Toolchain - Kasimashi/Systemes-embarques GitHub Wiki
- Virtualisation
- Eclipse
- Code Composer Studio (Texas Instrument)
- IAR Embedded Workbench
- Keil (Permet de mettre en place un environnement embarqué rapidement et facilement, possède un simulateur et une interface de debug très intuitive).
- STM32CubeIDE et CubeMX
- Quartus (FPGA Altera)
- Vivado (FPGA Xilinx)
La compilation est le fait de transformer un programme écrit en language C/Assembleur vers du binaire (des 0 et 1).
La compilation se fait la plupart du temps en embarqué sous la forme de cross-compilation. Mais qu'est-ce qu'une chaine de cross compilation?! La machine de développement est en effet en général un ordinateur commum et non pas la cible embarqué directement. Ainsi le programme est écris sur une machine Intel,AMD,etc ... et l'architecture cible est un processeur du type ARM, etc ...
Un des cross-compilateurs les plus utilisé pour arm est : arm-none-eabi
Qui présente les différents compilateurs habituel tel que gcc g++ as etc ...

La compilation est le processus qui se déroule en plusieurs phases pour créer les fichiers nécéssaire à l'execution du programme par la machine. Elle permet de traduire un programme C en langage machine (binaire) que pourras executer cette dernière.

Elle se déroule en plusieurs phases :
- La phase de préprocessing : Le code source est analysé par le program appelée preprocesseur qui se charge d'enlever les commentaires, de remplacer les defines dans le code etc ...
- La phase d'assemblage ou de compilation : Les fichiers générés par le preprocesseur sont traduit en assembleur, ensuite vers un language machine (celle de la machine cible).
- La phase de Link : Permet de rejoindre les fichiers entres eux (un programme C est parfois divisé en plusieurs sous fichiers).
- La phase de boot : placé avant le main qui permet d'initilialiser la pile et son pointeurs ainsi que diverses variables.
À cela s’ajoute des librairies pour le C++ ainsi que des librairies C avec des extensions POSIX et les librairies standards. Nous utiliserons enfin une implémentation de la microlib C spécifique pour ARM et qui offre une version optimisée (en particulier l’empreinte mémoire) des librairies standards pour les systèmes embarqués.
Lorsque que la compilation est effectuée cette dernière génères de nombreux fichiers qui peuvent nous être bien utile :
- Un fichier fichier de link (.ldscript) qui te permet d'indiquer les différentes sections du programme ainsi que le point d'entrée.
- Les fichier listing (.lst) : contiennent des informations sur les erreurs de compilation et/ou d’assemblage.
- Le fichier mapping (.map) : contient l’ensemble des informations relatives à l’organisation mémoire de l’application. On peut y trouver entre autres les adresses physiques où seront implémentées les variables, les procédures, les sections, etc.
- Le fichier exécutable ( .axf ou .elf ou .hex) : contient l’image (en binaire ou en version éditable de l’application)
Le fichier de Linker est un fichier CAPITALE:
Il permet au compilateur d'assembler les fichiers objects .o vers le fichier output final : En d'autres termes : il permet au compilateur de faire entre les sections, les zones mémoires et le programme. Il possède aussi les informations concernant ou se trouve les données du programme et quelle taille elles possède. Il permet aussi d'indiquer au programme ou se trouve le point d'entrée. (Souvent pointé vers le vecteur de la table d'interruption).
Le language de programmation d'un fichier de Linker est "GNU Linker Command Language".

Par exemple avec le compilateur chez TI ce fichier porte souvent l'extension .cmd, sous GCC il porte l'extension .ld, sous IAR on le retrouve sous l'extension .icf
Les principales commandes du Linker sont les suivantes: Plus d'info (https://wiki.osdev.org/Linker_Scripts)
ENTRY
OUTPUT_FORMAT
STARTUP
INPUT
OUTPUT
MEMORY
SECTIONS
KEEP
ALIGN
AT>
- Cette commande est utilisé comme l'addresse du point d'entrée du binaire, l'information est dans le header du fichier ELF généré.
- Dans notre cas, "Reset_Handler" is the entry point into the application. (La première instruction que le processeur utilise lors d'un reset). La syntaxe est la suivante :
/* Entry Point */
ENTRY(Reset_Handler)
Ceci veut dire que le processeur pointe sur la fonction généralement présent dans stm32_startup.c pour les STM32 :
void Reset_Handler(void);
Cette commande vous permet de décrire les différentes zones mémoires présentes dans la cible avec les informations concernant l'addresse de départ de la zone et sa taille. Le Linker utilise ses informations pour calculer la mémoire consommé sur les données ou pour le code. Et permet de renvoyer une erreur au link si la zone mémoire est dépassée. Typiquement un fichier de Link a une commande "MEMORY".
