sixth - HJ-Rich/2022-MyRSS GitHub Wiki
- 수치를 설정하고 정한 이유를 발표한다
- hikariCP configuration 보고 필요한 값 설정한다
- 풀 사이즈에 대해 : 기본값 10 그대로 유지
- 공식 문서 와 문서 내 영상을 참고
- 사용중인 인스턴스 코어가 1개이기 때문에 기본설정인 1에서 풀 사이즈를 수정할 필요를 느끼지 못했음.
- 실제 부하 테스트 결과, 최대 풀 사이즈를 100으로 늘리더라도, 성능 차이가 없었고, 커넥션을 최대 40개까지만 생성함
- 그외 설정에 대해 : 권장값 그대로 사용
- Statement의 캐싱에 대한 설정이 대부분.
- Hikari가 기본값에서 설정 변경을 권장하는 이유를 추측해보면 다음과 같다.
- 초기에 설정됐던 기본값 보다는 더 넉넉하게 설정을 줄 수 있을 만큼 하드웨어가 발전함
- MySQL 버전이 업데이트되며 서버 사이드 캐싱이 가능해짐
- Statement 캐싱 사이즈를 늘리고, 캐싱을 활성화해주는 옵션들. 권장 값 그대로 사용함.
dataSource.cachePrepStmts=true
dataSource.prepStmtCacheSize=250
dataSource.prepStmtCacheSqlLimit=2048
dataSource.useServerPrepStmts=true
dataSource.useLocalSessionState=true
dataSource.rewriteBatchedStatements=true
dataSource.cacheResultSetMetadata=true
dataSource.cacheServerConfiguration=true
dataSource.elideSetAutoCommits=true
dataSource.maintainTimeStats=false
- 서비스를 배포하는 중간에도 사용자는 서비스를 계속해서 사용할 수 있어야 한다
-
아이디어 정리
- 이중화를 하지 않았기에 블루 그린 배포로 간단히 구현하기로 선택
- A, B 포트 두개를 오가며 사용하기로 결정
- 현재 배포된 포트가 A인지 B인지 식별 후 현재 배포되어 있지 않은 포트를 신규 배포 대상 포트로 설정
- 신규 배포 대상 포트에 실행중인 프로세스가 있을 경우 kill 수행
- Jenkins를 통해 전달받은 jar 파일을 신규 배포 대상 포트에 백그라운드 프로세스로 실행
- 20초 대기 후 actuator health check 엔드포인트로 요청을 보낸 후 status:UP 상태 확인 및 실패 시 프로세스 중단
- Nginx 설정 수정 및 reload
- 기존 배포 대상 포트 프로세스 종료
-
실제 구현
- 쉘 스크립트에서 조건문, 변수 생성 및 값 할당, 변수 재사용 방법 학습
- A, B 포트 식별 및 변수 생성 및 할당, 배포 대상 포트에 프로세스 실행중일 경우 종료 처리
- 기존 배포에서 사용하던 nohup 문법으로 실행. sleep 문법을 통해 배포 대기
- curl -s 명령을 통해 헬스체크한 결과를 변수에 할당 및 status:UP과 응답 문자열이 일치하는지 확인
- 일치하지 않을 경우 배포 프로세스를 중단해야 했는데, exit 문장을 사용할 경우 클라이언트가 종료되는 이슈 발생
- early return 을 위해 함수로 선언하여 사용하도록 개선
- Nginx의 reload 기능을 이용해 restart 없이 proxy_pass 설정을 변경할 수 있음을 이용하기로 결정
- 동적 변경을 위해 proxy_pass 를 변수처리 후, 변수와 값을 담은 파일을 외부에서 include 하도록 nginx 설정 파일 수정
- WAS 서버에서 해당 설정을 담은 파일을 생성한 후, scp를 통해 Nginx 서버로 전송하여 include 될 파일 덮어쓰기 처리
- ssh 명령을 통해 reload 호출
- 여기까지 성공되었을 경우, 기존 배포 포트 종료
- 쉘 스크립트에서 조건문, 변수 생성 및 값 할당, 변수 재사용 방법 학습
-
무중단 검증 및 가용성 측정

