anyMissing_subset - HenrikBengtsson/matrixStats GitHub Wiki
matrixStats: Benchmark report
This report benchmark the performance of anyMissing() on subsetted computation.
> rvector <- function(n, mode = c("logical", "double", "integer"), range = c(-100, +100), na_prob = 0) {
+ mode <- match.arg(mode)
+ if (mode == "logical") {
+ x <- sample(c(FALSE, TRUE), size = n, replace = TRUE)
+ } else {
+ x <- runif(n, min = range[1], max = range[2])
+ }
+ storage.mode(x) <- mode
+ if (na_prob > 0)
+ x[sample(n, size = na_prob * n)] <- NA
+ x
+ }
> rvectors <- function(scale = 10, seed = 1, ...) {
+ set.seed(seed)
+ data <- list()
+ data[[1]] <- rvector(n = scale * 100, ...)
+ data[[2]] <- rvector(n = scale * 1000, ...)
+ data[[3]] <- rvector(n = scale * 10000, ...)
+ data[[4]] <- rvector(n = scale * 1e+05, ...)
+ data[[5]] <- rvector(n = scale * 1e+06, ...)
+ names(data) <- sprintf("n = %d", sapply(data, FUN = length))
+ data
+ }
> data <- rvectors(mode = mode)> x <- data[["n = 1000"]]
> idxs <- sample.int(length(x), size = length(x) * 0.7)
> x_S <- x[idxs]
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 3052231 163.1 5709258 305.0 5709258 305.0
Vcells 21597952 164.8 58462520 446.1 56666022 432.4
> stats <- microbenchmark(anyMissing_x_S = anyMissing(x_S), `anyMissing(x, idxs)` = anyMissing(x, idxs = idxs),
+ `anyMissing(x[idxs])` = anyMissing(x[idxs]), unit = "ms")Table: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on integer+n = 1000 data. The top panel shows times in milliseconds and the bottom panel shows relative times.
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 0.000775 | 0.000788 | 0.0008502 | 0.0008205 | 0.0008380 | 0.001761 |
| 2 | anyMissing(x, idxs) | 0.001375 | 0.001420 | 0.0014706 | 0.0014380 | 0.0014770 | 0.002159 |
| 3 | anyMissing(x[idxs]) | 0.002194 | 0.002326 | 0.0034593 | 0.0023715 | 0.0024305 | 0.108270 |
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 2 | anyMissing(x, idxs) | 1.774193 | 1.802031 | 1.729795 | 1.752590 | 1.762530 | 1.226008 |
| 3 | anyMissing(x[idxs]) | 2.830968 | 2.951777 | 4.068963 | 2.890311 | 2.900358 | 61.482112 |
Figure: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on integer+n = 1000 data. Outliers are displayed as crosses. Times are in milliseconds.

> x <- data[["n = 10000"]]
> idxs <- sample.int(length(x), size = length(x) * 0.7)
> x_S <- x[idxs]
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 3049258 162.9 5709258 305.0 5709258 305.0
Vcells 10485544 80.0 46770016 356.9 56666022 432.4
> stats <- microbenchmark(anyMissing_x_S = anyMissing(x_S), `anyMissing(x, idxs)` = anyMissing(x, idxs = idxs),
+ `anyMissing(x[idxs])` = anyMissing(x[idxs]), unit = "ms")Table: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on integer+n = 10000 data. The top panel shows times in milliseconds and the bottom panel shows relative times.
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 0.004139 | 0.0042000 | 0.0042818 | 0.0042680 | 0.0043060 | 0.005179 |
| 2 | anyMissing(x, idxs) | 0.009833 | 0.0098955 | 0.0101174 | 0.0099445 | 0.0100370 | 0.019449 |
| 3 | anyMissing(x[idxs]) | 0.015902 | 0.0161795 | 0.0167231 | 0.0163195 | 0.0164805 | 0.049985 |
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 2 | anyMissing(x, idxs) | 2.375695 | 2.356071 | 2.362919 | 2.330014 | 2.330934 | 3.755358 |
| 3 | anyMissing(x[idxs]) | 3.841991 | 3.852262 | 3.905667 | 3.823688 | 3.827334 | 9.651477 |
Figure: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on integer+n = 10000 data. Outliers are displayed as crosses. Times are in milliseconds.

