Even more detailed design notes - IKANOW/Aleph2 GitHub Wiki
Basic Bucket Management
Create/delete/activate/suspend buckets
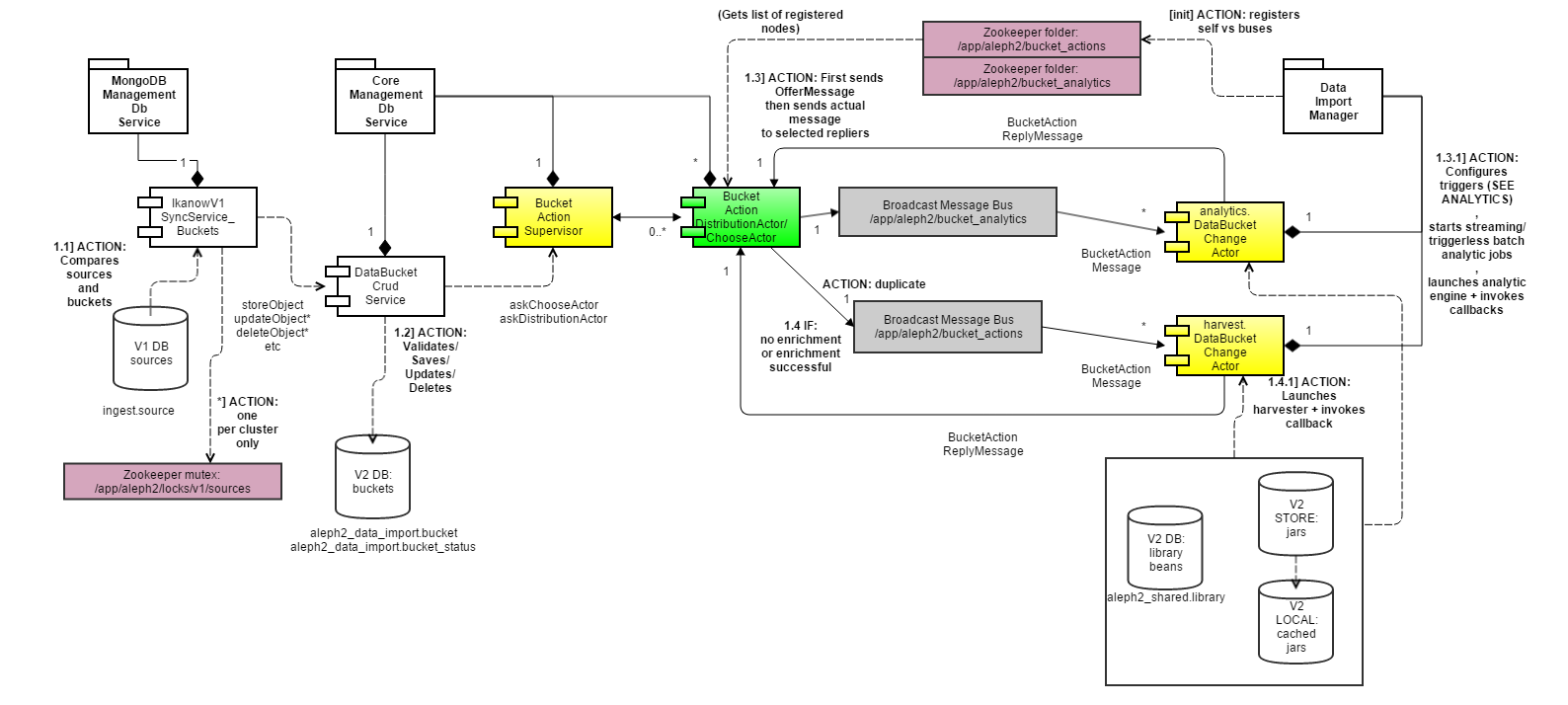
Message types (see https://github.com/IKANOW/Aleph2/blob/master/aleph2_data_import_manager/src/com/ikanow/aleph2/data_import_manager/harvest/actors/DataBucketHarvestChangeActor.java#L303):
- Before any of the messages are invoked, IHarvestTechnologyModule.onInit is called, and IHarvestContext.setBucket is called)
- BucketActionOfferMessage:
- when a message (generated by a change to the bucket/bucket_status table) needs to be sent to a set of DIMs (DataImportManagers), first one of these is generated (for all nodes matching bucket.node_list_rules) - only nodes that return true via canRunOnThisNode receive the actual message (and if it's a single node then CMDB (Core Management DB) decides which of the allowed nodes is "chosen")
- calls IHarvestTechnologyModule.canRunOnThisNode
- DeleteBucketActionMessage
- When a bucket is deleted from the CMDB
- calls IHarvestTechnologyModule.onDelete
- NewBucketActionMessage
- When a bucket is first created
- calls IHarvestTechnologyModule.onNewSource
- UpdateBucketActionMessage
- When:
- A bucket is modified
- A bucket_status changes suspended/unsuspended
- A test finishes
- calls IHarvestTechnologyModule.onUpdatedSource
- When:
- PurgeBucketActionMessage
- When the purge bucket API call is made (eg via "delete docs" in the V1 UI)
- calls IHarvestTechnologyModule.onPurge
- TestBucketActionMessage
- When the test bucket API is called (see below). Note that the test end is indicated by by an UpdateBucketActionMessage with suspended set to true
- call IHarvestTechnologyModule.onTestSource
- PollFreqBucketActionMessage
- For unsuspended buckets, this message is generated once every bucket.poll_frequency period (Eg "1 minute")
- call IHarvestTechnologyModule.onPeriodicPoll
Note that the following steps are performed inside CMDB whenever a bucket is created/changes:
- Static validation of the bucket (see DataBucketCrudService)