Les zones mémoires sont décrite dans ce fichier par exemple pour le processeur AM335X de chez TI: ces zones dépendent du memory map du microcontoleur choisi.
Par exemple pour le processeur AM335X on trouve dans la doc : https://www.ti.com/lit/ug/spruh73q/spruh73q.pdf

MEMORY
{
#ifndef M3_CORE /* A8 memory map */
SRAM: o = 0x402F0400 l = 0x0000FC00 /* 64kB internal SRAM */
L3OCMC0: o = 0x40300000 l = 0x00010000 /* 64kB L3 OCMC SRAM */
M3SHUMEM: o = 0x44D00000 l = 0x00004000 /* 16kB M3 Shared Unified Code Space */
M3SHDMEM: o = 0x44D80000 l = 0x00002000 /* 8kB M3 Shared Data Memory */
DDR0: o = 0x80000000 l = 0x40000000 /* 1GB external DDR Bank 0 */
#else /* M3 memory map */
M3UMEM: o = 0x00000000 l = 0x00004000 /* 16kB M3 Local Unified Code Space */
M3DMEM: o = 0x00080000 l = 0x00002000 /* 8kB M3 Local Data Memory */
M3SHUMEM: o = 0x20000000 l = 0x00004000 /* 16kB M3 Shared Unified Code Space */
M3SHDMEM: o = 0x20080000 l = 0x00002000 /* 8kB M3 Shared Data Memory */
#endif
}
Les SECTIONS sont utilisés pour créer différentes sections dans le fichier d'output ELF généré pour regrouper les sections des différents fichiers .o . A ce stade on parle de la composition interne dans la zone mémoire concerné.
Les sections sont défini dans le fichier output dans l'ordre dans lequel les sections sont déclarés. Il permet de relier les sections aux zones mémoires ou l'on veut instruire le code.
La syntaxe est la suivante : Les sections sont ensuite reparties dans la mémoire:
SECTIONS
{
.text:
{
}> (vma) AT> (lma)
}
où LMA (Low Memory Address) VMA (Virtual Memory Address).
Rmq : vma est égal à lma, il est possible d’utiliser une syntaxe plus courte : }> FLASH
Selon le schéma ci-dessous, nous voyons que la zone .data doit être copiée de la FLASH (load address) vers la SRAM (virtual address ou absolute address). C’est ce que nous retrouvons dans la syntaxe de la commande SECTIONS > SRAM AT> FLASH
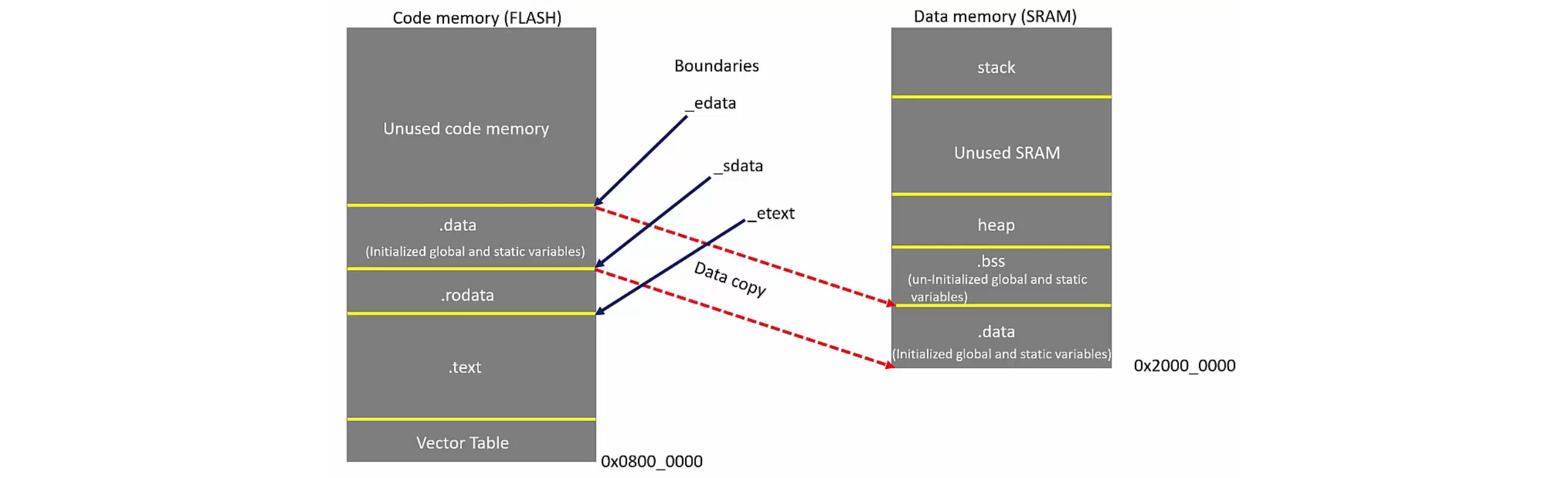
Les sections sont ensuite reparties dans la mémoire:
SECTIONS
{
#ifndef M3_CORE /* A8 memory map */
.text > L3OCMC0
.stack > L3OCMC0
.bss > L3OCMC0
.cio > L3OCMC0
.const > L3OCMC0
.data > L3OCMC0
.switch > L3OCMC0
.sysmem > L3OCMC0
.far > L3OCMC0
.args > L3OCMC0
.ppinfo > L3OCMC0
.ppdata > L3OCMC0
/* TI-ABI or COFF sections */
.pinit > L3OCMC0
.cinit > L3OCMC0
/* EABI sections */
.binit > L3OCMC0
