fifth - HJ-Rich/2022-MyRSS GitHub Wiki
- 비로그인 상태에서 볼 수 있는 추천 기술블로그 피드 채널 제공 -> 완료
- Github 로그인, 로그아웃 -> 완료
- 로그인 상태에서 구독, 개인화하여 구성되는 피드 채널 제공 -> 완료
- 특정 피드를 공유하며 자신의 생각을 덧붙여 공유할 수 있는 SNS 채널 제공 -> 개발 예정
- SNS 채널 피드에 대한 좋아요, 댓글 기능 제공 -> 보류
- (Optional) 회원이 메일 설정을 활성화할 경우, 구독한 RSS 중 지난 한 주간 새롭게 등록된 피드들을 요약하여 메일 발송 서비스 -> 보류
- (Optional) 회원이 Slack Webhook URL제공 시, 구독한 RSS 중 새로운 피드 등록 시 Slack 알림 발송 서비스 -> 보류
threads max, max connections, accept count
- 설정에 대한 스프링 공식문서 설명
- 설정에 대한 Tomcat 공식문서 설명
- 결론
- server.tomcat.accept-count=50
- server.tomcat.max-connections=400
- server.tomcat.threads.min-spare=10
- server.tomcat.threads.max=10
- 도출 과정
- 개발 서버 피드 조회 API에 대해 300명이 10번 호출하는 상황으로 부하테스트
- acceptCount, maxConnections, threads.max 기준으로 테스트 수행
- 기본값 : 100, 8192, 200 -> 197 TPS, 1293ms
- threads.max 테스트
- 100, 50, 10, 5, 1로 줄여가며 테스트
- 10일 때 213 TPS, 1160ms 로 가장 좋은 결과
- threads.max 는 10으로 결정
- max-connections 테스트
- threads.max를 20분의 1 수준으로 줄였으니 같은 비율로 줄여 400부터 시작
- 400, 100, 10, 10(accept-count도 10) 로 줄여가며 테스트
- max-connections와 accept-count 모두 10으로 줄였을 땐 153 TPS, 1008ms 로 성능 저하 발생
- 그외엔 214 ~ 216 TPS, 991ms ~ 1143ms 로 유의미한 차이가 없음
- CPU 연산 보다는 I/O 블럭이 많은 웹 애플리케이션 특성 상, 스레드 보다 많은 커넥션 수를 설정하는 것이 적절하다고 판단
- 추가로 쓰레드 기본 설정값의 비율과 맞춰 400을 설정하기로 결정
- accept-count
- max-connections가 가득 찼을 때 OS에서 요청을 담아두는 큐 크기
- OS 설정에 따라 이 설정을 무시할 수도 있음
- accept-count가 가득 찬 뒤 요청이 추가로 오면 OS가 연결 거부하거나 타임아웃됨
- 처리할 수 있는 양에 따라 accept-count도 조절해야할 것으로 판단
- 기본값 100에서 50으로 줄여서 설정하기로 결정

- 테스트 설정

- 최종 설정 부하 테스트 결과 : 221 TPS, 1110ms
- threads.max=10, min-spare=10, max-connection=400, accept-count=50
- 기본 설정인 200, 10, 8192, 100일 때의 성능은 197 TPS, 1293ms
- 커스터마이징 후 TPS 10.86%, 평균응답시간 14.15% 개선
- 서비스에서 사용하는 모든 조회 쿼리와 테이블에 설정한 인덱스 공유
- 인덱스를 설정할 수 없는 쿼리가 있는 경우, 인덱스를 설정할 수 없는 이유 공유
- 공통 테스트 환경 관련
- EC2 인스턴스 신규 생성, MySQL 설치, 운영 환경 DDL을 이용해 테이블 생성
- JdbcTemplate batchUpdate로 100만건을 10만개씩 나눠서 10회에 걸쳐 총 1000만건 더미 데이터 삽입
- 1000만 건 데이터 삽입에 짧게는 3분에서 길게는 9분 소요
회원 관련 쿼리
- 테스트 전 예상
- 로그인 시, Github OAuth를 통해 얻은 Provider Id를 기준으로 DB에 일치하는 회원이 존재하는지 검증
- 존재하지 않을 경우 Save, 존재할 경우 조회된 결과를 기반으로 로그인 처리
- Provider Id를 조회 조건으로 사용하므로 인덱스 설정해야할 것으로 추측
- 테스트 결과
- provider_id 컬럼으로 회원을 조회했을 때, 4.2초
- id(PK) 컬럼으로 회원을 조회했을 때, 0.08초
- provider_id 컬럼에 인덱스 설정 후 0.08초로 50배 성능 향상
- 실행 계획 비교


- 위부터 차례대로 id로 조회, 인덱스 없는 provider_id 로 조회, 인덱스 적용 후 provider_id 로 조회.
