Home - JAWolfe04/CS5590-Lab-1 GitHub Wiki
| Student | Github ID | Class ID | Contribution | |
|---|---|---|---|---|
| Acikgoz, Mehmet | [email protected] | acikgozmehmet | 1 | MapReduce Facebook Usecase |
| Attaluri, Lalith Chandra | [email protected] | LalithChandraAttaluri | 4 | Hive Usecase |
| Karumanchi, Pranitha Saroj | [email protected] | pranithakarumanchi99 | 7 | Solr Usecase |
| Wolfe, Jonathan Andrew | [email protected] | JAWolfe04 | 17 | MapReduce Youtube Usecase |
Finding Facebook common friends:
Facebook has a list of friends (note that friends are a bi-directional thing on Facebook. If I'm your friend, you're mine). They also have lots of disk space and they serve hundreds of millions of requests every day. They've decided to pre-compute calculations when they can to reduce the processing time of requests. One common processing request is the "You and Joe have 230 friends in common" feature. When you visit someone's profile, you see a list of friends that you have in common. We're going to use MapReduce so that we can calculate everyone's common friends.
Assume the friends are stored as Person->[List of Friends], our friends list is then (depicted as "input" in the following figure):

During the Split-phase: Each line will be distributed to cluster and each line will be an argument to a mapper.
During the Map-phase: For every friend in the list of friends, the mapper will output a key-value pair. The key will be a friend along with the person. The value will be the list of friends. The key will be sorted so that the friends are in order, causing all pairs of friends to go to the same reducer.

During the Shuffle-part: We group them by their keys and get, before we send these key-value pairs to the reducers,
During Reducer-phase: Each line will be passed as an argument to a reducer. The reduce function will simply intersect the lists of values and output the same key with the result of the intersection.

Please click on the link to to reach the full source for MutualFriends.
Please click on the link to to reach the source for generating your own test data.
Test-1:
(For the given example above.)
hadoop jar MutualFriends-1.0.jar MutualFriends /user/cloudera/lab1/test5 /user/cloudera/lab1/test5out


Test-2:
(A new test data is created with the [UserFriendsTestData.java] (https://github.com/JAWolfe04/CS5590-Lab-1/blob/master/question1/SourceCode/UserFriendsTestData.java))
hadoop jar MutualFriends-1.0.jar MutualFriends /user/cloudera/lab1/test10 /user/cloudera/lab1/test10out


Implement MapReducealgorithm to perform analysis on Youtube dataset. Using the Youtube dataset perform some Analysis and draw out some insights like what are the top 10 rated videos on YouTube, who uploaded the most number of videos.
Find out what are the top 5 categories with maximum number of videos uploaded.
Find the top 10 rated videos on youtube.
The input dataset is a dataset of youtube data found here.
The data consists of rows of youtube video data separated by tabs and a different video for each row. There is no header in the dataset, the data may be incomplete with only the video ID in a row and each row consisting of:
- Column 1: Video ID of 11 characters.
- Column 2: Uploader of the video.
- Column 3: Interval between the day of establishment of Youtube and the date of uploading of the video.
- Column 4: Category of the video.
- Column 5: Length of the video.
- Column 6: Number of views for the video.
- Column 7: Rating on the video.
- Column 8: Number of ratings given for the video.
- Column 9: Number of comments done on the videos.
- Column 10: Related video IDs with the uploaded video.
The dataset was stored in hadoop with:
hadoop fs -mkdir /user/cloudera/Youtube
hadoop fs -mkdir /user/cloudera/Youtube/Input
hadoop fs -put /home/cloudera/youtubedata.txt /user/cloudera/Youtube/Input

