역전파와 CNN 비교 - LOPES-HUFS/DeepLearningFromForR GitHub Wiki
데이터 학습하기
CNN 모델 소개
이제 모델에 손글씨 데이터를 학습시켜 봅시다. 이번에는 CNN(Convolution Neural Network) 모델을 이용하여 학습 하겠습니다. CNN 모델은 이미지 인식이나 음성 인식 등 다양한 분야에서 사용됩니다.
library(dslabs)
source("./layers.R")
source("./utils.R")
source("./optimizer.R")
source("./cnn_simplenet_models.R")
init <- function(tensor=FALSE){
mnist_data <- get_data(tensor)
#손글씨 데이터
x_train_normalize <<- mnist_data$x_train
x_test_normalize <<- mnist_data$x_test
#정답 레이블
t_train_onehotlabel <<- making_one_hot_label(mnist_data$t_train, 60000, 10)
t_test_onehotlabel <<- making_one_hot_label(mnist_data$t_test, 10000, 10)
}
먼저 CNN 모델 구현 및 작동에 필요한 함수를 불러옵니다. 이어서 모델이 학습 할 MNIST 데이터 셋을 가져옵니다.
model.forward <- function(network, x){
conv_params <- list(W = network$W1, b = network$b1, stride = 1, pad = 0)
affine_params_1 <- list(W = network$W2, b = network$b2)
affine_params_2 <- list(W = network$W3, b = network$b3)
conv_temp <- forward("Convolution", x, conv_params)
relu_temp_1 <- forward("ReLU", conv_temp$out)
pool_temp <- forward("Pooling", relu_temp_1$out, pool_params)
flatten_temp <- forward("Flatten", pool_temp$out)
affine_temp_1 <- forward("Affine", flatten_temp$out, affine_params_1)
relu_temp_2 <- forward("ReLU", affine_temp_1$out)
affine_temp_2 <- forward("Affine", relu_temp_2$out, affine_params_2)
return(list(x = affine_temp_2$out, Affine_1.forward = affine_temp_1, Affine_2.forward = affine_temp_2, Relu_1.forward = relu_temp_1, Relu_2.forward = relu_temp_2, conv_temp = conv_temp, pool_temp=pool_temp, flatten = flatten_temp))
}
model.backward <- function(model.forward, network, x, t) {
# 순전파
loss_temp <- loss(model.forward, network, x, t)
# 역전파
dout <- 1
dout <- backward("SoftmaxWithLoss",loss_temp$softmax,dout)
dout1 <- backward("Affine",loss_temp$predict$Affine_2.forward,dout$dx)
dout2 <- backward("ReLU",loss_temp$predict$Relu_2.forward,dout1$dx)
dout3 <- backward("Affine",loss_temp$predict$Affine_1.forward,dout2$dx)
dout_3 <- backward("Flatten",loss_temp$predict$flatten,dout3$dx)
dx <- backward("Pooling",loss_temp$predict$pool_temp,dout_3,pool_params)
dx1 <- backward("ReLU",loss_temp$predict$Relu_1.forward,dx$dx)
dx2 <- backward("Convolution",loss_temp$predict$conv_temp,dx1$dx)
grads <- list(W1 = dx2$dW, b1 = dx2$db, W2 = dout3$dW, b2 = dout3$db, W3 = dout1$dW, b3 = dout1$db)
return(grads)
}
학습을 위한 모델들을 살펴 봅시다. model.forward 함수는 손실 값을 구하기 위한 함수입니다. 이 모델은 3층 CNN 모델입니다. 층 구성은 convolution-relu-pool(1층 계산), affine-relu(2층 계산), affine (3층 계산) 으로 이루어져 있습니다. model.backward 함수는 model.forward 함수의 과정을 거꾸로 진행하는 과정입니다. 이 함수는 가중치 파라미터들을 갱신된 값을 계산하는 역할입니다. 이 두 함수가 훈련 과정의 핵심입니다.
이제 학습을 위한 파라미터를 작성하여 모델을 학습시킬 준비를 마칩니다.
init(tensor=TRUE)
pool_params <- list(pool_h=2, pool_w=2, stride=2, pad=0)
아래의 model.train 함수는 손실값을 계산하고 가중치 파라미터들을 갱신하는 훈련 과정을 함수로 만든 것입니다.
model.train <- function(train_x, train_t, test_x, test_t, batch_size, epoch, optimizer_name, debug=FALSE){
train_loss_list <- data.frame(loss_value = 0)
test_acc <- data.frame(acc = 0)
train_size <- dim(train_x)[4]
iter_per_epoch <- max(train_size / batch_size)
iters_num <- iter_per_epoch * epoch
params <- list(input_dim=c(28,28,1), filter_size = 5, filter_num = 30,
pad = 0, stride = 1, hidden_size = 100, output_size = 10,
weight_init_std = 0.01)
network <- simple_net_params(params = params)
for(i in 1:iters_num){
batch_mask <- sample(train_size, batch_size)
x_batch <- train_x[,,,batch_mask]
x_batch <- array(x_batch,c(28,28,1,100))
t_batch <- train_t[batch_mask,]
gradient <- model.backward(model.forward,network, x_batch, t_batch)
network <- get_optimizer(network, gradient, optimizer_name)
loss_value <- loss(model.forward=model.forward, network = network, x_batch, t_batch)$loss
print(loss_value)
train_loss_list <- rbind(train_loss_list,loss_value)
if(i %% iter_per_epoch == 0){
acc <- model.evaluate(model.forward, network, x_test_normalize, t_test_onehotlabel)
test_acc <- rbind(test_acc$acc,acc)
print(acc)
}
}
return(list(network=network,train_loss_list=train_loss_list,test_acc=test_acc))
}
이제 학습을 진행시켜 봅시다.