- 인덱스를 사용하도록 실행계획이 변경되었음
- 삽입 성능 비교
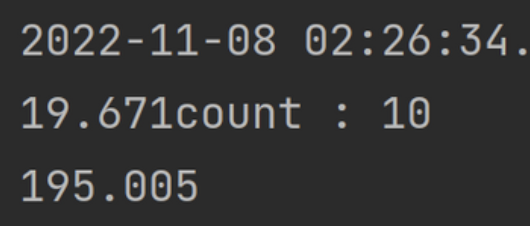
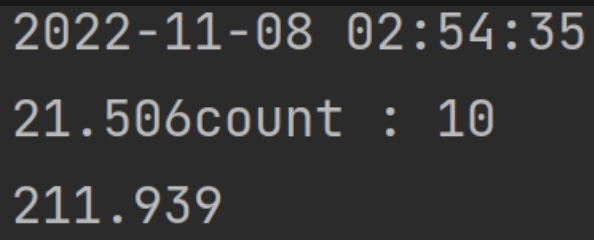
- 인덱스 적용 전과 후의 1000만 건 삽입 속도 비교
- 쓰기 성능 하락은 무시해도 될 수준으로 판단
피드 관련 쿼리
- 테스트 전 예상
- id로 조회, link 컬럼으로 조회 두 가지 쿼리가 사용됨
- id로 조회는 PK 사용이므로 별도 설정 불필요할 것으로 예상
- link 컬럼에 인덱스 설정을 통한 성능 향상이 예상됨
- 테스트 결과

- link 컬럼이 varchar(1000) 이어서 utf8mb4 형식에서 4000byte가 됨.
- index 최대 길이가 약 3000byte 여서 길이 제한 초과로 인해 인덱스 설정이 불가함.
- 대신 fulltext index 설정을 진행해봄
- 유사성을 기준으로 정렬해주므로 limit 1 을 추가해서 PK 조회와 거의 유사한 수준으로 성능 구현 되었음
- 다만, fulltext 인덱스로 인한 쓰기 성능의 극단적인 저하가 유발됨.
