NAT 技术的工作原理和特点 - Huoke/Linux-net-Programma GitHub Wiki
NAT 技术的工作原理和特点
NAT名字很准确,网络地址转换,就是替换IP报文头部的地址信息。NAT通常部署在一个组织的网络出口位置,通过将内部网络IP地址替换为出口的IP地址提供公网可达性和上层协议的连接能力。那么,为什么是内部网络IP地址?
RFC1918规定了三个保留地址段落:10.0.0.0——10.255.255.255、172.16.0.0——172.31.255.255、192.168.0.0——192.168.255.255。这三个范围分别处于A,B,C类的地址段,不向特定的用户分配,被IANA作为私有地址保留。这些地址可以在任何组织或企业内部使用,和其他Internet地址的区别就是仅仅能在内部使用,不能作为全球路由地址。这就是说,出了组织的管理范围这些地址就不再有意义,无论是作为源地址,还是目的地址。对于一个封闭的组织,如果其网络不连接到Internet,就可以使用这些地址而不用向IANA提出申请,而在内部的路由管理和报文传递方式与其他网络没有差异。
对于有Internet访问需求而内部又使用私有地址的我网络,就要在组织的出口位置部署NAT网关,在报文离开私有网络进入Internet时,将源IP地址替换为公网地址(通常是出口设备的接口地址)。一个访问外网的请求到达目的地以后,表现为由本组织出口设备发起的请求,因此被请求的服务器端可将响应由Internet发回出口网关。出口网关再讲目的地址替换为私网的源主机地址,发回内部。这样一次由私有网络主机向公网服务器的请求和响应就在通信量端均无感知的情况下完成了。依据这种模型,数量庞大的内网主机就不再需要公有IP地址了。
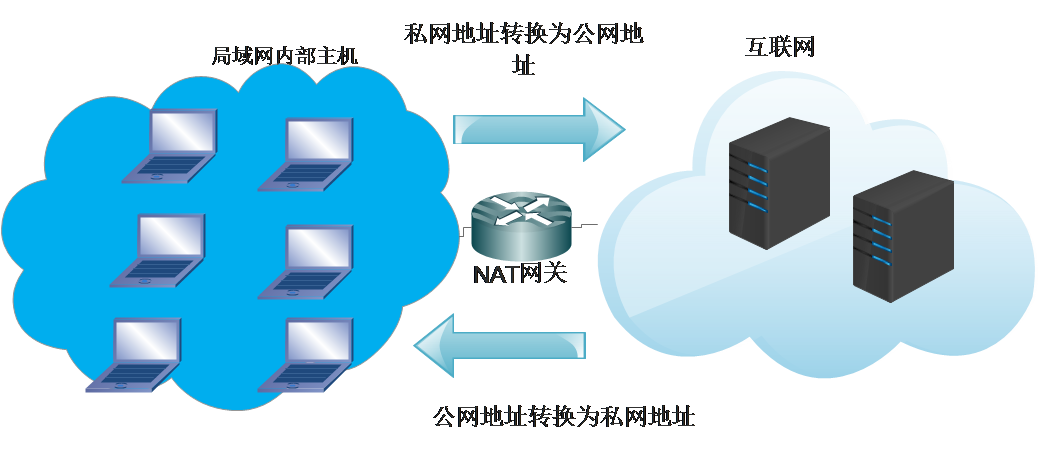
我们一般使用私网IP作为局域网内部的主机标识,使用公网IP作为互联网上通信的标识
在整个NAT转换过程中,最关键的流程有以下几点:
- 网络被分为私网和公网两个部分,NAT网关设置在私网到公网的路由出口位置,双向流量必须都要经过NAT网关
- 网络访问只能先由私网侧发起,公网无法主动访问私网主机
- NAT网关再两个访问方向上完成两次地址的转换或翻译,出方向做源信息替换,如方向做目的信息替换;
- NAT网关的存在对通信双方是保持透明的
- NAT网关为了实现双向翻译的功能,需要维护一张关联表,把会话的信息保存下来。
企业实现NAT的常用方式
静态NAT
如果一个内部主机唯一占用一个公网IP,这种方式被称为一对一模型。此种方式下,转换上层协议就是不必要的,因为一个公网IP就能唯一对应一个内部主机。显然这种方式对节约公网IP没有太大意义,主要是为了实现一些特殊的组网需求。比如用户希望隐藏内部主机的真实IP,或者实现两个IP地址重叠网络的通信。
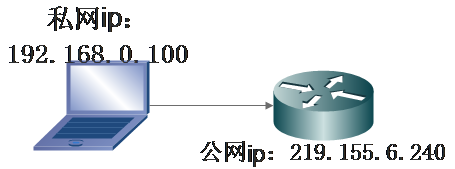
动态NAT
它能够将未注册的IP地址映射到注册IP地址池中的一个地址。不像使用静态NAT那样,你无需静态地配置路由器,使其将每个内部地址映射到一个外部地址、但必须有足够的公有Internet IP地址,让连接到Internet的主机能够同时发送和接收分组。