> x <- data[["n = 100000"]]
> idxs <- sample.int(length(x), size = length(x) * 0.7)
> x_S <- x[idxs]
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 3049330 162.9 5709258 305.0 5709258 305.0
Vcells 10549104 80.5 37416013 285.5 56666022 432.4
> stats <- microbenchmark(anyMissing_x_S = anyMissing(x_S), `anyMissing(x, idxs)` = anyMissing(x, idxs = idxs),
+ `anyMissing(x[idxs])` = anyMissing(x[idxs]), unit = "ms")Table: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on integer+n = 100000 data. The top panel shows times in milliseconds and the bottom panel shows relative times.
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 0.040224 | 0.0443895 | 0.0533530 | 0.0466745 | 0.0573725 | 0.144915 |
| 2 | anyMissing(x, idxs) | 0.135243 | 0.1438805 | 0.1713973 | 0.1530420 | 0.1587210 | 0.451257 |
| 3 | anyMissing(x[idxs]) | 0.203309 | 0.2190730 | 0.2791400 | 0.2292040 | 0.2465105 | 0.885805 |
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 2 | anyMissing(x, idxs) | 3.362246 | 3.241318 | 3.212516 | 3.278921 | 2.766500 | 3.113943 |
| 3 | anyMissing(x[idxs]) | 5.054420 | 4.935244 | 5.231949 | 4.910690 | 4.296666 | 6.112583 |
Figure: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on integer+n = 100000 data. Outliers are displayed as crosses. Times are in milliseconds.
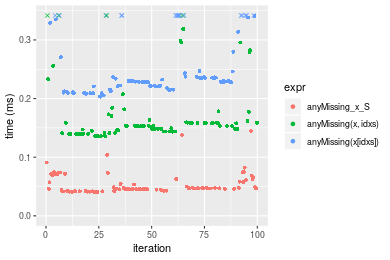
> x <- data[["n = 1000000"]]
> idxs <- sample.int(length(x), size = length(x) * 0.7)
> x_S <- x[idxs]
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 3049402 162.9 5709258 305.0 5709258 305.0
Vcells 11179153 85.3 37416013 285.5 56666022 432.4
> stats <- microbenchmark(anyMissing_x_S = anyMissing(x_S), `anyMissing(x, idxs)` = anyMissing(x, idxs = idxs),
+ `anyMissing(x[idxs])` = anyMissing(x[idxs]), unit = "ms")Table: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on integer+n = 1000000 data. The top panel shows times in milliseconds and the bottom panel shows relative times.
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 0.369494 | 0.4798705 | 0.5139672 | 0.486784 | 0.5081445 | 1.229963 |
| 2 | anyMissing(x, idxs) | 1.677564 | 2.2693975 | 2.7414527 | 2.416130 | 2.8599650 | 5.406851 |
| 3 | anyMissing(x[idxs]) | 2.798661 | 4.3687570 | 5.1272277 | 4.685953 | 5.0658840 | 15.620716 |
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 2 | anyMissing(x, idxs) | 4.540166 | 4.729187 | 5.333907 | 4.963455 | 5.628251 | 4.395946 |
| 3 | anyMissing(x[idxs]) | 7.574307 | 9.104033 | 9.975789 | 9.626350 | 9.969377 | 12.700151 |
Figure: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on integer+n = 1000000 data. Outliers are displayed as crosses. Times are in milliseconds.

> x <- data[["n = 10000000"]]
> idxs <- sample.int(length(x), size = length(x) * 0.7)
> x_S <- x[idxs]
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 3049474 162.9 5709258 305.0 5709258 305.0
Vcells 17479408 133.4 37416013 285.5 56666022 432.4
> stats <- microbenchmark(anyMissing_x_S = anyMissing(x_S), `anyMissing(x, idxs)` = anyMissing(x, idxs = idxs),
+ `anyMissing(x[idxs])` = anyMissing(x[idxs]), unit = "ms")Table: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on integer+n = 10000000 data. The top panel shows times in milliseconds and the bottom panel shows relative times.
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 5.684406 | 7.139483 | 8.507188 | 7.543172 | 10.68328 | 13.8445 |
| 2 | anyMissing(x, idxs) | 93.497479 | 112.713793 | 121.700595 | 120.517454 | 130.16848 | 155.5575 |
| 3 | anyMissing(x[idxs]) | 126.903110 | 136.767034 | 146.120593 | 143.976145 | 148.79085 | 363.5733 |
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 1.00000 | 1.00000 | 1.00000 | 1.00000 | 1.00000 | 1.00000 |
| 2 | anyMissing(x, idxs) | 16.44806 | 15.78739 | 14.30562 | 15.97702 | 12.18432 | 11.23604 |
| 3 | anyMissing(x[idxs]) | 22.32478 | 19.15643 | 17.17613 | 19.08695 | 13.92745 | 26.26120 |
Figure: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on integer+n = 10000000 data. Outliers are displayed as crosses. Times are in milliseconds.