- 삽입 양이 늘어날수록 쓰기가 지연되어 빈 테이블에 1000만건을 삽입하는 로직 자체가 예외 발생되어버림
- URL Shortener와 JPA Converter를 이용해 DB 인서트 시 길이를 줄여볼까 고민했으나 오버엔지니어링이라고 판단
- URL이 750글자를 초과한다면 그것까진 대응하지 않아도 된다고 판단하여 link 컬럼을 varchar(750)으로 수정하고 인덱스 설정으로 마무리
- link 컬럼으로 조회 시에도 PK 조회와 동일한 수준의 성능 확인
- 실행 계획 비교
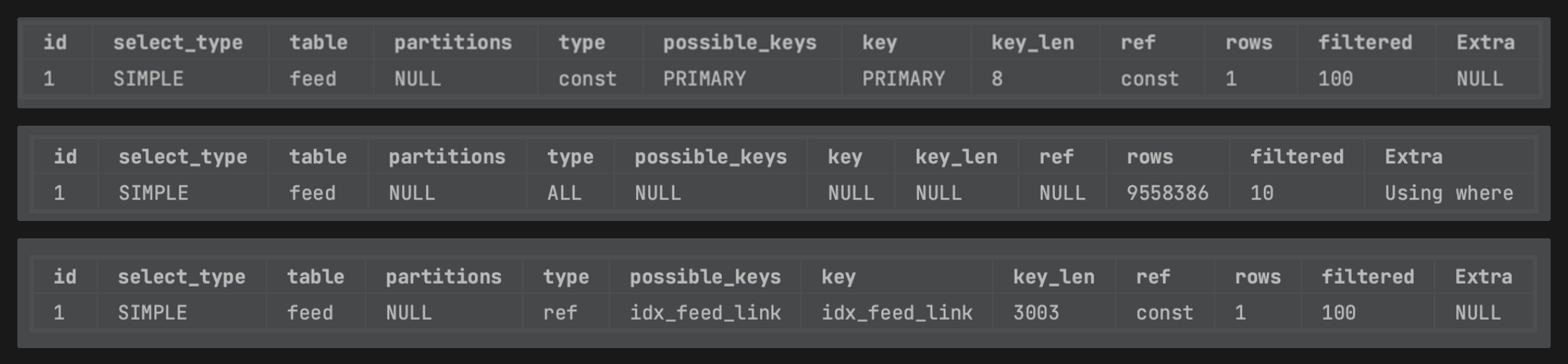
- 위에서부터 id로 조회, 인덱스 없이 link로 조회, 인덱스 설정 후 link로 조회
- 인덱스 설정 전, 1000만 건 데이터에서 link 로 조회 시 14초 소요
- 인덱스 설정 후 id 조회와 유사하게 0.14초 소요로 성능 개선
- 삽입 성능 비교
- 회원 사례와 동일하게 인덱스 설정으로 인한 쓰기 성능 하락은 미비했음
- 단, link 컬럼의 길이를 1000에서 750으로 줄여 일반 인덱스를 걸었을 때의 이야기.
- link 길이를 1000으로 유지하려 fulltext 인덱스를 걸었을 때엔 인덱스 생성에만 8분이 소요됨.
- fulltext 인덱스를 설정 한 후, 1000만 건 데이터를 삽입 시도 해봤으나, 데이터가 늘어날수록 삽입 속도가 크게 늘어나다가, 700만개째 삽입 시도 중 예외 발생하며 처리 실패.
- fulltext 설정 시, where 절에 match against 문법을 이용해 유사성 내림차순 조회라는 강력한 기능을 사용할 수 있지만, 삽입 성능을 크게 포기해야함을 알 수 있었음
- 사용자와 직접 인터렉션하지 않는 피드 업데이트 로직에서는 fulltext 인덱스를 통한 쓰기 성능이 다소 희생되더라도 추후 개발될 수 있는 피드 검색에서의 강력한 조회 기능을 위해 ElasticSearch 등의 검색 엔진을 도입하기 전까지는 피드의 제목과 description에 fulltext 인덱스를 거는 것도 방법이 될 수 있겠다.