.init_array > L3OCMC0
.neardata > L3OCMC0
.fardata > L3OCMC0
.rodata > L3OCMC0
.c6xabi.exidx > L3OCMC0
.c6xabi.extab > L3OCMC0
#else /* M3 memory map */
.text > M3UMEM
.stack > M3DMEM
.bss > M3DMEM
.cio > M3DMEM
.const > M3UMEM
.data > M3DMEM
.switch > M3DMEM
.sysmem > M3DMEM
.far > M3DMEM
.args > M3DMEM
.ppinfo > M3DMEM
.ppdata > M3DMEM
/* TI-ABI or COFF sections */
.pinit > M3UMEM
.cinit > M3UMEM
/* EABI sections */
.binit > M3UMEM
.init_array > M3UMEM
.neardata > M3DMEM
.fardata > M3DMEM
.rodata > M3UMEM
.c6xabi.exidx > M3UMEM
.c6xabi.extab > M3UMEM
#endif
}
Rmq :
#pragma est spécifique au compilateur, la syntaxe peut donc varier pour votre compilateur.
Le pragma DATA_SECTION alloue de l'espace pour le symbole dans une section appelée nom de section. La syntaxe du pragma en C pourrait être :
#pragma DATA_SECTION (symbol, "section name");
Le pragma DATA_SECTION est utile si vous avez des objets de données que vous souhaitez lier dans une zone distincte de la section .bss.
Le pragma CODE_SECTION alloue de l'espace pour la fonction dans une section nommée section name. Le pragma CODE_SECTION est utile si vous avez des objets de code que vous souhaitez lier dans une zone distincte de la section .text. La syntaxe du pragma en C pourrait être :
#pragma CODE_SECTION (func, "section name");
Cette commande est utilisée pour aligner les sections sur des adresses multiples de 4, par exemple. On peut trouver ce genre de syntaxe dans les sections. Exemple :
SECTIONS
{
.text:
{
*(.isr_vector)
*(.text)
*(.rodata)
. = ALIGN(4);
end_of_text = .; /* Store the updated location counter value for */
/* ‘end_of_data’ symbol. */
}> FLASH
}
Essayez toujours d’aligner les différentes sections avant leur fin. Dans notre cas, nous allons aligner les sections .text, .data et .bss.
Voici pour un programme simple ou vont être stockés les informations :
short m = 10; <- [ short m (Global vars(.bss)) ] [ = 10 (Init Vals(c.init)) ]
short x = 2; <- [ short x (Global vars(.bss)) ] [ = 2 (Init Vals(c.init)) ]
short b = 5; <- [ short b (Global vars(.bss)) ] [ = 5 (Init Vals(c.init)) ]
main()
{
short y = 0; <- [ short y = 0 (Local Vars (.stack) ]
y = m*x; <- [ y = m*x (Code (.text) ]
y = y + b; <- [ y = y + b (Code (.text) ]
printf("y=%d",y); <- [ printf("y=%d",y) (Std C I/O (.cio)]
}
Plus d'info : https://linuxembedded.fr/2021/02/bare-metal-from-zero-to-blink