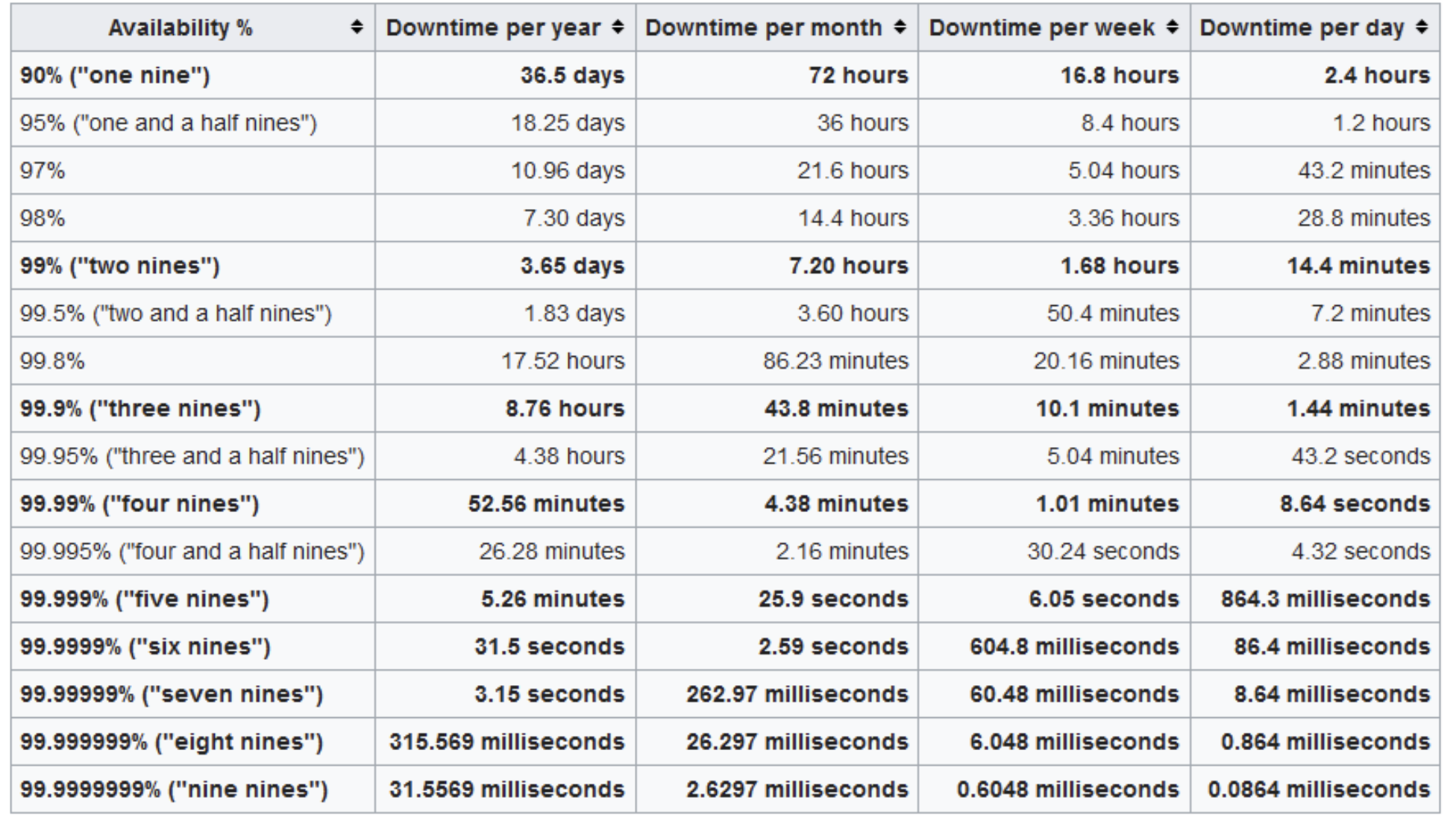
- 개발 서버 배포 프로세스를 실행시킨 후, Jmeter를 이용해 초당 10번의 요청을 전송 테스트
- 약 1400건의 요청 중, 2건이 정상 응답에 실패함
- 초당 10번에서 2건이니, 크게 잡아도 0.5초 정도 다운타임으로 가정
- 1주일에 한 번 배포한다고 가정했을 때, 1년에 다운타임이 30초 미만이므로 six nine, 99.9999% 가용성으로 판정
- 단 번에 완벽한 아키텍처로 갈 수는 없다
- 이를 목표로 분투하는 과정이 성장이다.
- 학습 출처 : 천만 사용자를 위한 AWS 클라우드 아키텍처 진화하기