> rvector <- function(n, mode = c("logical", "double", "integer"), range = c(-100, +100), na_prob = 0) {
+ mode <- match.arg(mode)
+ if (mode == "logical") {
+ x <- sample(c(FALSE, TRUE), size = n, replace = TRUE)
+ } else {
+ x <- runif(n, min = range[1], max = range[2])
+ }
+ storage.mode(x) <- mode
+ if (na_prob > 0)
+ x[sample(n, size = na_prob * n)] <- NA
+ x
+ }
> rvectors <- function(scale = 10, seed = 1, ...) {
+ set.seed(seed)
+ data <- list()
+ data[[1]] <- rvector(n = scale * 100, ...)
+ data[[2]] <- rvector(n = scale * 1000, ...)
+ data[[3]] <- rvector(n = scale * 10000, ...)
+ data[[4]] <- rvector(n = scale * 1e+05, ...)
+ data[[5]] <- rvector(n = scale * 1e+06, ...)
+ names(data) <- sprintf("n = %d", sapply(data, FUN = length))
+ data
+ }
> data <- rvectors(mode = mode)> x <- data[["n = 1000"]]
> idxs <- sample.int(length(x), size = length(x) * 0.7)
> x_S <- x[idxs]
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 3049555 162.9 5709258 305.0 5709258 305.0
Vcells 16036274 122.4 37416013 285.5 56666022 432.4
> stats <- microbenchmark(anyMissing_x_S = anyMissing(x_S), `anyMissing(x, idxs)` = anyMissing(x, idxs = idxs),
+ `anyMissing(x[idxs])` = anyMissing(x[idxs]), unit = "ms")Table: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on double+n = 1000 data. The top panel shows times in milliseconds and the bottom panel shows relative times.
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 0.000777 | 0.000803 | 0.0008492 | 0.000819 | 0.0008375 | 0.001774 |
| 2 | anyMissing(x, idxs) | 0.001413 | 0.001439 | 0.0014882 | 0.001454 | 0.0014830 | 0.002522 |
| 3 | anyMissing(x[idxs]) | 0.002303 | 0.002439 | 0.0028966 | 0.002568 | 0.0027000 | 0.030612 |
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 1.000000 | 1.00000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 2 | anyMissing(x, idxs) | 1.818533 | 1.79203 | 1.752553 | 1.775336 | 1.770746 | 1.421646 |
| 3 | anyMissing(x[idxs]) | 2.963964 | 3.03736 | 3.411141 | 3.135531 | 3.223881 | 17.255919 |
Figure: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on double+n = 1000 data. Outliers are displayed as crosses. Times are in milliseconds.

> x <- data[["n = 10000"]]
> idxs <- sample.int(length(x), size = length(x) * 0.7)
> x_S <- x[idxs]
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 3049618 162.9 5709258 305.0 5709258 305.0
Vcells 16046063 122.5 37416013 285.5 56666022 432.4
> stats <- microbenchmark(anyMissing_x_S = anyMissing(x_S), `anyMissing(x, idxs)` = anyMissing(x, idxs = idxs),
+ `anyMissing(x[idxs])` = anyMissing(x[idxs]), unit = "ms")Table: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on double+n = 10000 data. The top panel shows times in milliseconds and the bottom panel shows relative times.
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 0.004032 | 0.004152 | 0.0043787 | 0.0042080 | 0.0042875 | 0.018270 |
| 2 | anyMissing(x, idxs) | 0.009852 | 0.010059 | 0.0101976 | 0.0102005 | 0.0102715 | 0.011691 |
| 3 | anyMissing(x[idxs]) | 0.016944 | 0.018027 | 0.0185712 | 0.0183025 | 0.0185410 | 0.042988 |
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.0000000 |
| 2 | anyMissing(x, idxs) | 2.443452 | 2.422688 | 2.328944 | 2.424073 | 2.395685 | 0.6399015 |
| 3 | anyMissing(x[idxs]) | 4.202381 | 4.341763 | 4.241298 | 4.349453 | 4.324432 | 2.3529283 |
Figure: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on double+n = 10000 data. Outliers are displayed as crosses. Times are in milliseconds.

