任務排程 - LZerApp/crawlerenv GitHub Wiki
目錄 (🔎 點擊展開/關閉)
在一般情況下,使用 Python 作為主要語言進行網頁應用程式開發時,要進行任務排程會使用 Celery 搭配消息隊列處理,但這樣的技術棧選擇對於伺服器本身開銷較大並且依賴較多第三方軟體,因此本專案選擇使用 Advanced Python Scheduler (APScheduler)。
APScheduler 是基於 Quartz 開發的一個 Python 輕量級進程內任務調度框架,並且提供針對 Flask 框架進行擴展的套件,使用上十分方便,可以根據時間間隔或在特定時間週期執行任務。
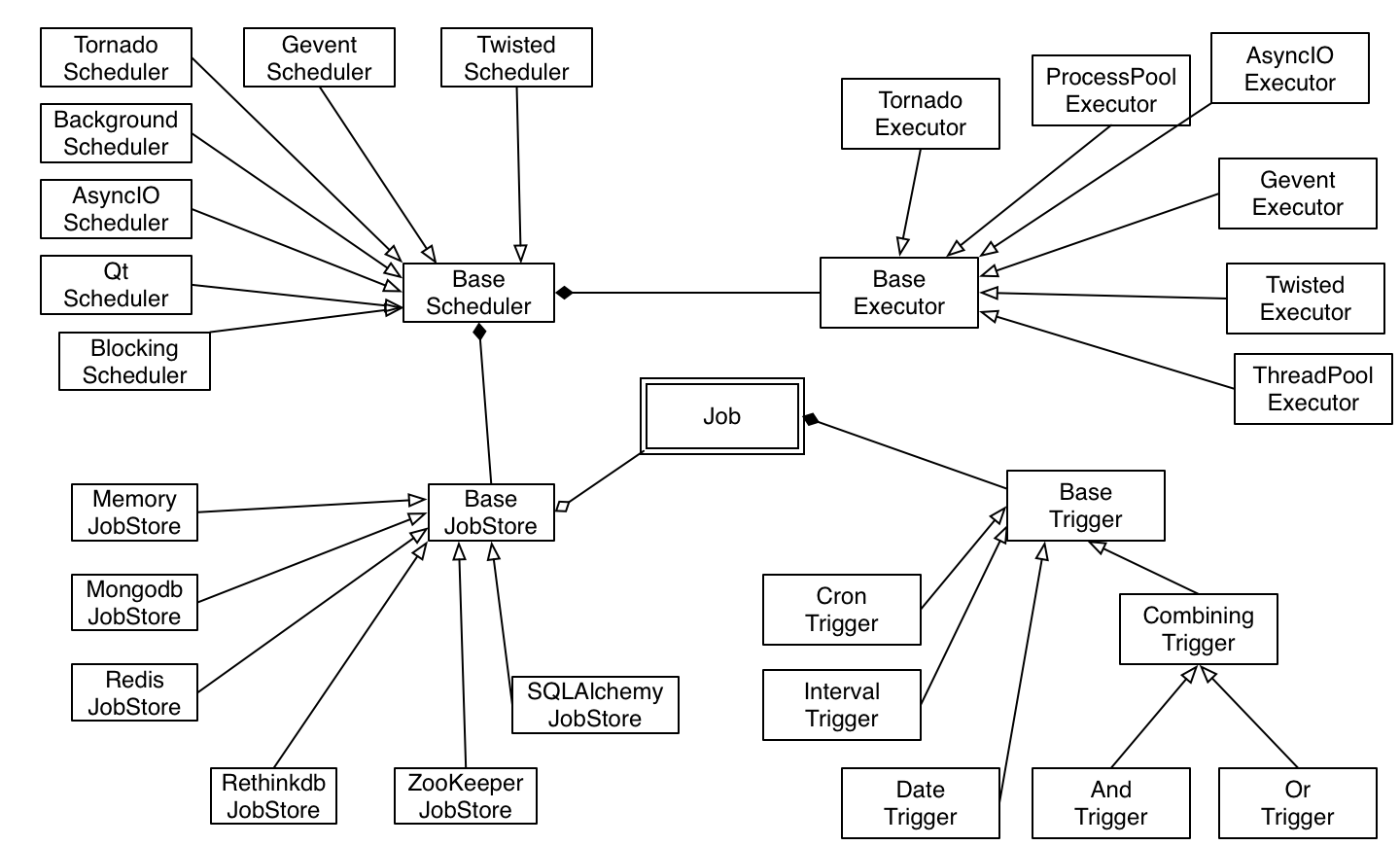
The relations between all major classes in APScheduler.