model_temp <- model.train(train_x = x_train_normalize,train_t = t_train_onehotlabel,batch_size = 100,epoch = 20,optimizer_name = "adam",TRUE)
모델 학습 과정은 1에폭 당 약 20분의 시간이 걸립니다. 또한, 학습이 진행되는 동안 실시간으로 변화하는 손실 값과 에폭 당 테스트 셋에 대한 정확도가 출력되어 볼 수 있습니다. 참고로 위 코드에서와 같이 20에폭을 실행할 경우 약 6~7시간이라는 오랜 시간이 걸립니다. 따라서 오랜 시간이 걸리는 것을 원하지 않는 분들은 epoch 파라미터의 숫자 20을 1로 바꾸어 주면 더 짧은 시간이 소요됩니다.
model.evaluate(model.forward, model_temp$network, x_test_normalize, t_test_onehotlabel)
[1] 0.9834
모델 훈련의 결과를 테스트 셋 데이터를 통해 알아보면 98.34 %의 정확도를 가진 모델이 만들어졌음을 알 수 있습니다. 참고로 이 정확도의 경우 직접 코드를 실행할 경우 학습시 초기 값의 랜덤값으로 인해 약 98% 대의 다른 수치가 나올 수 있습니다.
이층 신경망 모델과 CNN 모델 비교
CNN 모델의 성능을 이층 신경망 모델과 비교해 봅시다. 먼저 그래프를 통해 로스 값 차이부터 살펴봅시다.
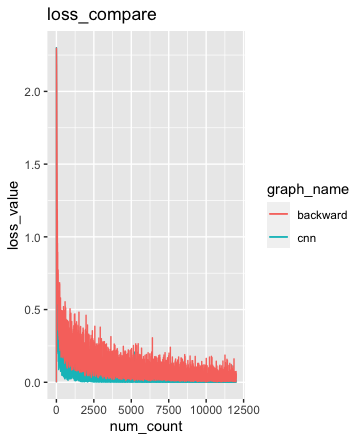
그림에서 검은색이 CNN 모델의 손실 값이고 빨간색이 이층 신경망 모델의 손실값입니다. 그림을 보면 CNN 모델의 손실값이 더 낮은 위치에 분포해 있다는 것을 확인할 수 있습니다.
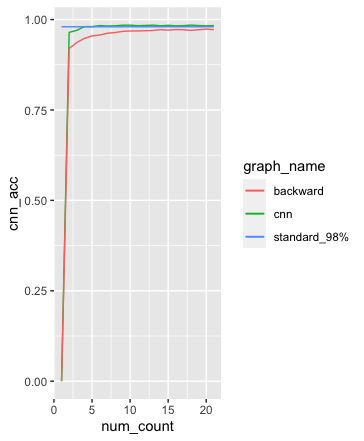
그림에는 3가지 선이 있습니다. 검은색 선이 CNN 모델의 정확도이며, 빨간색 선이 경이층 신경망 모델의 정확도이고 파란색 직선이 기준 값이 되는 98% 선입니다. 그림에서 보면 검은색 선이 빨간색보다 높이 위치한 것을 확인할 수 있습니다. 또한, 검은색 선이 파란색의 기준점 98%와 거의 겹치는 것도 확인할 수 있습니다.
결론적으로 보면 CNN 모델이 이층 신경망 모델 보다 손실 값이 더 낮고 정확도는 더 높은 것을 확인할 수 있습니다. 즉 CNN 모델의 성능이 더 좋은 것입니다.
숫자맞추기
위 모델이 MNIST의 숫자 이미지를 10개를 사용하여 어떻게 숫자를 예측하는지 살펴 보겠습니다. 먼저 MNIST 숫자 이미지를 확인합니다. 대표적으로 1개만 확인합니다.
mnist_data <- get_data()
draw_image(mnist_data$x_train[2,])

위 숫자 이미지는 0입니다. 과연 이 모델은 10개의 숫자를 모두 맞출 수 있을까요? 지금까지 학습시킨 모델에게 10개의 숫자가 무엇인지 물어보겠습니다.
predict_10 <- predict_cnn(network=network,x=array(x_train_normalize[,,,1:10],c(28,28,1,10)))
apply(predict_10,1,which.max)-1
[1] 5 0 4 1 9 2 1 3 1 4
apply(predict_10,1,max)
[1] 0.9984279 1.0000000 1.0000000 0.9999999 0.9998252 1.0000000 1.0000000 1.0000000 0.9999834 1.0000000
mnist_data$t_train[1:10]
[1] 5 0 4 1 9 2 1 3 1 4
10개의 숫자들을 예측하고 predict_10으로 저장한 다음 최대 값이 있는 위치를 찾아 봅니다. 참고로 R은 다른 프로그램처럼 0부터 세지 않고 1부터 셉니다. 따라서 최대값의 위치에서 1을 빼주면 우리가 예측한 숫자의 값이 나옵니다. 각 위치에 대하여 몇%의 확률로 예측했는지도 확인해볼 수 있습니다. 첫 번째 09984279 값은 약 99.8%의 확률로 숫자가 5임을 예측합니다. 두 번째의 1 값은 약 100%의 확률로 숫자가 0임을 예측합니다. 대부분의 숫자들을 99% 혹은 100%에 가깝게 예측합니다. 데이터의 실제 숫자값 기록과 비교해보면 똑같은 것을 확인할 수 있는데 이 말은 즉 모델이 이미지 데이터를 보고 숫자 10개를 맞춘 것입니다.