The source code for this problem set can be found here. The challenge for this dataset involves mapping the categories to each video in the mapping stage then reducing them into a sum of videos in each category in the reduce stage and maintaining a list of the top 5 categories with the most videos.
The mapping stage is fairly straight forward with mapping each video's category as a key to a video count of 1 for the value. The challenge arises from the fact that the dataset was tab delimited and some of the data is incomplete and does not have any values beyond a video ID. For such videos, they were filtered out by only writing those with the required info with the following code:
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] row = value.toString().split("\t");
if(row.length >= 4) {
context.write(new Text(row[3]), new IntWritable(1));
}
}The next challenge was to reduce the categories into a video count and rank them in the top 5 categories list if they have more than the categories already in the list. To maintain the list, a dynamic array was required to store the list of category and count pair in the reducer class:
private ArrayList<String[]> topFiveCatagories = new ArrayList<String[]>();The first action of the reducer was to count the videos with the same category. Once the count was finished, the category and count were either added to the list in order with addToArrayList method if the list was less than 5 categories or if the last item in the list had a lower count in which case the last item was dropped and the current category was inserted into the proper place:
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value : values) {
sum += Integer.parseInt(value.toString());
}
if(topFiveCatagories.size() < 5) {
addToArrayList(topFiveCatagories, key.toString(), sum);
} else if(Integer.parseInt(topFiveCatagories.get(4)[1]) < sum) {
topFiveCatagories.remove(4);
addToArrayList(topFiveCatagories, key.toString(), sum);
}
}The addToArrayList method was used to handle adding the data to a list and maintain the priority:
private void addToArrayList(ArrayList<String[]> array, String key, int value) {
int index = 0;
while(index < array.size() && Integer.parseInt(array.get(index)[1]) > value) {
++index;
}
String[] video = {key, String.valueOf(value)};
array.add(index, video);
}Once all of the categories were reduced, the cleanup method is called to write the resulting list to the output:
public void cleanup(Context context) throws IOException, InterruptedException {
for(String[] cat : topFiveCatagories) {
context.write(new Text(cat[0]), new IntWritable(Integer.parseInt(cat[1])));
}
}Once all of the coding was completed, the jar file was complied in eclipse and used in the cloudera terminal with:
hadoop jar YoutubeQ1.jar youtubeq1.YoutubeQ1 /user/cloudera/Youtube/Input /user/cloudera/Youtube/Output/Q1

The source code for this problem set can be found here. The challenges for this problem set were very similar to that of the first problem set. The mapper needed to associate the rating with the video ID and the reducer created a list of the 10 top videos with the highest rating.
In the mapping stage, all that needed to be done was to split each row into video data and separate each data entry by tab then pass along the key/value pair to the reducer. The video ID as the key and rating as the value were passed along to the reducer. Any row without a rating was not passed to the reducer:
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] row = value.toString().split("\t");
if(row.length >= 7) {
context.write(new Text(row[0]), new FloatWritable(Float.parseFloat(row[6])));
}
}In the reducer class, a dynamic array was used to hold the key/value pairing of the video ID and rating of the top 10 videos by rating in order:
private ArrayList<String[]> topTenRatedVideos = new ArrayList<String[]>();Items were added in the same manner as described in problem set 1 with the method:
private void addToArrayList(ArrayList<String[]> array, String key, float value) {
int index = 0;
while(index < array.size() &&
Float.parseFloat(array.get(index)[1])
> value) {
++index;
}
String[] video = {key, String.valueOf(value)};
array.add(index, video);
}The challenge of the reduce is to simply get the rating from the value for each video and either add it to the top 10 list if the list has less than 10 video or add the video to the list if it has a higher rating than the lowest rating while also removing the lowest rated and inserting the video in the appropriate place.
public void reduce(Text key, Iterable<FloatWritable> values, Context context) throws IOException, InterruptedException {
float rating = 0;
for(FloatWritable value : values) {
rating = Float.parseFloat(value.toString());
}
if(topTenRatedVideos.size() < 10) {
addToArrayList(topTenRatedVideos, key.toString(), rating);
} else if(Float.parseFloat(topTenRatedVideos.get(9)[1])
< rating) {
topTenRatedVideos.remove(9);
addToArrayList(topTenRatedVideos, key.toString(), rating);
}
}Once the videos were all reduced into a top 10 list, the cleanup method is run and writes to the output the generated top 10 list.
public void cleanup(Context context) throws IOException, InterruptedException {
for(String[] video : topTenRatedVideos) {
context.write(new Text(video[0]), new FloatWritable(Float.parseFloat(video[1])));
}
}Once all of the coding was completed, the jar file was complied in eclipse and used in the cloudera terminal with:
hadoop jar YoutubeQ2.jar youtubeq2.YoutubeQ2 /user/cloudera/Youtube/Input /user/cloudera/Youtube/Output/Q2

