18 03 Bagging and Random Forests - HannaAA17/Data-Scientist-With-Python-datacamp GitHub Wiki
01 Bagging
- One algorithm, but different subsets of the training set.
- Booststrap Aggregation.
- Uses a technique known as the boostrap. (Sample with replacement)
- Reduces variance of individual methods in the ensemble.
- Classification
- Aggregates predictions by majority voting
BaggingClassifier
- Regression
- Aggregates predictions through averaging
BaggingRegressor
An example of Bagging Classifier (Indian Liver Patient dataset)
- Define the bagging classifier
# Import DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
# Import BaggingClassifier
from sklearn.ensemble import BaggingClassifier
# Instantiate dt
dt = DecisionTreeClassifier(random_state=1)
# Instantiate bc
bc = BaggingClassifier(base_estimator=dt, n_estimators=50, random_state=1)
- Evaluate bagging performance
# Fit bc to the training set
bc.fit(X_train, y_train)
# Predict test set labels
y_pred = bc.predict(X_test)
# Evaluate acc_test
acc_test = accuracy_score(y_pred, y_test)
print('Test set accuracy of bc: {:.2f}'.format(acc_test)) # Test set accuracy of bc: 0.71 # higher than that of a single tree (0.63)
02 Out of Bag Evaluation
Bagging
- Some instances may be sampled several times for one model
- Other instances may not be sampled at all
Out Of Bag (OOB) instance
- Since OOB instances (37% on average) are not seen by a model during training, these can be used to estimate the performance of the ensemble without the need for cross-validation.
- Evaluate model(i) on the ith OOB samples, and calculate the average OOB score of all the models.
- set
obb_score = True
Example
# Import DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
# Import BaggingClassifier
from sklearn.ensemble import BaggingClassifier
# Instantiate dt
dt = DecisionTreeClassifier(min_samples_leaf=8, random_state=1)
# Instantiate bc
bc = BaggingClassifier(base_estimator=dt,
n_estimators=50,
oob_score=True,
random_state=1)
# Fit bc to the training set
bc.fit(X_train, y_train)
# Predict test set labels
y_pred = bc.predict(X_test)
# Evaluate test set accuracy
acc_test = accuracy_score(y_pred, y_test)
# Evaluate OOB accuracy
acc_oob = bc.oob_score_
# Print acc_test and acc_oob
print('Test set accuracy: {:.3f}, OOB accuracy: {:.3f}'.format(acc_test, acc_oob)) # Test set accuracy: 0.698, OOB accuracy: 0.704
03 Random Forests
- Base estimator: Decision Tree
- Each estimator is trained on a different boostrap sample having the same size as the training set
- RF introduces further randomization in the training of individual trees
- only 'd' features are sampled at each node without replacement
RandomForestClassifier & RandomForestRegressor
Feature Importance
- accessed using the attribute:
feature_importance_
Example
# Import RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
# Instantiate rf
rf = RandomForestRegressor(n_estimators=25,
random_state=2)
# Fit rf to the training set
rf.fit(X_train, y_train)
# Import mean_squared_error as MSE
from sklearn.metrics import mean_squared_error as MSE
# Predict the test set labels
y_pred = rf.predict(X_test)
# Evaluate the test set RMSE
rmse_test = MSE(y_test,y_pred)**(1/2)
# Print rmse_test
print('Test set RMSE of rf: {:.2f}'.format(rmse_test)). # Test set RMSE of rf: 51.97
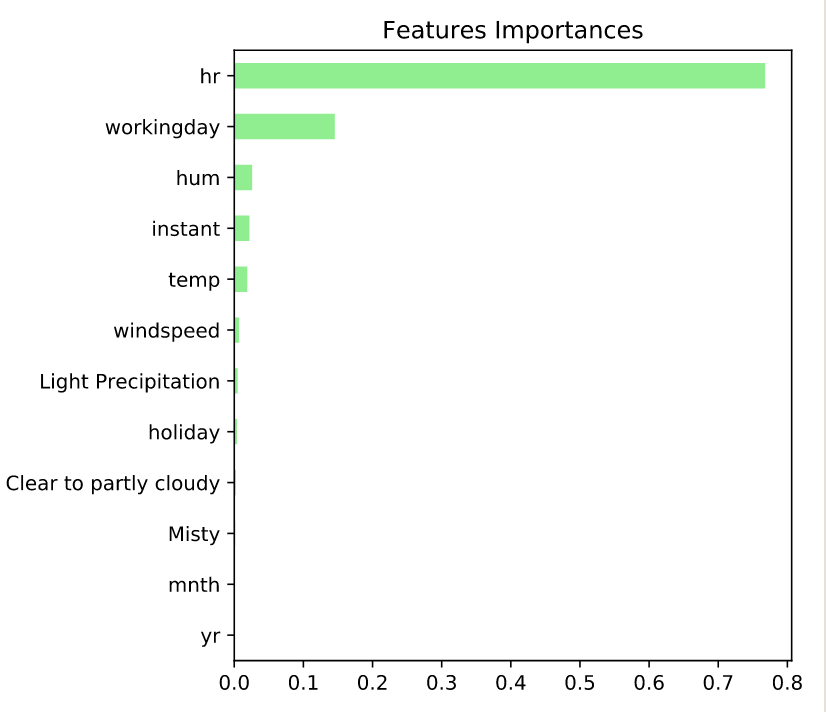
- Visualizing features importances
# Create a pd.Series of features importances
importances = pd.Series(data=rf.feature_importances_,
index= X_train.columns)
# Sort importances
importances_sorted = importances.sort_values()
# Draw a horizontal barplot of importances_sorted
importances_sorted.plot(kind='barh', color='lightgreen')
plt.title('Features Importances')
plt.show()