- For each enabled schema in the updated bucket, the corresponding IService.validateSchema is called (note each data service type eg ISearchIndexService, IDocumentService has its own validateSchema method, unlike below where a common underlying interface is used).
- For each schema in the new or updated bucket, the corresponding IDataServiceProvider.onPublishOrUpdate is called.
A few noteworthy things relating to how harvest contexts are created:
- The JARs specified in all the various shared library locations (eg harvest_configs[*].library_names_or_ids) are cached and added to a separate classloader
- (The above IHarvestTechnologyModule calls are called in that classloader thread context)
- A separate IHarvestContext is created for each bucket, and passed into the above IHarvestTechnologyModule calls
- The harvest technology will normally call some combination of:
- IHarvestContext getHarvestLibraries - a list of the user specified shared libraries
- IHarvestContext getHarvestContextLibraries - a list of the system libraries either needed by the system (eg aleph2_data_model.jar), or needed by one of the services specified in the buckets (eg aleph2_search_index_service.jar if enabled), or manually specified in the parameter list
- All services that can be passed around implement the IUnderlyingService interface, and that includes a method called IUnderlyingService.getUnderlyingArtefacts, which allows modules to recursively declare their dependencies (within the context of system JARs - all user JARs must be manually specified).
- IHarvestContext getContextSignature - a string that can be used to recreate a "remote copy" of the IHarvestContext, see below.
- In the separate process (normally) spawned by the above harvest technology calls (either by spawning a process, making an API call to YARN etc etc) and makes the result of getContextSignature available, ContextUtils.getHarvestContext(context_signature) is called to build a copy of the IHarvestContext.
- The context signature includes all configuration relating to any of the data services used in the remote job. However, IUnderlyingService.createRemoteConfig can be used to transform the configuration that is distributed.