> x <- data[["n = 100000"]]
> idxs <- sample.int(length(x), size = length(x) * 0.7)
> x_S <- x[idxs]
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 3049690 162.9 5709258 305.0 5709258 305.0
Vcells 16140976 123.2 37416013 285.5 56666022 432.4
> stats <- microbenchmark(anyMissing_x_S = anyMissing(x_S), `anyMissing(x, idxs)` = anyMissing(x, idxs = idxs),
+ `anyMissing(x[idxs])` = anyMissing(x[idxs]), unit = "ms")Table: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on double+n = 100000 data. The top panel shows times in milliseconds and the bottom panel shows relative times.
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 0.036983 | 0.0371180 | 0.0403236 | 0.0375025 | 0.0398020 | 0.068180 |
| 2 | anyMissing(x, idxs) | 0.138132 | 0.1385075 | 0.1411397 | 0.1386980 | 0.1388735 | 0.311077 |
| 3 | anyMissing(x[idxs]) | 0.227166 | 0.2362010 | 0.3139094 | 0.3564825 | 0.3605265 | 0.375998 |
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 2 | anyMissing(x, idxs) | 3.735013 | 3.731545 | 3.500174 | 3.698367 | 3.489109 | 4.562584 |
| 3 | anyMissing(x[idxs]) | 6.142444 | 6.363516 | 7.784754 | 9.505566 | 9.058000 | 5.514784 |
Figure: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on double+n = 100000 data. Outliers are displayed as crosses. Times are in milliseconds.

> x <- data[["n = 1000000"]]
> idxs <- sample.int(length(x), size = length(x) * 0.7)
> x_S <- x[idxs]
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 3049763 162.9 5709258 305.0 5709258 305.0
Vcells 17086033 130.4 37416013 285.5 56666022 432.4
> stats <- microbenchmark(anyMissing_x_S = anyMissing(x_S), `anyMissing(x, idxs)` = anyMissing(x, idxs = idxs),
+ `anyMissing(x[idxs])` = anyMissing(x[idxs]), unit = "ms")Table: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on double+n = 1000000 data. The top panel shows times in milliseconds and the bottom panel shows relative times.
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 0.522342 | 0.6471455 | 0.6660328 | 0.666311 | 0.6850945 | 0.757113 |
| 2 | anyMissing(x, idxs) | 3.715565 | 4.5817680 | 4.7084413 | 4.678424 | 4.8384565 | 5.932567 |
| 3 | anyMissing(x[idxs]) | 6.331259 | 7.0339720 | 8.9550346 | 9.288386 | 9.5016535 | 16.537808 |
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 1.00000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 2 | anyMissing(x, idxs) | 7.11328 | 7.079966 | 7.069383 | 7.021381 | 7.062466 | 7.835775 |
| 3 | anyMissing(x[idxs]) | 12.12091 | 10.869228 | 13.445335 | 13.940015 | 13.869114 | 21.843249 |
Figure: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on double+n = 1000000 data. Outliers are displayed as crosses. Times are in milliseconds.

> x <- data[["n = 10000000"]]
> idxs <- sample.int(length(x), size = length(x) * 0.7)
> x_S <- x[idxs]
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 3049835 162.9 5709258 305.0 5709258 305.0
Vcells 26536516 202.5 44979215 343.2 56666022 432.4
> stats <- microbenchmark(anyMissing_x_S = anyMissing(x_S), `anyMissing(x, idxs)` = anyMissing(x, idxs = idxs),
+ `anyMissing(x[idxs])` = anyMissing(x[idxs]), unit = "ms")Table: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on double+n = 10000000 data. The top panel shows times in milliseconds and the bottom panel shows relative times.
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 5.888141 | 7.225792 | 8.73584 | 7.723072 | 10.87091 | 13.93323 |
| 2 | anyMissing(x, idxs) | 103.717287 | 151.267297 | 161.63545 | 163.366152 | 173.61495 | 220.41171 |
| 3 | anyMissing(x[idxs]) | 146.006209 | 173.591400 | 187.50270 | 181.606660 | 189.74241 | 416.62257 |
| expr | min | lq | mean | median | uq | max | |
|---|---|---|---|---|---|---|---|
| 1 | anyMissing_x_S | 1.00000 | 1.00000 | 1.00000 | 1.00000 | 1.00000 | 1.00000 |
| 2 | anyMissing(x, idxs) | 17.61461 | 20.93435 | 18.50257 | 21.15300 | 15.97060 | 15.81914 |
| 3 | anyMissing(x[idxs]) | 24.79666 | 24.02386 | 21.46362 | 23.51482 | 17.45414 | 29.90136 |
Figure: Benchmarking of anyMissing_x_S(), anyMissing(x, idxs)() and anyMissing(x[idxs])() on double+n = 10000000 data. Outliers are displayed as crosses. Times are in milliseconds.