动态转换是指将北部网络的私有IP地址转换为公用IP地址,IP地址对并不是一一对应的,而是随机的。所有被管理员授权访问外网的私有IP地址可随机转换为任何指定的公有IP地址,也就是说,只要指定那些内部地址可以进行转换,以及用那些合法地址作为外部地址时,就可以进行动态转换,每个地址的租用时间都有限制,这样,当 ISP (互联网服务提供商,即向广大用户综合提供互联网接入业务、信息业务和增值业务的电信运营商) 提供的合法IP地址略少于网络内部的计算机数量时,可以采用动态转换的方式。
端口多路复用(PAT) 也叫NAT重载(经常应用到实际中)
通过使用端口多路复用,可以达到一个公网地址对应多个私有地址的一对多转换,在这种工作方式下,内部网络的所有主机均可共享一个合法外部IP地址实现对Internet的访问,来自不同内部主机的流量用不同的随机端口进行标示,从而可以最大限度地节约IP地址资源。同时,又可隐藏网络内部的所有主机,有效避免来自Internet的攻击,因此,目前网络中应用最多的就是端口多路复用方案。
面对私网内部数量庞大的主机,如果NAT只进行IP地址的简单替换,就会产生一个问题:当有多个内部主机去访问同一个服务器时,从返回的信息不足以区分响应应该转发到哪个内部主机。此时,需要NAT设备根据传输层信息或其他上层协议去区分不同的会话,并且可能要对上层协议的标识进行转换,比如TCP或UDP端口号。这样NAT网关就可以将不同的内部连接访问映射到同一公网IP的不同传输层端口,通过这种方式实现公网IP的复用和解复用。这种方式也被称为端口转换PAT、NAPT或IP伪装,但更多时候直接被称为NAT,因为它是最典型的一种应用模式。
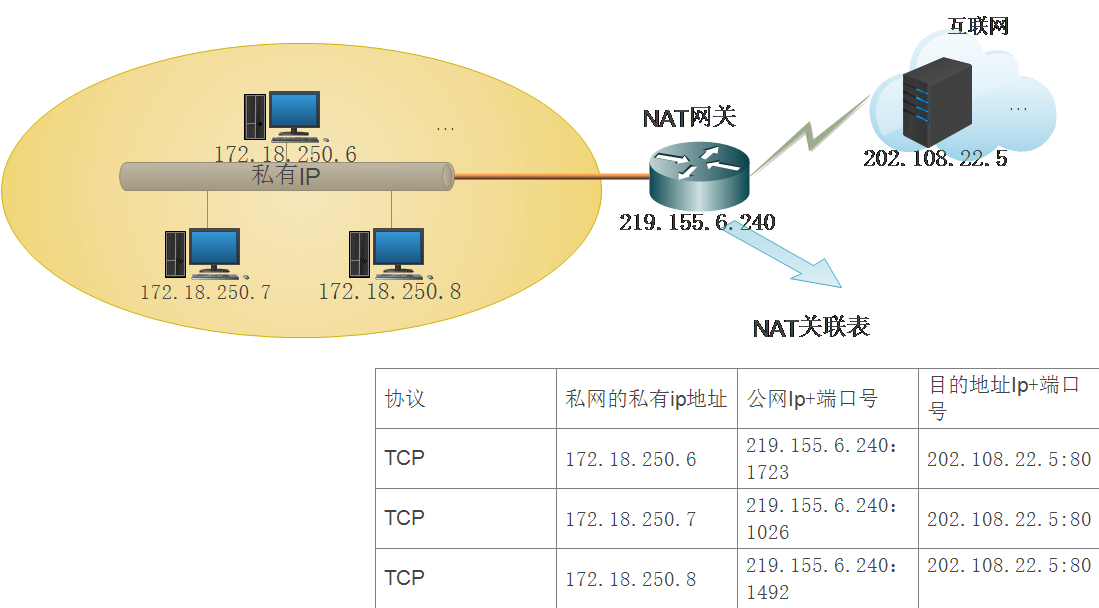
举个例子,客户端172.18.250.6和百度服务器202.108.22.5通信,172.18.250.6发送数据时,先转换为219.155.6.240:1723(任意>1024的随机端口),然后再利用这个身份发送数据给百度服务器,然后百度服务器回应数据并发送给219.155.6.240:1723,NAT网关检查自己的关联表,意识到这是自己地私网中172.18.250.6的数据包,然后把这个数据发送给客户端。 也就是说,我们利用端口号的唯一性实现了公网ip转换为私网ip的这一步。PAT(NAT重载)能够使用传输层端口号来标识主机,因此,从理论上说,最多可让大约65000台主机共用一个公有IP地址。
NAT技术的优缺点
优点
- 节省合法的公有IP地址
- 地址重叠时,提供 解决办法
- 网络发生变化时,避免重新编址(这个问题具有亲身体会,原本所在的实习单位搬迁,我们搬到了新的住处,网络环境发生了一些变化,但是由于nat技术的特点,我们局域网的地址并没有发生改变,我们依然使用着最初的编址方案)
NAT对我们来说最大的贡献就是帮助我们节省了大量的ip资源
缺点
先简单介绍下什么是IP的端到端通信
IP协议的一个重要贡献是把世界变得平等。在理论上,具有IP地址的每个站点在协议层面有相当的获取服务和提供服务的能力,不同的IP地址之间没有差异。人们熟知的服务器和客户机实际是在应用协议层上的角色区分,而在网络层和传输层没有差异。一个具有IP地址的主机既可以是客户机,也可以是服务器,大部分情况下,既是客户机,也是服务器。端到端对等看起来是很平常的事情,而意义并不寻常。但在以往的技术中,很多协议体系下的网络限定了终端的能力。正是IP的这个开放性,使得TCP/IP协议族可以提供丰富的功能,为应用实现提供了广阔平台。因为所有的IP主机都可以服务器的形式出现,所以通讯设计可以更加灵活。使用UNIX/LINUX的系统充分利用了这个特性,使得任何一个主机都可以建立自己的HTTP、SMTP、POP3、DNS、DHCP等服务。