- The harvest technology will normally call some combination of:
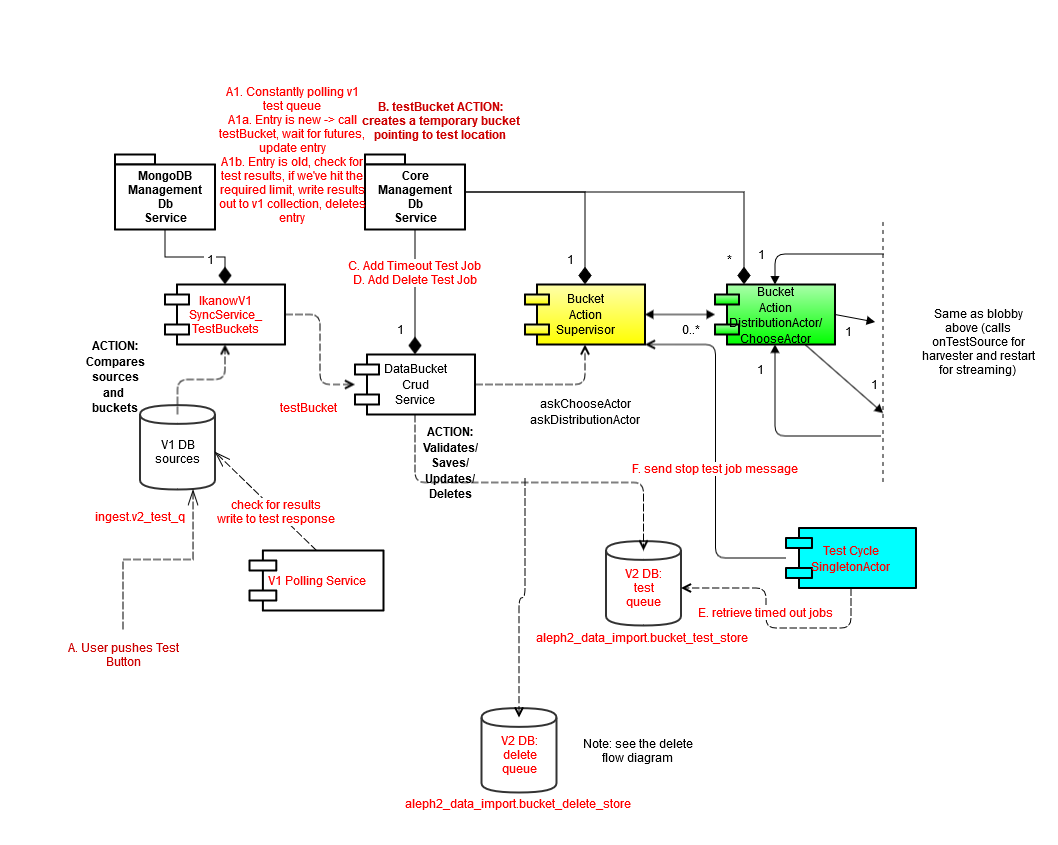
Test buckets
Same as above, with slight variation at end to kill tests after some time
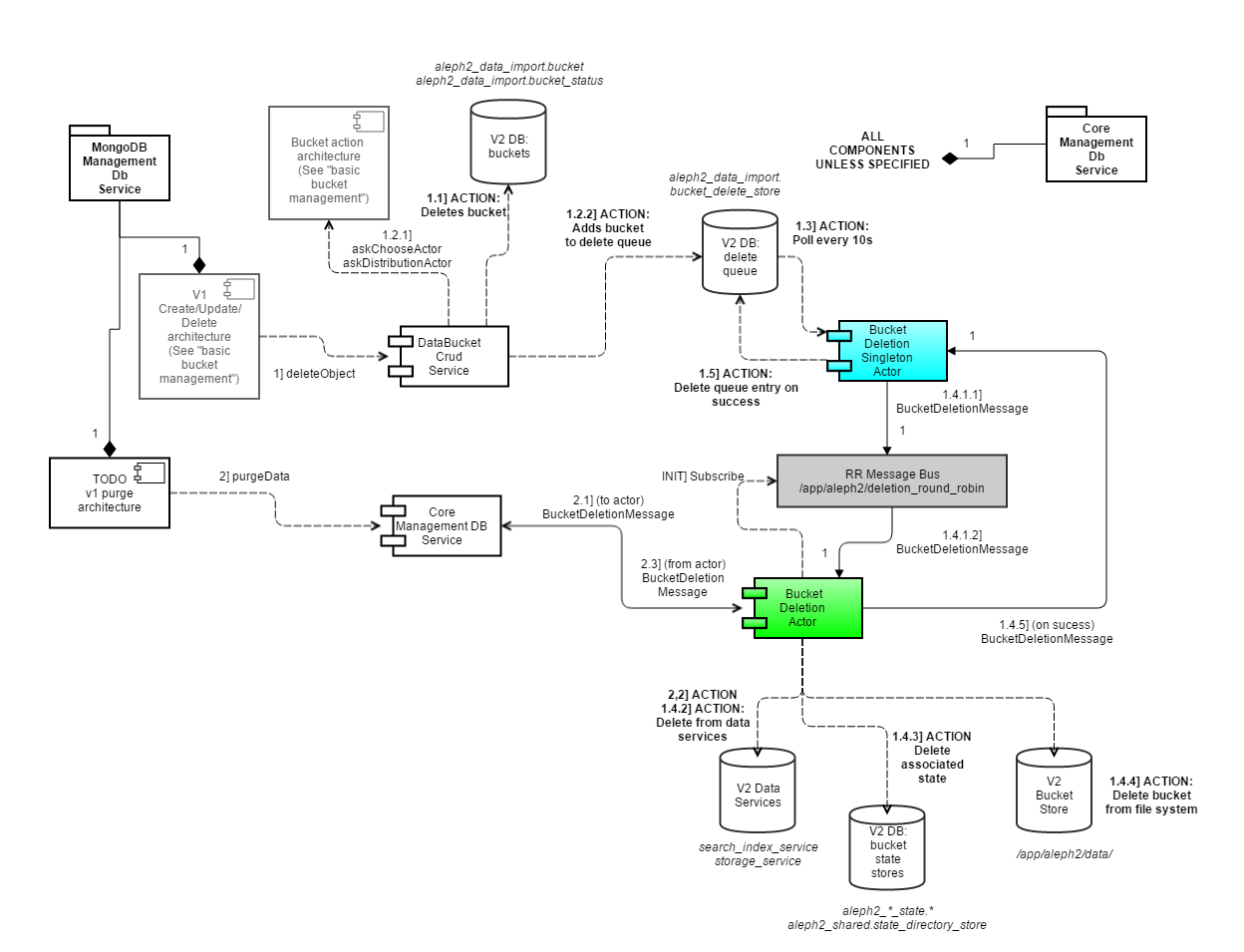
Data governance threads
Analytic engine design
The basic idea is that there are two worker actors:
- analytics.actors.DataBucketAnalyticsChangeActor, which is very similar to the harvest engine but which in addition relays all its messages (and generates/sends other sync messages) to...
- analytics.actors.AnalyticsTriggerWorkerActor, which handles when to convert an analytic thread between active and inactive states
- (AnalyticsTriggerWorkerActor in turn can send messages back to AnalyticsTriggerWorkerActor telling it what to do)
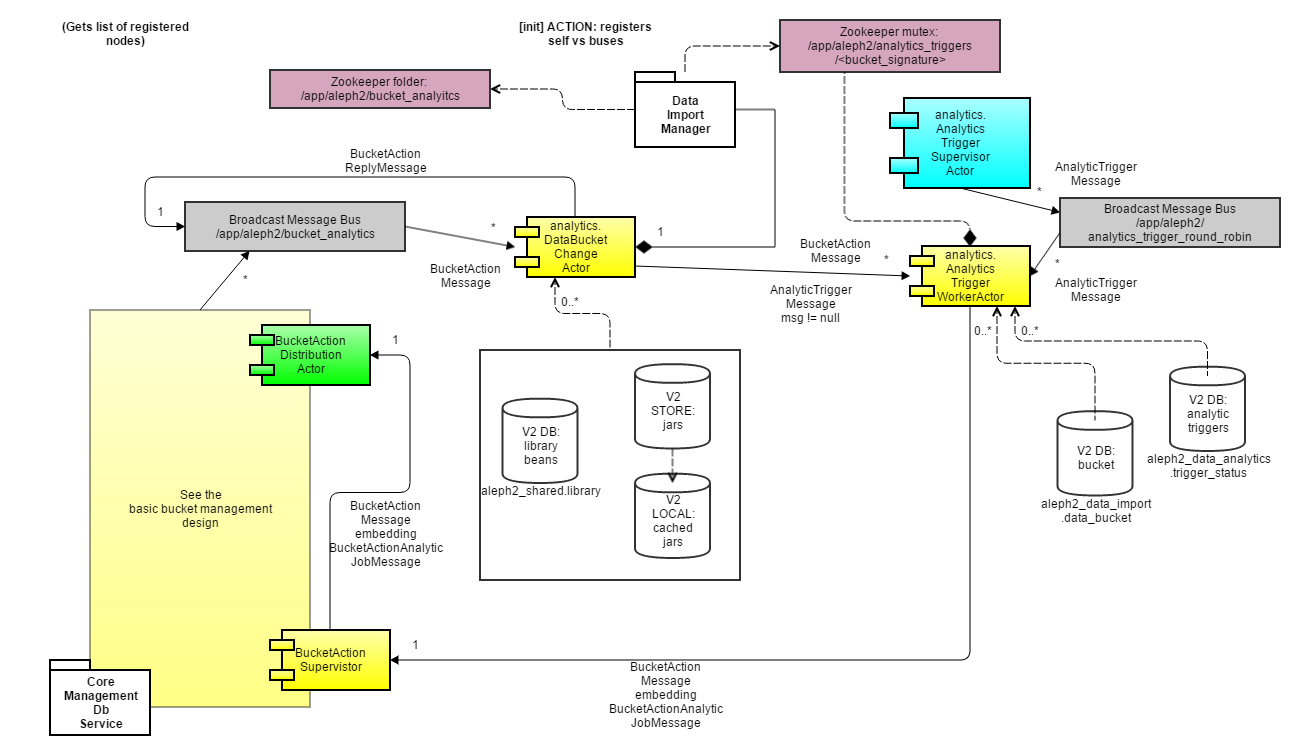
Message types (see top level method):
- (Before any of the messages are invoked, IAnalyticsTechnologyModule.onInit is called, and IAnalyticsContext.setBucket is called. Further before any job-specific operation described below, IAnalyticsContext.setJob is called)
- BucketActionOfferMessage
- (same as for the harvester design docs - the only difference is that by default harvester modules will lock buckets to a set of nodes once canRunOnThisNode has replied, whereas analytics by default will not - for "external process" analytic jobs (unlike say YARN jobs) this needs to be overridden in the bucket)
- DeleteBucketActionMessage
- When a bucket is deleted from the CMDB
- Generates an AnayticsTriggerMessage (stopping) and sends to AnalyticsTriggerWorkerActor
- For each job calls IAnalyticsTechnologyModule.stopAnalyticJob
- Then calls IAnalyticsTechnologyModule.onDeleteThread
- NewBucketActionMessage
- When a bucket is first created
- First calls IAnalyticsTechnologyModule.onNewThread
- (it is recommended that IAnalyticsTechnologyModule validate the entire analytic thread here, eg all jobs - in order to avoid "runtime failures" - see for example IBatchEnrichmentModule.validateModule)
- Relayed to the AnalyticsTriggerWorkerActor (which will generate all the triggers)
- If not suspended
- If the bucket is manual (vs triggered) or contains streaming jobs, then