上圖為 APScheduler 專案中所有主要類別之間的關係圖,主要由四個部分組成:
- 觸發器(trigger) 包含調度邏輯,每一個任務都有屬於自己的觸發器,用於决定接下來哪一個任務會被執行。除了初始配置之外,觸發器是完全無狀態的。
- 執行器(executor) 處理任務的執行,透過在任務中提交制定的可呼叫物件到一個執行緒或執行緒池來進行。當任務完成後,執行器將會通知調度器。
- 調度器(scheduler) 提供適當的 API 供開發者處理任務調度的相關事宜,如添加任務、修改任務和移除任務。
- 作業存儲(jobstore) 用以儲存被調度的任務,預設的任務存儲方式是直接簡單地將任務保存在記憶體中,亦可以選擇將任務保存在外部的資料庫中,每一筆任務的資料在進行保存時會進行序列化,並在加載任務時被反序列化。
# Use APScheduler for simple Python project
$ pip install apscheduler
# Use APScheduler for Flask-based Project
$ pip install Flask-APSchedulerimport time
from apscheduler.schedulers.blocking import BlockingScheduler
schedule = BlockingScheduler()
def work1():
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
@schedule.scheduled_job('interval', seconds=2)
def work2():
print('Hello, WORK2')
schedule.add_job(work1, 'interval', seconds=5)
schedule.start()要進行調度或排程的任務可以使用 schedule.add_job() 方法添加(如上述程式中的 work1)或是使用 @schedule.scheduled_job() 裝飾器添加(如上述程式中的 work2)。在添加任務時需要給定以下參數:
-
id:代表該任務的唯一標識,之後可以透過id來查找任務 -
trigger:管理任務的調度方式,其值可以為date、cron或interval,針對不同的調度方式,所需的對應參數亦不同。-
date:定時調度,任務僅會執行一次,可使用參數run_date、timezone -
cron:定時調度,每到特定時刻執行,可使用參數 -
interval:間隔調度,每隔一段時間執行,可使用參數weeks、days、hours、minutes、seconds、start_date、end_date、timezone
-
# 移除所有任務(移除要放在 start() 之前才有效)
schedule.remove_all_jobs()
# 單一調度操作:獲取、暫停、恢復、移除
schedule.get_job('work') # 獲取
schedule.pause_job('work1') # 暂停
schedule.resume_job('work1') # 恢復
schedule.remove_job('work1') # 移除
# 多個調度操作
schedule.get_jobs() # 獲取所有任務列表
schedule.remove_all_jobs() # 移除所有任務(需在 start() 之前才有效)
# 關閉調度
schedule.shutdown(wait=False) # 預設狀況是調度器等待所有任務完成後關閉,設為 False 時直接關閉給定一個以 Flask 框架建構的網路應用程式,其目錄結構如下:
.
├── utils
│ ├── __init__.py
│ ├── crawlers.py // 該模組中存放的 PCHOME() 函數,是需要被執行的定時任務
│ └── ...
├── app.py // 入口程式
└── ...
每一支 Flask 應用程式中,都需要在入口程式中創建一個 Flask 類別的實例(通常命名為 app 如以下程式所示)。為了進行任務調度,需要初始化 APScheduler 並添加任務,此處的重點在於定時任務需要訪問 app 實例的應用程式上下文(application context),並直接將 app 做為參數傳遞進去:
from flask import Flask
from flask_apscheduler import APScheduler
... # 省略
app = Flask(__name__, template_folder='templates', static_url_path='/static')
# 註冊 APScheduler
scheduler = APScheduler()
scheduler.init_app(app)
# 添加任務
scheduler.add_job(id='dianping', func='util.crawlers:PCHOME', trigger='interval', day=1, args=[app, ])
scheduler.start()
... # 省略ValueError: TimeZone offset does not match system offset: 0 != 28800. Please, check your config files.
上述錯誤訊息通常發生在將程式佈署到生產環境時,由於系統時區與程式運行時區不一致所導致。因此必須確定程式執行的時區設定:
- 運行時區:設定檔案中需要配置
SCHEDULER_TIMEZONE環境變數的值 - 系統時區:作業系統中需要配置
/etc/timezone檔案下的時區
在 APScheduler 框架的設定下,每一個任務必須給定一個不重複的 id 值,用以確保任務不衝突且能夠被調度器識別,否則會拋出 ConflictingIdError 異常。然而在使用 Gunicorn 將應用程式部署於生產環境時,由於支持指定 worker 參數來開啟多個進程,每個單獨的進程都會啟動屬於自己的調度器而導致任務被多個進程創建。
在官方專案程式庫的這一則 issue 有給出一個解決方案,其核心概念是透過創建一個全局鎖來控制 scheduler 實例只執行一次,實作方式是在首次創建進程時創建一個 scheduler.lock 文並加上非阻塞互斥鎖,此時調度器可以成功執行;若文件加鎖失敗則拋出異常,表示 調度器已經執行了,最後再註冊一個退出事件用於當 Flask 退出時釋放文件鎖。
def register_scheduler():
f = open("scheduler.lock", "wb")
# noinspection PyBroadException
try:
fcntl.flock(f, fcntl.LOCK_EX | fcntl.LOCK_NB)
scheduler.start()
except:
pass
def unlock():
fcntl.flock(f, fcntl.LOCK_UN)
f.close()
atexit.register(unlock)- The Architecture of APScheduler
- Gunicorn 部署 Flask-Apscheduler 之踩坑紀錄
- Flask-APScheduler 定時任務與坑點解决方法
- 基於 Flask-APScheduler 實現添加動態定時任務