UG_Special Topics_Custom Data Processors in Python - GoldenCheetah/GoldenCheetah GitHub Wiki
Options:DataFields:Processors & Automation (Version 3.7)
Custom Data Processors in Python
The ability to create custom data processors in Python, called Python fixes, is a new GoldenCheetah v3.5 feature accessible via Menu Bar -> Tools -> Options... -> Data Fields -> Processors & Automation
This menu item is automatically available when Python embedding is enabled in GoldenCheetah, see Working with Python for details.
It allows to run existing custom data processors (Fix Missing Initial Temperature and Add Weather Data, in this example). to manage existing custom data processors (edit and delete) and to create new custom data processors in Python.
Running Existing Python Fixes
Existing Python fixes can be executed directly from Menu Bar -> Edit -> name of the Python Fixes and they behave like builtin Data Processors: they are able to add, modify and delete standard or XData series for the currently selected activity in Activities View.
They can also be executed from the filter box using postprocess and autoprocess functions, like built in data processors.
These changes are subject to Undo/Redo in Editor until they are made permanent via Save or discarded via Revert to Saved Version or Exit without saving.
Python fixes can be enabled to run automatically on import or save, like built in data processors. Be careful to use getTag to access metadata since activityMetrics is not valid in this context.
Managing Python Fixes
Automation- If you set a
Python FixetoNonein theAutomationdrop-down list, you have to run it manually per activity throughMenu Bar->Tools-> name of the Python Fixe. - If you set a
Python FixetoOn ImportorOn Savein theAutomationdrop-down list, thePython Fixeis executed automatically for every activity that is imported or saved.
- If you set a
Automated execution only- If the checkbox is checked, the tool will not be displayed underMenu Bar->Tools.Hide core Processors- If the checkbox is checked, only the Python fixes will be shown.Edit- TheEditbutton allows for the modification of existing Python fixes.+- Created a newPython fix.-- Delete a existingPython fix.
Creating New Python Fixes
The following dialog window allows to create a new Python Fix (or edit an existing one) editing the name and script on the upper left panel, and test its behaviour on the selected activity, which is shown in the Editor on the right panel. Script output is shown in the lower left panel, which behaves like an standard Python interpreter REPL.