- call IAnalyticsTechnologyModule.onThreadExecute
- get a list of jobs that aren't dependent on other jobs, and for each job:
- calls IAnalyticsTechnologyModule.startAnalyticJob
- Generates an AnayticsTriggerMessage (starting) and sends to AnalyticsTriggerWorkerActor for each job successfully started
- If the bucket is manual (vs triggered) or contains streaming jobs, then
- (It's actually a bit more complicated than that due to various edge cases, see the code for details, the above is a good starting point for understanding what's happening)
- UpdateBucketActionMessage
- When a bucket is changed (or is suspended/unsuspended)
- First calls IAnalyticsTechnologyModule.onUpdatedThread
- (it is recommended that IAnalyticsTechnologyModule validate the entire analytic thread here, eg all jobs - in order to avoid "runtime failures" - see for example IBatchEnrichmentModule.validateModule)
- As for NewBucketActionMessage, gets a list of jobs that immediately start/stop on user actions
- If bucket is suspended, calls IAnalyticsTechnologyModule.suspendAnalyticJob for each such job (and call IAnalyticsContext.completeJobOutput, which handles tidying up transient outputs)
- If bucket is not supended calls IAnalyticsTechnologyModule.resumeAnalyticJob for each such job For each successful resume/suspend, sends a AnayticsTriggerMessage (starting or stopping) and sends to AnalyticsTriggerWorkerActor
- (It's actually a bit more complicated than that due to various edge cases, see the code for details, the above is a good starting point for understanding what's happening)
- PurgeBucketActionMessage
- When the purge bucket API call is made (eg via "delete docs" in the V1 UI)
- calls IAnalyticsTechnologyModule.onPurge
- TestBucketActionMessage
- When the test bucket API is called (see below). Note that the test end is indicated by by an UpdateBucketActionMessage with suspended set to true
- call IAnalyticsTechnologyModule.onTestThread
- Then basically mirrors NewBucketActionMessage except calling IAnalyticsTechnologyModule.startAnalyticJobTest (instead of startAnalyticJob)
- PollFreqBucketActionMessage
