04a 04 Merging Ordered and Time Series Data - HannaAA17/Data-Scientist-With-Python-datacamp GitHub Wiki
Using merge_ordered()
- ordered data/time series
- Filling in missing values
- calling :
pd.merge_ordered(df1, df2) - forward fill: fills missing with previous value
fill_method='ffill'
# Use merge_ordered() to merge gdp and sp500 on year and date
gdp_sp500 = pd.merge_ordered(gdp, sp500, left_on='year', right_on='date',
how='left')
# Use merge_ordered() to merge gdp and sp500, interpolate missing value
gdp_sp500 = pd.merge_ordered(
gdp, sp500,
left_on='year', right_on='date', how='left',
fill_method='ffill' # forward_fill
)
# Use merge_ordered() to merge gdp and sp500, interpolate missing value
gdp_sp500 = pd.merge_ordered(gdp, sp500, left_on='year', right_on='date',
how='left', fill_method='ffill')
# Subset the gdp and returns columns
gdp_returns = gdp_sp500['gdp', 'returns'](/HannaAA17/Data-Scientist-With-Python-datacamp/wiki/'gdp',-'returns')
# Print gdp_returns correlation
print (gdp_returns.corr())
# Use merge_ordered() to merge inflation, unemployment with inner join
inflation_unemploy = pd.merge_ordered(
inflation, unemployment,
on='date', how='inner'
)
# Print inflation_unemploy
print(inflation_unemploy)
# Plot a scatter plot of unemployment_rate vs cpi of inflation_unemploy
inflation_unemploy.plot(kind='scatter', x='unemployment_rate', y='cpi')
plt.show()
merge_ordered() caution, multiple columns
- When using
merge_ordered()to merge on multiple columns, the order is important when you combine it with the forward fill feature. The function sorts the merge on columns in the order provided
date -> country
# Merge gdp and pop on country and date with fill
date_ctry = pd.merge_ordered(gdp, pop, on=['country','date'], fill_method='ffill')
output
date country gdp series_code_x pop series_code_y
0 2015-01-01 China 16700619.84 NYGDPMKTPSAKN 1371220000 SP.POP.TOTL
1 2015-01-01 US 4319400.00 NYGDPMKTPSAKN 320742673 SP.POP.TOTL
2 2015-04-01 China 16993555.30 NYGDPMKTPSAKN 320742673 SP.POP.TOTL
3 2015-04-01 US 4351400.00 NYGDPMKTPSAKN 320742673 SP.POP.TOTL
4 2015-07-01 China 17276271.67 NYGDPMKTPSAKN 320742673 SP.POP.TOTL
country -> date
# Merge gdp and pop on country and date with fill
date_ctry = pd.merge_ordered(gdp, pop, on=['country','date'], fill_method='ffill')
output
date country gdp series_code_x pop series_code_y
0 2015-01-01 China 16700619.84 NYGDPMKTPSAKN 1371220000 SP.POP.TOTL
1 2015-04-01 China 16993555.30 NYGDPMKTPSAKN 1371220000 SP.POP.TOTL
2 2015-07-01 China 17276271.67 NYGDPMKTPSAKN 1371220000 SP.POP.TOTL
3 2015-09-01 China 17547024.54 NYGDPMKTPSAKN 1371220000 SP.POP.TOTL
4 2016-01-01 China 17820789.83 NYGDPMKTPSAKN 1378665000 SP.POP.TOTL
Using merge_asof()
- Similar to a
merge_ordered()left_join- similar features as
merge_ordered()
- similar features as
- Match on the nearest key column and not exact matches.
- Merge 'on' colomns must be sorted.
direction='forward',direction='nearest'