This is handy since it allows to preview the data, both standard and XData, run the data processor using Run button and immediately see the script effects on the selected activity, undo them if needed and run again, until you are satisfied enough to save and close to create a new Python Fix (or edit an existing one) with the provided name and script.
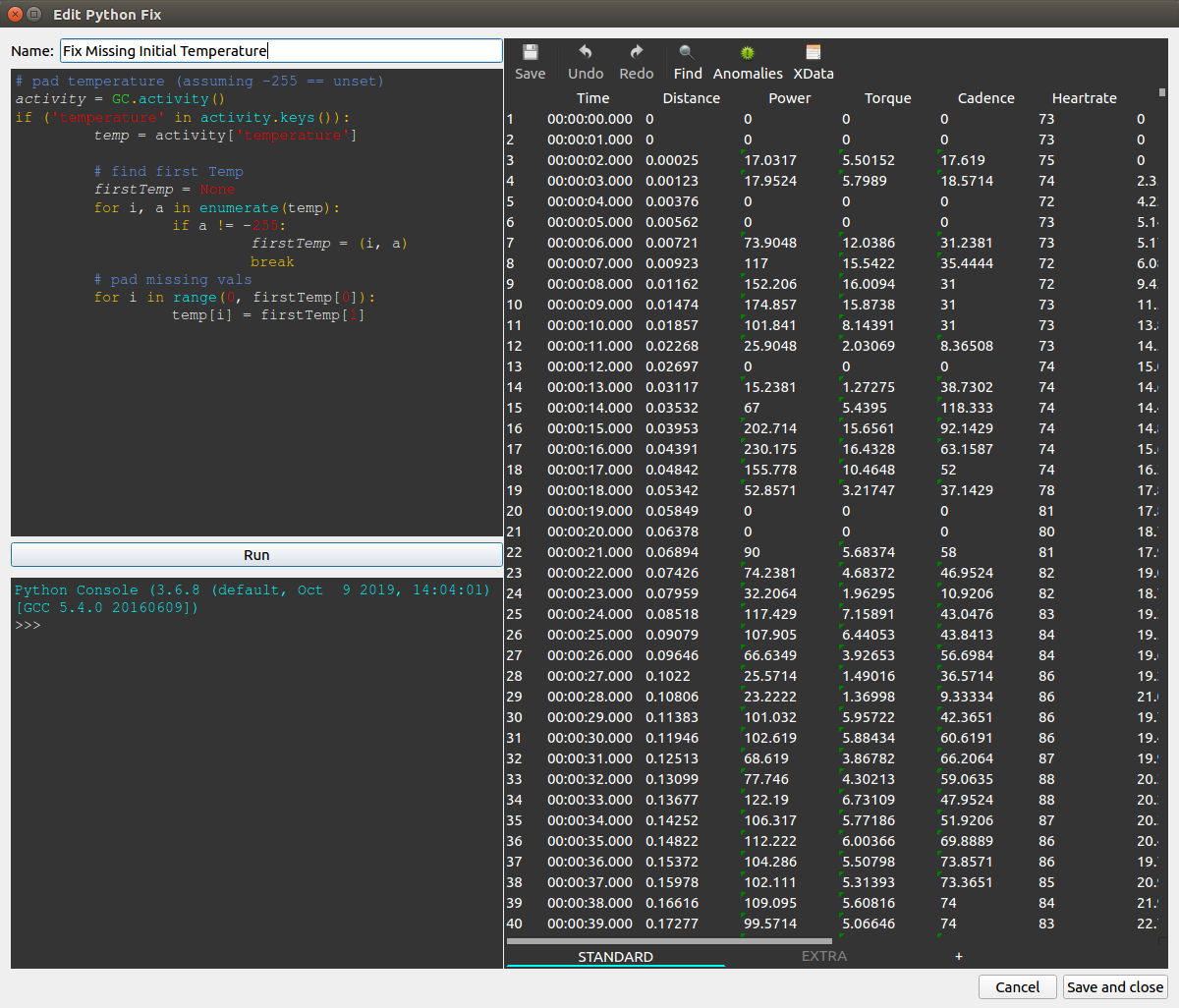
To access activity data the Python script uses the GC activity API, which in the context of a custom data processor is augmented with the ability to modify the objects returned by GC.series and GC.xdataSeries by assignment to object[index], as shown in the example, since they implement __setitem__.
All standard series are created by default, but they are marked as not present when all values are zero, so you can make a standard series present just setting some item to non zero value. For example GC.series(GC.SERIES_WATTS)[0]=999 will make the power series present.
Additionally the objects returned by xdataSeries support append and remove methods, and the Python-API was extended with the following methods available for custom data processors:
GC.deleteActivitySample(index, activity)to delete standard data rowsGC.deleteSeries(type, activity)to delete standard data columnsGC.postProcess(processor)to execute another data processorGC.createXDataSeries(xdata, series, unit)to create a new XData seriesGC.deleteXDataSeries(xdata, series)to remove an existing XData series (New in v3.7)GC.deleteXData(xdata)to remove an existing XData (New in v3.7)
All of them return True or False to indicate success or failure.
In v3.5 is not possible to manage metadata or metrics override in Python data processors, but this can be accomplished using filters.
Metadata and Metrics Override handling
New in v3.6, similar to set/unset/isset in formulas:
GC.setTag(name, value[, activity])to set metadata field or override metricnametovalueforactivity, defaults to current activity when not present, value must be of type str.GC.delTag(name[, activity])to delete metadata field or override metricnamefromactivity, defaults to current activity when not present.GC.hasTag(name[, activity])to check if metadata field or override metricnameis set foractivity, defaults to current activity when not present.GC.getTag(name[, activity])to get metadata field or override metricnamevalue string foractivity, defaults to current activity when not present.