- For unsuspended buckets, this message is generated once every bucket.poll_frequency period (Eg "1 minute") call IAnalyticsTechnologyModule.onPeriodicPoll
- BucketActionAnalyticJobMessage
- These are generated by the AnalyticsTriggerWorkerActor whenever a trigger event occurs, with the following JobMessageType/logic:
- JobMessageType.check_completion
- Check the progress of an active job
- Results in a call to IAnalyticsTechnologyModule.checkAnalyticJobProgress
- For completed jobs, generates an AnayticsTriggerMessage (completed) and sends to AnalyticsTriggerWorkerActor
- (and call IAnalyticsContext.completeJobOutput)
- JobMessageType.starting (msg.jobs==null)
- An analytic thread within a bucket has been activated
- call IAnalyticsTechnologyModule.onThreadExecute
- For each job without a dependency, calls IAnalyticsTechnologyModule.startAnalyticJob
- Generates an AnayticsTriggerMessage (starting) and sends to AnalyticsTriggerWorkerActor for each job successfully started
- (It's actually a bit more complicated than that due to various edge cases, see the code for details, the above is a good starting point for understanding what's happening)
- JobMessageType.starting (msg.jobs!=null)
- One or more jobs inside an already active analytic thread need to be started (because their dependencies completed successfully)
- For each listed job, call IAnalyticsTechnologyModule.startAnalyticJob
- (TODO: Unlike the previous version, doesn't send any AnayticsTriggerMessage messages, not sure why - you'd have to follow the code a bit more)
- JobMessageType.stopping (msg.jobs==null)
- Called when the job dependency tree has finished, ie there are no more jobs to run.
- Calls IAnalyticsContext.completeBucketOutput (ensures that ping/pong buffers are switched over for jobs with non-persistent output)
- Calls IAnalyticsTechnologyModule.onThreadComplete
- JobMessageType.stopping (msg.jobs!=null)
- Called when a bucket is suspended, so all its running jobs need to be suspended
- Calls IAnalyticsTechnologyModule.suspendAnalyticJob for each listed job
- JobMessageType.deleting * Called when a bucket is being deleted, so all its jobs should be suspended * Calls IAnalyticsTechnologyModule.suspendAnalyticJob for each listed job