与此同时,很多应用也是把客户端和服务器的角色组合起来完成功能。例如在VoIP应用中,用户端向注册服务器登录自己的IP地址和端口信息过程中,主机是客户端;而在呼叫到达时,呼叫处理服务器向用户端发送呼叫请求时,用户端实际工作在服务器模式下。在语音媒体流信道建立过程后,通讯双向发送语音数据,发送端是客户模式,接收端是服务器模式。而在P2P的应用中,一个用户的主机既为下载的客户,同时也向其他客户提供数据,是一种C/S混合的模型。上层应用之所以能这样设计,是因为IP协议栈定义了这样的能力。试想一下,如果IP提供的能力不对等,那么每个通信会话都只能是单方向发起的,这会极大限制通信的能力。细心的读者会发现,前面介绍NAT的一个特性正是这样一种限制。没错,NAT最大的弊端正在于此——破坏了IP端到端通信的能力。
NAT的弊端
首先,NAT使IP会话的保持时效变短。因为一个会话建立后会在NAT设备上建立一个关联表,在会话静默的这段时间,NAT网关会进行老化操作。这是任何一个NAT网关必须做的事情,因为IP和端口资源有限,通信的需求无限,所以必须在会话结束后回收资源。通常TCP会话通过协商的方式主动关闭连接,NAT网关可以跟踪这些报文,但总是存在例外的情况,要依赖自己的定时器去回收资源。而基于UDP的通信协议很难确定何时通信结束,所以NAT网关主要依赖超时机制回收外部端口。通过定时器老化回收会带来一个问题,如果应用需要维持连接的时间大于NAT网关的设置,通信就会意外中断。因为网关回收相关转换表资源以后,新的数据到达时就找不到相关的转换信息,必须建立新的连接。当这个新数据是由公网侧向私网侧发送时,就会发生无法触发新连接建立,也不能通知到私网侧的主机去重建连接的情况。这时候通信就会中断,不能自动恢复。即使新数据是从私网侧发向公网侧,因为重建的会话表往往使用不同于之前的公网IP和端口地址,公网侧主机也无法对应到之前的通信上,导致用户可感知的连接中断。**NAT网关要把回收空闲连接的时间设置到不发生持续的资源流失,又维持大部分连接不被意外中断,是一件比较有难度的事情。**在NAT已经普及化的时代,很多应用协议的设计者已经考虑到了这种情况,所以一般会设置一个连接保活的机制,即在一段时间没有数据需要发送时,主动发送一个NAT能感知到而又没有实际数据的保活消息,这么做的主要目的就是重置NAT的会话定时器。
其次,NAT在实现上将多个内部主机发出的连接复用到一个IP上,这就使依赖IP进行主机跟踪的机制都失效了。如网络管理中需要的基于网络流量分析的应用无法跟踪到终端用户与流量的具体行为的关系。基于用户行为的日志分析也变得困难,因为一个IP被很多用户共享,如果存在恶意的用户行为,很难定位到发起连接的那个主机。即便有一些机制提供了在NAT网关上进行连接跟踪的方法,但是把这种变换关系连续起来也困难重重。**基于IP的用户授权不再可靠,因为拥有一个IP的不等于一个用户或主机。**一个服务器也不能简单把同一IP的访问视作同一主机发起的,不能进行关联。有些服务器设置有连接限制,同一时刻只接纳来自一个IP的有限访问(有时是仅一个访问),这会造成不同用户之间的服务抢占和排队。有时服务器端这样做是出于DOS攻击防护的考虑,因为一个用户正常情况下不应该建立大量的连接请求,过度使用服务资源被理解为攻击行为。但是这在NAT存在时不能简单按照连接数判断。
总之,缺点大概如下:
- 无法进行端到端的IP跟踪(破坏了段对端通信的平等性)
- 很多应用层协议无法识别(比如ftp协议)
NAT穿越技术