- 초기 개발을 마치고 서비스를 시작하는 시점
- 목표
- 높은 성능 보다는 비용 효율적일 것
- WAS, DB 서버의 분리
- 기본적인 보안
- 기본적인 모니터링
- EC2 인스턴스 선택
- 과도하게 높은 성능을 선택하면 초기 비용 부담이 커짐
- 지나치게 낮은 성능을 선택하면 비용은 아끼지만 비즈니스 어려울 수 있음
- 적절한 성능의 인스턴스를 선택하되, 추후 변경 가능한 점 참고.
- Route 53
- AWS의 DNS 서비스
- Public IP를 AWS VPC 내 인스턴스와 연결해준다
- 서브넷 Public/Private 분리
- 사용자가 접근해야하는 서브넷과 아닌 서브넷을 분리함
- WAS는 퍼블릭 서브넷, DB는 프라이빗 서브넷
- AWS Shield 를 통해 DDos 방어
- CloudWatch 로 모니터링 및 AWS SNS를 이용한 알람 구성

- 아직 소규모 서비스이지만, 이제부터는 트래픽 증가를 대비해야 한다
- 목표
- AWS 로드밸런서 + WAS 이중화
- DB 이중화
- Managed DB 사용 (인스턴스에 직접 설치한 MySQL이 아닌, AWS Managed DB)
- 다중 가용 영역 활용
- AWS 하나의 리전에는 최소 2개 이상의 가용 영역이 존재한다.
- 가령 서울 리전에는 4개의 가용 영역이 존재한다.
- AWS 로드밸런서를 통해 이중화를 할 때, 아예 다른 가용 영역에 WAS를 추가하는 것이다
- ELB를 이용한 수평적 확장
- 안정성을 위해 WAS를 이중화하려면, 이를 앞에서 분배해주는 역할을 누군가 해줘야함
- AWS의 ELB가 이를 해줌. Elastic Load Balancer
- 서울 리전 내 A 가용영역에 WAS하나, B 가용영역에 WAS하나를 구성하고, ELB가 서로 다른 가용영역에 있는 WAS 둘에 부하를 분산해줌
- Managed DB로 전환
- EC2에 설치된 데이터베이스가 아닌 AWS가 관리해주는 DB서비스 이용
- 관리 포인트
⤵️ - 확장성, 가용성, 내구성, 성능
⤴️ - 읽기/쓰기 분리
- RDS 유형 중 Amazon Aurora 소개
- MySQL, PostgreSQL과 호환
- 내부 튜닝을 통해 더 높은 성능을 보인다고 함
- 3개 가용영역, 6벌 복제, 최대 15개 복제본, 최대 64TB 자동확장

- 큰 범주에서 둘 다 AWS에서 제공하는 ELB 서비스의 일종이다.
- ALB는 Application Load Balancer
- L7 기반, HTTP2, HTTPS 지원
- 소스 IP가 유지되지 않음. 필요시 X-Forwarded-For 같은 헤더 이용해야함
- NLB는 Network Load Balancer
- L4 기반, TCP, UDP, TLS 지원
- ALB와 달리 고정IP 사용 가능