- (Note that each IAnalyticsTechnologyModule.startAnalyticJob call needs to call IAnalyticsContext.getAnalyticsContextSignature in order to initialize it)
The AnalyticsTriggerWorkerActor performs all the functionality you'd expect, driven by various messages generated either regularly by AnalyticsTriggerSupervisorActor, or by DataBucketAnalyticsChangeActor when something changes:
- BucketActionMessage
- If DeleteBucketActionMessage:
- Deletes all stored triggers for this bucket
- Otherwise:
- Updates all stored triggers for this bucket
- If DeleteBucketActionMessage:
- AnalyticTriggerMessage
- if trigger generated from DataBucketAnalyticsChangeActor (null != bucket_action_message)
- Gets a list of active jobs
- For each active job, sends a AnayticsTriggerMessage(check_completion) to a DataBucketAnalyticsChangeActor
- For each inactive bucket:
- Retrieves all the triggers, instanciates a trigger checker for AnalyticStateTriggerCheckFactory, runs that trigger and updates in-memory copy of trigger
- Runs through the boolean trigger tree (creating it if it's automatic) and decide whether to activate the bucket
- (ie send AnayticsTriggerMessage(staring, jobs==null) to a DataBucketAnalyticsChangeActor)
- For each inactive job, checks the dependency tree vs completed active jobs for that bucket and starts jobs if necessary
- (ie send AnayticsTriggerMessage(starting) to a DataBucketAnalyticsChangeActor)
- For active buckets, if there are no currently active jobs, and no recent job triggers, then stop the job
- (ie send AnayticsTriggerMessage(stopping) to a DataBucketAnalyticsChangeActor) Updates all the trigger counts/statuses in the underlying store
- Gets a list of active jobs
- if trigger generated from AnalyticsTriggerSupervisorActor (null != trigger_action_message)
- BucketActionAnalyticJobMessage (type == JobMessageType.starting)
- Creates an active record in trigger store for the specified bucket (msg.jobs == null), or the jobs (msg.jobs != null) and the bucket
- BucketActionAnalyticJobMessage (type == JobMessageType.stopping)
- Removes the active bucket/job records.
