Home - HenglinShi/LSTM_LIP_READING GitHub Wiki
#[2016-08-21]
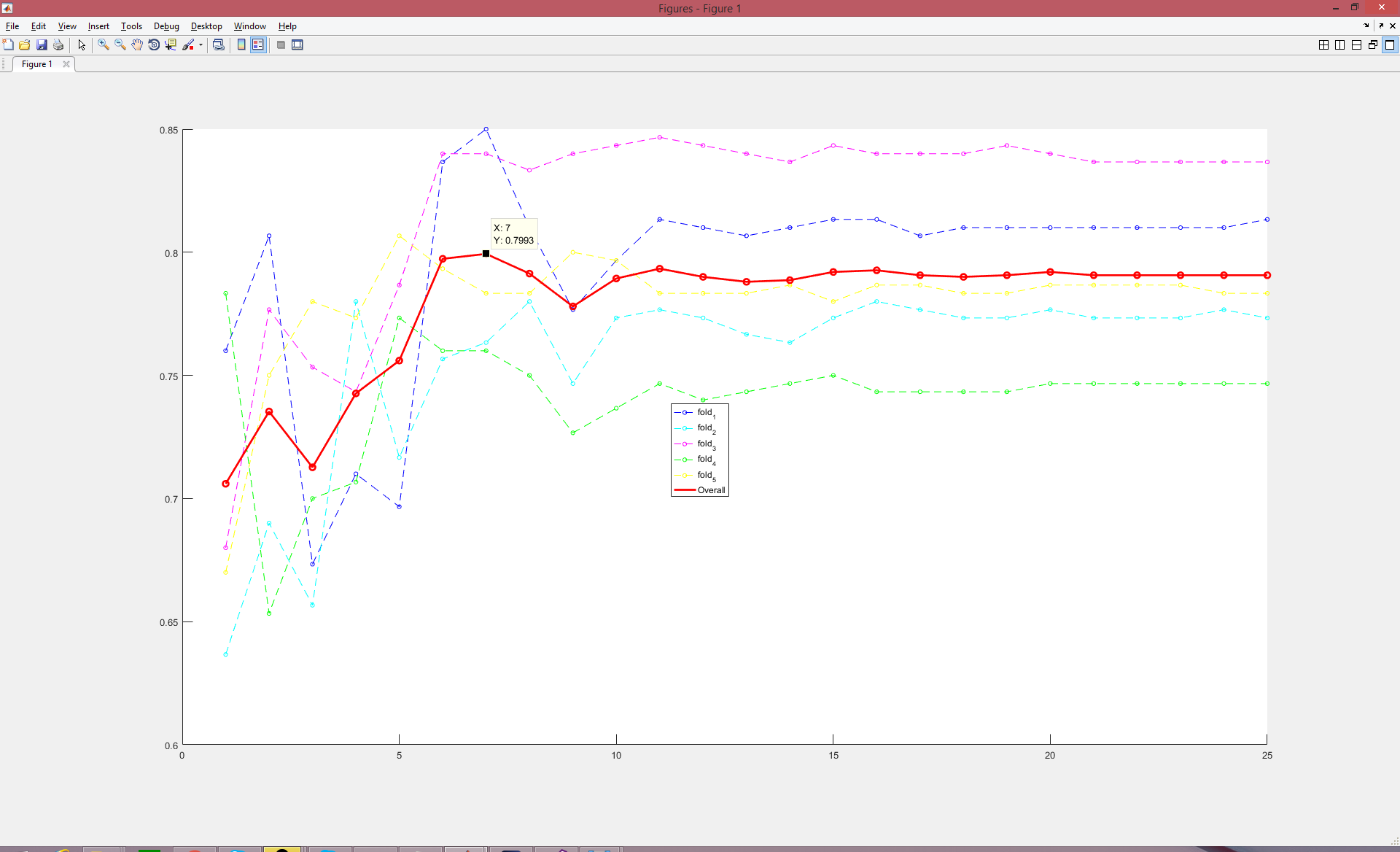
Input data are images from five angles
- Data sets used are smaller ones, whose size is around 25 by 25
- 5-folds Cross validation.
- Performance: 79.93%.
- Please check out the tag "Accuracy_79.93%25_5_inputs_5_folds_CV"
- Next step: seeing the performance of using smaller data set of the front images.
https://raw.githubusercontent.com/HenglinShi/LSTM_LIP_READING/Accuracy_79.93%25_5_inputs_5_folds_CV/LSTM_LIP_READING/Output/Performance_5inputs_20160821.png ![Performance] (https://raw.githubusercontent.com/HenglinShi/LSTM_LIP_READING/Accuracy_79.93%25_5_inputs_5_folds_CV/LSTM_LIP_READING/Output/Performance_5inputs_20160821.png)
{kind=link}
Front image 20 by 25.
perfromance : 81.87%, better than bigger images, why?
10 folds cross validation
- Training set: 47 * 30 = 1410
- Testing set: 5 * 30 = 150
- Result: Highest average 81.07%
(source picture can be found at https://github.com/HenglinShi/LSTM_LIP_READING/blob/Accuracy_81.07%25_10_folds/LSTM_LIP_READING/Output/Performance.png, which is bigger)

{kind=link}
Parameters
-
training batch_size: 60
-
testing once after every 2000 batches of training
-
testing batch_size: 20
-
150 batches for each testing
#2016-08-10 An new experiment: 72.68% Prepare a formal report
#2016-08-10 Redefining the network structure
- Adding a [reduction layer] ( https://github.com/HenglinShi/LSTM_LIP_READING/wiki/Reduction-layer)
- Result: 0.54529999903589499
- An update: 0.58130999974459374 (with max_iter = 100000, test_interval = 2000, and test_iter = 100)