- 더 이상 소규모가 아님. 중규모 정도는 됨
- 목표
- 성능에 본격적으로 신경써야할 시기
- 인스턴스 증가로 인한 관리 비용이 증가할 시기. 자동화 시작해야.
- 인스턴스 증가로 인한 비용을 줄일 방법도 필요
- 보안도 강화해야함
- Auto Scaling Group을 이용해 성능, 가용성, 비용 효율을 모두 챙김
- CloudFront, S3를 이용해 정적, 동적 리소스에 대해 캐싱 적용
- AWS Systems Manager를 이용해 여러 인스턴스 관리 편의성 증대
- AWS WAF, Shield, GuardDuty 를 이용해 보안 고도화

- 온 프레미스 환경이라면 피크 트래픽에 맞춰 리소스를 구성해야 한다.
- 클라우드 환경에선 오토 스케일링을 통해 최적의 리소스를 자동으로 활용 가능.
- AWS 오토 스케일링
- 오토 스케일링 그룹에 쓰레드풀, 커넥션풀 만들듯이 최소 최대값을 설정
- 서버 장애시 최소 수량만큼 자동 복구
- CloudWatch 지표 기반 스케일링
- 다른 RDS와 AuroraDB는 DB 인스턴스 자체를 오토 스케일링 가능
- 다른 RDS들은 스토리지 용량만 오토 스케일링 가능
- AuroraDB 인스턴스 CPU 메트릭을 기준으로 오토 스케일링 설정 가능

-
컨테이너 기반 서비스로 전환을 시작해야할 시기
- 러닝커브가 있어서 처음부터 도입하진 않음
- 컨테이너는 표준화, 경량화, 이식성, 쉬운 배포로 인해 MSA 필수
- MySQL : AuroraDB = Kubernetes : EKS(Elastic Kubernetes Service)
-
DB 읽기 성능 개선을 위해 캐싱 적용 필요
-
EKS를 이용해 EC2인스턴스를 대체
-
DB 읽기 성능 개선을 위해 ElasticCache 사용.
- Cache Miss 일 때에만 DB로 요청 전송


- 목표
- 용도에 맞는 DB 적용
- 샤딩을 통한 DB 분산
- 재해복구 (DR) 및 멀티리전 서비스
- NoSQL 사용하기 - Amazon DynamoDB
- 장바구니, 위시리스트 처럼 쓰기가 많은 경우 적절
- 대규모 요청에도 한 자릿수 ms 응답시간
- 읽기 작업은 ElasticCache → Cash miss 시 DB 또는 DynamoDB
- 쓰기 작업은 일부 선택한 작업은 DynamoDB에 더 빠르게
- CDK - Infra as a code
- 재해 복구를 위해 사용
- 파이썬, 노드JS, 타입스크립트, 자바 등 언어 사용 가능
- 인프라, 서비스 구성 자동화 가능
- 재활용 가능한 템플릿 생성 가능
- DR 상황에서 복구하도록 구성 가능
- 데이터 백업
- S3와 DB에 저장되는 데이터를 다른 리전에 복제시켜둘 수 있음
- 데이터는 미리 복제 또는 스냅샷을 사용
- DR 상황에서 구성해두었던 CDK를 이용해 빠르게 복구 구성 가능


- 목표
- 다중 리전별 서비스를 활성화
- Aurora 글로벌 DB
- 여러 리전에 읽기 전용을 구성 (ex. 서울, 런던, 시드니)
- 단, 쓰기는 한 곳에서만 가능
- DynamoDB 글로벌 테이블
- 여러 리전에서 읽기 쓰기 가능
- 변경이 자동으로 글로벌 리전에 전파됨
- ElasticCache 글로벌 데이터스토어
- 읽기 성능 개선을 위해 사용하던 ElasticCache도 글로벌화
- SPOF 제거를 위한 이중화, Failover, 다중 가용영역, 다중 리전
- 오토 스케일링
- 성능, 부하분산을 위해 캐시 사용
- 모니터링과 보안