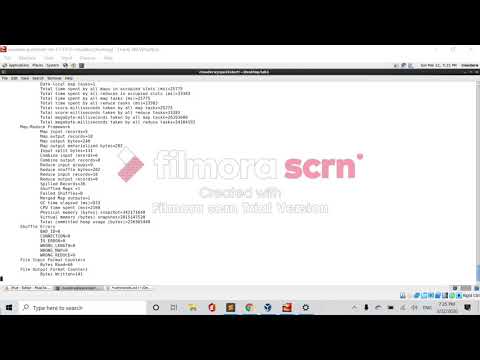
- Console Log
- Problem set 1 Output
-
Problem set 2 Output
- The output of problem set 2 only reflects 10 of the videos with a 5 star rating. There are numerous 5 star out of 5 stars videos in the dataset.
The output was printed to the console with:
hadoop fs -cat /user/cloudera/Youtube/Output/Q1/part-r-00000 | head -20

The output was printed to the console with:
hadoop fs -cat /user/cloudera/Youtube/Output/Q2/part-r-00000 | head -20

Take any of the datasets given and write 10 queries in hive. We need to write both complex and innovative queries. Use built-in functions in your queries and Complex queries are used for Solr queries.
- Cloudera
- Command line interface
- Hive in cloudera
- Superhero dataset
Super heroes data set had been extracted from below URL https://www.kaggle.com/claudiodavi/superhero-set/data
First we create the hive table which with table name heros and the complex datatypes I used here are array and float. after creating table , load the dataset into the table and below is the snippet which shows the command.


Query which displays the names with their height sum and are grouped by name.


In this query pattern matching is done.

Query to show the max weight of the alignments given in the dadtaset and grouped by alignment.

Query to display the id and gender of the particular data given.

Query to show the count of the gender of female who have the a particular haircolor and is grouped by haircolor.

Query selecting a substring from the name column where built in function is used.

Query which shows the distinct function whic is ued upon the name where it identifies all unique names.


Query which displays the publishers which match the hair color black.

Query which shows the avg of the weight for the gender male and is grouped by gender.

Query which shows the publishers and concatenate the haircolor and height where haircolor should not remain empty from the hero table.

Take any of the datasets given and write 10 queries in Solr. We need to write both complex and innovative queries. Use built-in functions in your queries and Complex queries are used for Solr queries. This section and video were made by Pranitha Saroj Karumanchi and uploaded by Lalith Chandra Attaluri.
- Cloudera
- Command line interface
- Solr in cloudera
- Super Heroes Dataset
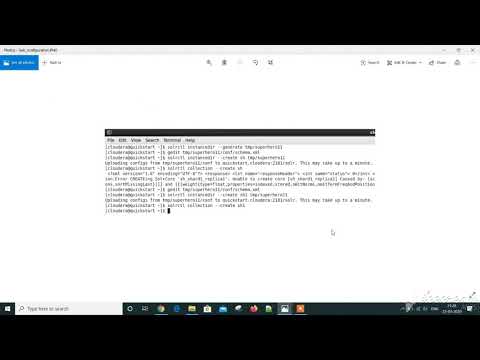
First a core is created and given name and the schema the xml file is edited as present in the fields present in the table. A collection is again created and The following screenshot shows that.


Then we need to open the Solr and paste the heros data into the documents space and change the file into CSV and the data is successful, A success message is displayed on the side.

Query that displays Proximity search.

Query that shows the eyecolour is blue and race can contain human or blond.

In this query AND and NOT operators used.

Query that displays the skincolor which is empty.

Query that shows which have the same height and weight.

Caret symbol is used by the boosting factoR and higher the boosting number and The most near retrieved rows are showed.

In this query OR and NOT operators used.

Query that list rows where range of height is given but not the the name.

Query that list range of weights.

Query that shows Proximity of the publisher

Video by Lalith Chandra Attaluri and covers both Hive and Solr.