>
Handler Table (size = 16)
출력의 대부분을 무시하고 실제 바이트 코드에 집중할 수 있습니다. 다음은 각 바이트 코드의 의미입니다.
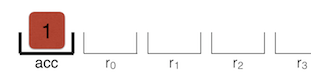
LdaSmi [1]
LdaSmi [1]은 누적 기에서 상수 값 '1'을 로드합니다.
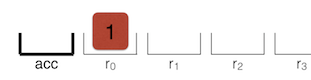
Star r0
다음으로,Star r0은 현재 accumulator 에있는 값 '1'을 레지스터r0에 저장합니다.
LdaNamedProperty a0, [0], [4]
LdaNamedProperty는a0의 명명 된 속성을 누적기에 로드합니다. ai는incrementX ()의 i 번째 인수를 가리 킵니다. 이 예제에서 우리는incrementX ()의 첫번째 인자 인a0에 명명 된 속성을 찾습니다. 이름은 상수0에 의해 결정됩니다. LdaNamedProperty는 별도의 테이블에서 이름을 찾기 위해0을 사용합니다 :
- length: 1
0: 0x2ddf8db91611 <String[1]: x>
여기서 '0'은 'x'에 매핑됩니다. 따라서이 바이트 코드는obj.x를 로드합니다.
값 '4'를 갖는 피연산자는 무엇을 위해 사용됩니까? 이 함수는incrementX ()함수의 _feedback vector_라는 인덱스입니다. 피드백 벡터에는 성능 최적화에 사용되는 런타임 정보가 들어 있습니다.
이제 레지스터는 다음과 같이 보입니다.
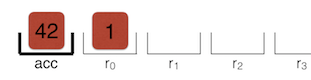
Add r0, [6]
마지막 명령은 누산기에 r0을 추가하여 43을 얻습니다. 6은 피드백 벡터의 다른 인덱스 입니다.
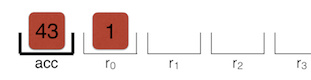
Return
Return은 누적 기의 값을 반환합니다. 이것이incrementX ()함수의 끝이다. incrementX () 호출자는 누적 기에서 `43 '으로 시작하여 이 값으로 더 작업 할 수 있습니다.
언뜻보기에 V8의 바이트 코드는 특히 모든 여분의 정보가 인쇄 된 상태에서 다소 신빙성이 있습니다. 그러나 Ignition가 누적기 레지스터가있는 레지스터 시스템이라는 것을 알게되면 대부분의 바이트 코드가하는 일을 파악할 수 있습니다.