- Also checks for whether the completion of each job is an "internal trigger" to another job (ie if another job has the stopping one as its dependency)
- BucketActionAnalyticJobMessage (type == JobMessageType.deleting) Remove active bucket/job records
- BucketActionAnalyticJobMessage (type == JobMessageType.starting)
- if trigger generated from DataBucketAnalyticsChangeActor (null != bucket_action_message)
- (Note: there's lots of references in the trigger worker code to "locked_to_host", which was intended to handle different versions of the same job running on different nodes independently (or something!) - in practice the underlying functionality was never enabled so the code paths with lock_to_host != Optional.empty() was never completed/tested and should just be ignored)
- (Note that all bucket operations are protected by a ZK mutex to allow the supervisor to distribute the trigger processing amongst different nodes. Currently this is disabled (and untested), and the supervisor therefore only sends trigger messages to its own node - to scale significantly, this would need to be finished up (missing: creation/deletion of the ZK mutexes when buckets are created/deleted) and tested; there is currently a very small chance of race conditions if a trigger (on the supervisor node) races with a relay/trigger message from a bucket change actor).
A few noteworthy things relating to how analytic contexts are created:
- The JARs specified in all the various shared library locations (eg batch_enrichment_configs[].library_names_or_ids/analytic_thread.jobs[].library_names_or_ids) are cached and added to a separate classloader
- (The above IAnalyticsTechnologyModule calls are called in that classloader thread context)
- A separate IAnalyticsContext is created for each bucket, and passed into the above IAnalyticsTechnologyModule calls
- The analytics technology will normally call some combination of:
- IAnalyticsContext getAnalyticsLibraries - a list of the user specified shared libraries
- IAnalyticsContext.getAnalyticsContextLibraries - a list of the system libraries either needed by the system (eg aleph2_data_model.jar), or needed by one of the services specified in the buckets (eg aleph2_search_index_service.jar if enabled), or manually specified in the parameter list
- All services that can be passed around implement the IUnderlyingService interface, and that includes a method called IUnderlyingService.getUnderlyingArtefacts, which allows modules to recursively declare their dependencies (within the context of system JARs - all user JARs must be manually specified).
- IAnalyticsContext.getAnalyticsSignature - a string that can be used to recreate a "remote copy" of the IAnalyticsContext , see below.
- In the separate process (normally) spawned by the above analytics technology calls (either by spawning a process, making an API call to YARN etc etc) and makes the result of getContextSignature available, ContextUtils.getAnalyticsContext(context_signature) is called to build a copy of the IAnalyticsContext .
- The context signature includes all configuration relating to any of the data services used in the remote job. However, IUnderlyingService.createRemoteConfig can be used to transform the configuration that is distributed.
- The analytics technology will normally call some combination of:
- Note finally that when run in batch or streaming modules, IEnrichmentModuleContext is used, which is normally just a thin wrapper around IAnalyticsContext (and is created using ContextUtils.getEnrichmentContext)