前面解释了NAT的弊端,为了解决IP端到端应用在NAT环境下遇到的问题,网络协议的设计者们创造了各种武器来进行应对。但遗憾的是,这里每一种方法都不完美,还需要在内部主机、应用程序或者NAT网关上增加额外的处理。
应用层网管(ALG)
前面我们已经介绍到了,NAT实现了对UDP或TCP报文头中的的IP地址及端口转换功能,但对应用层数据载荷中的字段无能为力(也就是净载中的数据无法修改),在许多应用层协议中,比如多媒体协议(H.323、SIP等)、FTP、SQLNET等,TCP/UDP载荷中带有地址或者端口信息,这些内容不能被NAT进行有效的转换,就可能导致问题。也就是说,NAT只是将数据包的包头的ip地址和端口号进行了转换,但是没有对包内数据中的ip地址和端口号进行转换于是我们开始设想能不能使用一种行之有效的方法保证包头的ip和端口号与包中数据里的Ip地址和端口号都转化为公网的ip地址和端口号。
ALG的实际应用
对于ALG的实现机制还是不清楚,如果有懂的大佬,推荐下书籍(呵呵)
下面我们举个FTP传输的例子来简单介绍一下ALG的实际应用
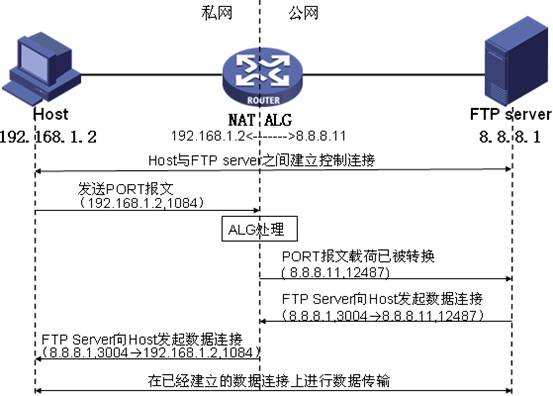
图中私网侧的主机要访问公网的FTP服务器。
NAT设备上配置了私网地址192.168.1.2到公网地址8.8.8.11的映射,实现地址的NAT转换,以支持私网主机对公网的访问。组网中,若没有ALG对报文载荷的处理,私网主机发送的PORT报文到达服务器端后,服务器无法根据私网地址进行寻址,也就无法建立正确的数据连接。整个通信过程包括如下四个阶段:
- 私网主机和公网FTP服务器之间通过TCP三次握手成功建立控制连接。
- 控制连接建立后,私网主机向FTP服务器发送PORT报文,报文中携带私网主机指定的数据连接的目的地址和端口,用于通知服务器使用该地址和端口和自己进行数据连接。
- PORT报文在经过支持ALG特性的NAT设备时,报文载荷中的私网地址和端口会被转换成对应的公网地址和端口。即设备将收到的PORT报文载荷中的私网地址192.168.1.2转换成公网地址8.8.8.11,端口1084转换成12487。
- 公网的FTP服务器收到PORT报文后,解析其内容,并向私网主机发起数据连接,该数据连接的目的地址为8.8.8.11,目的端口为12487(注意:一般情况下,该报文源端口为20,但由于FTP协议没有严格规定,有的服务器发出的数据连接源端口为大于1024的随机端口,如本例采用的是wftpd服务器,采用的源端口为3004)。由于该目的地址是一个公网地址,因此后续的数据连接就能够成功建立,从而实现私网主机对公网服务器的访问。
NAT技术(一、二、三、四、五) 系列:https://blog.51cto.com/wwwcisco/category1.html
CCNA学习笔记之NAT:http://sweetpotato.blog.51cto.com/533893/1392884 网络地址转换NAT原理及应用:http://blog.csdn.net/xiaofei0859/article/details/6630467 NAT技术基本原理与应用:http://www.cnblogs.com/dongzhuangdian/p/5105844.html NAT地址转换原理全攻略:http://blog.csdn.net/lycb_gz/article/details/12079455 NAT基本结构和分类:http://blog.csdn.net/lycb_gz/article/details/11999459