북마크 관련 쿼리
- 테스트 전 예상
- bookmark 테이블은 id(pk), member_id(fk), feed_id(fk) 를 갖는 테이블
- where절에 member_id, feed_id 를 모두 사용하는 이미 북마크한 피드인지 조회하는 쿼리 존재
- where절에 member_id 만 사용해서 한 회원의 구독한 피드들을 조회하는 쿼리 존재
- 모조리 인덱스이니 성능이 아주 나쁘진 않을 듯 한데, fk 둘을 묶어서 조회하는 경우, 묶어서 새롭게 키를 생성하면 더 성능이 향상될지 궁금하다
- 테스트 결과
-
member_id(fk)로만 조회하는 경우 (회원 개인의 북마크한 피드 조회)
- member_id(fk)를 where절에서 사용하여 조회할 경우, 1000만건 기준 1초 소요
- 인덱스로 member_id 를 활용하지만, Using Where, Temporary, filesort가 사용됨
- member_id가 카디널리티가 더 높아서 member_id, feed_id로 다중컬럼 인덱스 생성
- 1000만건 기준 1초에서 0.2초로 개선
- 다중컬럼 인덱스가 사용되고, Using Where 이후 Using Index가 추가됨
-
member_id(fk) + feed_id(fk)로 조회하는 경우 (북마크 추가 시 이미 북마크 되어있는지 여부 확인)
- member_id = ? and feed_id = ? 로 where절에서 조회하는 경우 1000만건 기준 54ms 소요
- Using intersect로 두 인덱스로 조회한 결과를 머지하여 필터링