R version 3.6.1 Patched (2019-08-27 r77078)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 18.04.3 LTS
Matrix products: default
BLAS: /home/hb/software/R-devel/R-3-6-branch/lib/R/lib/libRblas.so
LAPACK: /home/hb/software/R-devel/R-3-6-branch/lib/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] microbenchmark_1.4-6 matrixStats_0.55.0-9000 ggplot2_3.2.1
[4] knitr_1.24 R.devices_2.16.0 R.utils_2.9.0
[7] R.oo_1.22.0 R.methodsS3_1.7.1 history_0.0.0-9002
loaded via a namespace (and not attached):
[1] Biobase_2.45.0 bit64_0.9-7 splines_3.6.1
[4] network_1.15 assertthat_0.2.1 highr_0.8
[7] stats4_3.6.1 blob_1.2.0 robustbase_0.93-5
[10] pillar_1.4.2 RSQLite_2.1.2 backports_1.1.4
[13] lattice_0.20-38 glue_1.3.1 digest_0.6.20
[16] colorspace_1.4-1 sandwich_2.5-1 Matrix_1.2-17
[19] XML_3.98-1.20 lpSolve_5.6.13.3 pkgconfig_2.0.2
[22] genefilter_1.66.0 purrr_0.3.2 ergm_3.10.4
[25] xtable_1.8-4 mvtnorm_1.0-11 scales_1.0.0
[28] tibble_2.1.3 annotate_1.62.0 IRanges_2.18.2
[31] TH.data_1.0-10 withr_2.1.2 BiocGenerics_0.30.0
[34] lazyeval_0.2.2 mime_0.7 survival_2.44-1.1
[37] magrittr_1.5 crayon_1.3.4 statnet.common_4.3.0
[40] memoise_1.1.0 laeken_0.5.0 R.cache_0.13.0
[43] MASS_7.3-51.4 R.rsp_0.43.1 tools_3.6.1
[46] multcomp_1.4-10 S4Vectors_0.22.1 trust_0.1-7
[49] munsell_0.5.0 AnnotationDbi_1.46.1 compiler_3.6.1
[52] rlang_0.4.0 grid_3.6.1 RCurl_1.95-4.12
[55] cwhmisc_6.6 rappdirs_0.3.1 labeling_0.3
[58] bitops_1.0-6 base64enc_0.1-3 boot_1.3-23
[61] gtable_0.3.0 codetools_0.2-16 DBI_1.0.0
[64] markdown_1.1 R6_2.4.0 zoo_1.8-6
[67] dplyr_0.8.3 bit_1.1-14 zeallot_0.1.0
[70] parallel_3.6.1 Rcpp_1.0.2 vctrs_0.2.0
[73] DEoptimR_1.0-8 tidyselect_0.2.5 xfun_0.9
[76] coda_0.19-3 Total processing time was 1.3 mins.
To reproduce this report, do:
html <- matrixStats:::benchmark('anyMissing_subset')Copyright Dongcan Jiang. Last updated on 2019-09-10 20:33:34 (-0700 UTC). Powered by RSP.
<script> var link = document.createElement('link'); link.rel = 'icon'; link.href = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAACAAAAAgCAMAAABEpIrGAAAA21BMVEUAAAAAAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8AAP8BAf4CAv0DA/wdHeIeHuEfH+AgIN8hId4lJdomJtknJ9g+PsE/P8BAQL9yco10dIt1dYp3d4h4eIeVlWqWlmmXl2iYmGeZmWabm2Tn5xjo6Bfp6Rb39wj4+Af//wA2M9hbAAAASXRSTlMAAQIJCgsMJSYnKD4/QGRlZmhpamtsbautrrCxuru8y8zN5ebn6Pn6+///////////////////////////////////////////LsUNcQAAAS9JREFUOI29k21XgkAQhVcFytdSMqMETU26UVqGmpaiFbL//xc1cAhhwVNf6n5i5z67M2dmYOyfJZUqlVLhkKucG7cgmUZTybDz6g0iDeq51PUr37Ds2cy2/C9NeES5puDjxuUk1xnToZsg8pfA3avHQ3lLIi7iWRrkv/OYtkScxBIMgDee0ALoyxHQBJ68JLCjOtQIMIANF7QG9G9fNnHvisCHBVMKgSJgiz7nE+AoBKrAPA3MgepvgR9TSCasrCKH0eB1wBGBFdCO+nAGjMVGPcQb5bd6mQRegN6+1axOs9nGfYcCtfi4NQosdtH7dB+txFIpXQqN1p9B/asRHToyS0jRgpV7nk4nwcq1BJ+x3Gl/v7S9Wmpp/aGquum7w3ZDyrADFYrl8vHBH+ev9AUASW1dmU4h4wAAAABJRU5ErkJggg==" document.getElementsByTagName('head')[0].appendChild(link); </script>