# Use merge_asof() to merge jpm and wells
jpm_wells = pd.merge_asof(
jpm, wells, on='date_time', suffixes=('', '_wells'), direction='nearest'
)
# Use merge_asof() to merge jpm_wells and bac
jpm_wells_bac = pd.merge_asof(
jpm_wells, bac, on='date_time', suffixes=('_jpm', '_bac'), direction='nearest'
)
# Compute price diff
price_diffs = jpm_wells_bac.diff()
# Plot the price diff of the close of jpm, wells and bac only
price_diffs.plot(y=['close_jpm', 'close_wells', 'close_bac'])
plt.show()
# Merge gdp and recession on date using merge_asof()
gdp_recession = pd.merge_asof(gdp, recession, on='date')
# Create a list based on the row value of gdp_recession['econ_status']
is_recession = ['r' if s=='recession' else 'g' for s in gdp_recession['econ_status']]
# Plot a bar chart of gdp_recession
gdp_recession.plot(kind='bar', y='gdp', x='date', color=is_recession, rot=90)
plt.show()
Selecting data with .query()
.query('some selection statement')stocks.query('nike >= 90')stocks.query('nike > 90 and disney < 140')stocks_long.query('stock=="disney" or (stock=="nike" and close<90)')
Reshaping data with .melt()
- The melt method allow us to unpivot our dataset to long format
In [2]: ten_yr.head()
Out[2]:
metric 2007-02-01 2007-03-01 2007-04-01 2007-05-01 ... 2009-08-01 2009-09-01 2009-10-01 2009-11-01 2009-12-01
0 open 0.033491 -0.060449 0.025426 -0.004312 ... -0.006687 -0.046564 -0.032068 0.034347 -0.050544
1 high -0.007338 -0.040657 0.022046 0.030576 ... 0.031864 -0.090324 0.012447 -0.004191 0.099327
2 low -0.016147 -0.007984 0.031075 -0.002168 ... 0.039510 -0.035946 -0.050733 0.030264 0.007188
3 close -0.057190 0.021538 -0.003873 0.056156 ... -0.028563 -0.027639 0.025703 -0.056309 0.200562
[4 rows x 36 columns]
# Use melt on ten_yr, unpivot everything besides the metric column
bond_perc = ten_yr.melt(id_vars='metric', var_name='date', value_name='close')
In [3]: bond_perc.head()
Out[3]:
metric date close
0 open 2007-02-01 0.033491
1 high 2007-02-01 -0.007338
2 low 2007-02-01 -0.016147
3 close 2007-02-01 -0.057190
4 open 2007-03-01 -0.060449
In [4]: dji.head()
Out[4]:
date close
0 2007-02-01 0.005094
1 2007-03-01 -0.026139
2 2007-04-01 0.048525
3 2007-05-01 0.052007
4 2007-06-01 -0.016070
# Use query on bond_perc to select only the rows where metric=close
bond_perc_close = bond_perc.query('metric=="close"')
# Merge (ordered) dji and bond_perc_close on date with an inner join
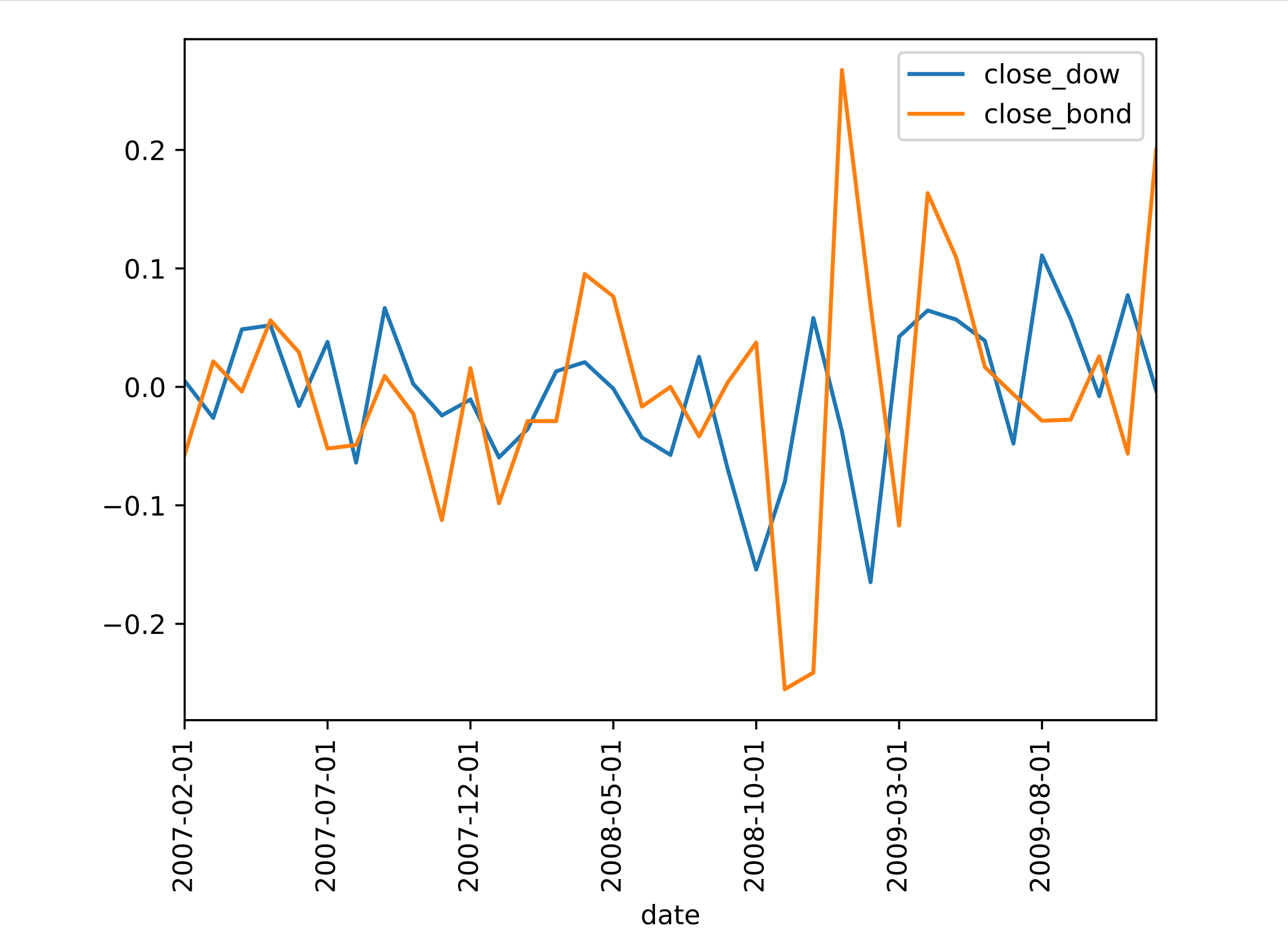
dow_bond = pd.merge_ordered(dji, bond_perc_close, on='date', how='inner',suffixes=['_dow','_bond'])
In [5]: dow_bond.head()
Out[5]:
date close_dow metric close_bond
0 2007-02-01 0.005094 close -0.057190
1 2007-03-01 -0.026139 close 0.021538
2 2007-04-01 0.048525 close -0.003873
3 2007-05-01 0.052007 close 0.056156
4 2007-06-01 -0.016070 close 0.029243
# Plot only the close_dow and close_bond columns
dow_bond.plot(y=['close_dow','close_bond'], x='date', rot=90)
plt.show()