- 다중 컬럼 인덱스 처리 후
- 1000만 건 기준 54ms 에서 46ms로 개선
- Using intersect에서 Using Index로 개선
- 실행 계획 비교
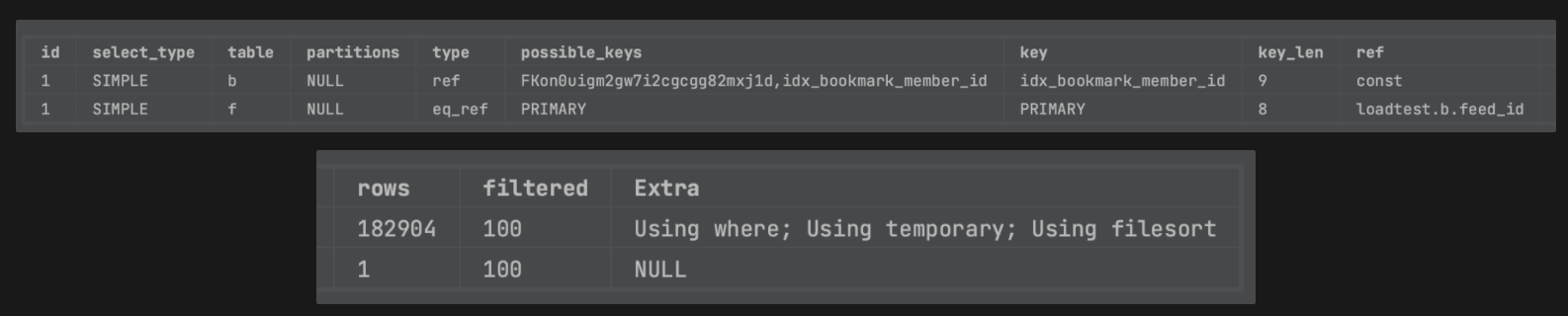

- member_id(fk)로만 조회 시 feed_id와 다중 컬럼 인덱스를 잡지 않았을 때(위)와 잡았을 때(아래)
- 설정 이후 다중 컬럼 인덱스가 인덱스 키로 사용되고, Using Where 이후 Using Index가 추가되었다
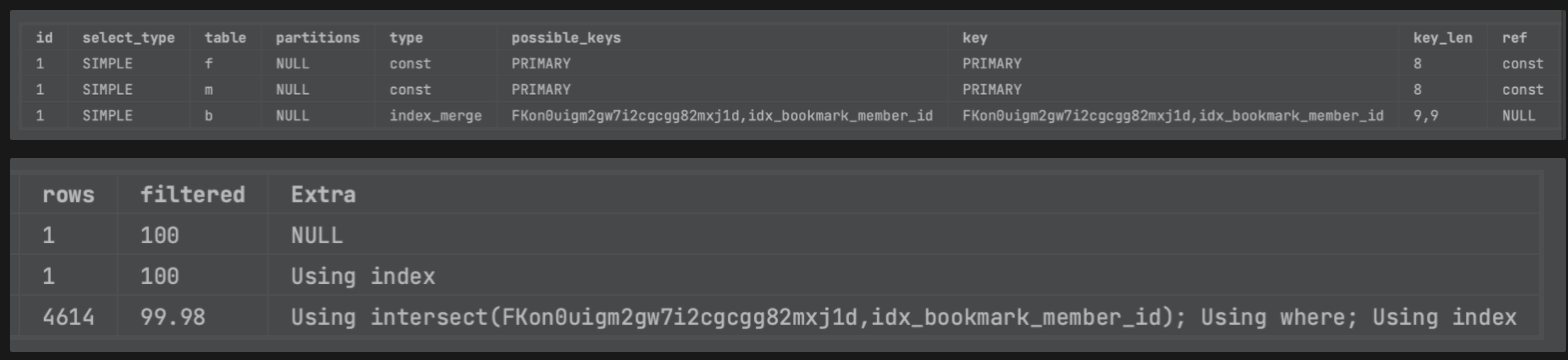
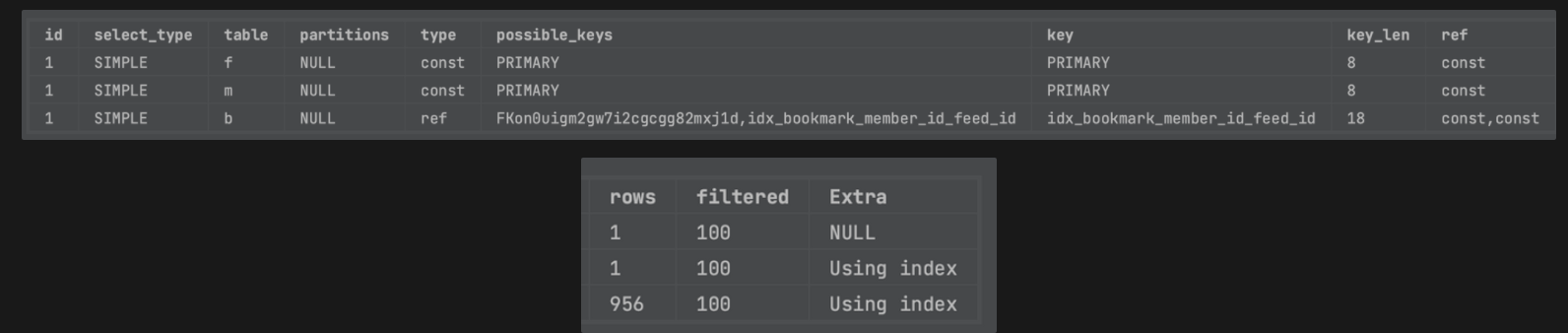
- member_id(fk) + feed_id(fk) 로 조회할 시 다중컬림 인덱스 잡지 않았을 때(위)와 잡았을 때(아래)
- 설정 이후 다중 컬럼 인덱스가 인덱스 키로 사용되고, Using Intersect가 Using Index로 개선되었다
- 삽입 성능 비교
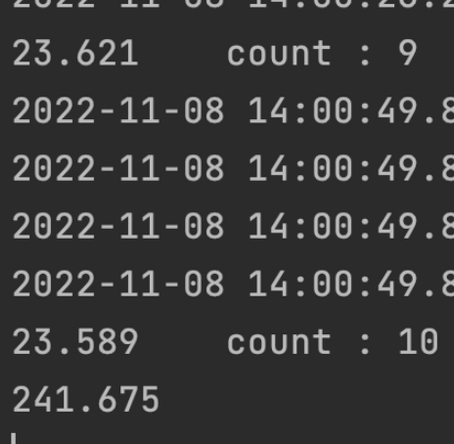
- 다중 컬럼 인덱스를 잡기 전과 후의 1000만 건 삽입 성능 비교
- 241초에서 544초로 다소 하락
- bookmark에 대한 삽입은 회원이 북마크를 추가할 때 발생
- 여러 건이 동시에 발생하지 않고 무조건 단건으로만 발생
- 북마크 추가 시 조회 후 쓰기인데, 조회 성능이 훨씬 개선되므로 다중컬럼 인덱스를 거는 것이 사용성 개선에 적절하다고 판단