All but getTag return a boolean success indicator, setTag and delTag also mark the activity as modified and notify metadata has changed on success.
Examples
The following examples were motivated by users requests:
Fix Temp Example
The first is a simple one: Garmin 800 devices are slow to start to report temperature so at the start there are several samples without the data which messes some charts, this script search for the first valid temperature data and uses it to fill the missing values from the start:
# pad temperature (assuming -255 == unset)
activity = GC.activity()
if 'temperature' in activity.keys():
temp = activity['temperature']
# find first Temp
firstTemp = None
for i, a in enumerate(temp):
if a != -255:
firstTemp = (i, a)
break
# pad missing vals
for i in range(0, firstTemp[0]):
temp[i] = firstTemp[1]
Fix Garmin-Stryd Power and Running Dynamics
This example is intended to override Power and Running Dynamics standard fields recorded by a Garmin device with native power (s.t. 255 or 955) and Running Dynamics sensor with the corresponding field from a paired Stryd sensor, if the target series is not present a new one is automatically created:
activity = GC.activity()
series = activity.keys()
if 'DEVELOPER_POWER-2' in series:
power = GC.series(GC.SERIES_WATTS)
for i,p in enumerate(activity['DEVELOPER_POWER-2']):
power[i] = p
if 'DEVELOPER_CADENCE-2' in series:
rcad = GC.series(GC.SERIES_RCAD)
for i,c in enumerate(activity['DEVELOPER_CADENCE-2']):
rcad[i] = c
if 'DEVELOPER_RUNVERT-2' in series:
rvert = GC.series(GC.SERIES_RVERT)
for i,v in enumerate(activity['DEVELOPER_RUNVERT-2']):
rvert[i] = v
if 'DEVELOPER_RUNCONTACT-2' in series:
rcontact = GC.series(GC.SERIES_RCONTACT)
for i,c in enumerate(activity['DEVELOPER_RUNCONTACT-2']):
rcontact[i] = c
Add Weather Data
This one is slightly more complex, it creates a WEATHER XData series with TEMPERATURE, HUMIDITY, WINDSPEED and WINDHEADING and it adds a Weather record at 1h intervals, it uses the Meteostat api so you need to get your own API key from https://api.meteostat.net/ and insert in the code.
import requests
from datetime import timedelta
from datetime import datetime
BASE_URL = "https://api.meteostat.net/"
VERSION = "v1/"
STATION = "stations/"
NEARBY = "nearby/"
HISTORY = "history/"
HOURLY = "hourly/"
QUERY = "?"
API_KEY = "__GET_IT_VIA_https://api.meteostat.net/"
timezone= "Europe/London"
def main():
# Weather XData series, compatible with FIT Importer
GC.createXDataSeries("WEATHER", "TEMPERATURE", "celsius")
GC.createXDataSeries("WEATHER", "HUMIDITY", "%")
GC.createXDataSeries("WEATHER", "WINDSPEED", "kmh")
GC.createXDataSeries("WEATHER", "WINDDIRECTION", "degrees")
GC.createXDataSeries("WEATHER", "DEWPOINT", "celsius")
act_date = GC.activityMetrics()["date"]
act_time = GC.activityMetrics()["time"]
act_duration = GC.activityMetrics()["Duration"]
# Standard activity data to get lat/long
seconds = list(GC.series(GC.SERIES_SECS))
lat = GC.series(GC.SERIES_LAT)
lon = GC.series(GC.SERIES_LON)
# Get weather information once on center or your ride
station, station_name = get_station_id_nearby((sum(lat)/len(lat)), (sum(lon)/len(lon)))
print("Station found Number: " + str(station) + " Name: " + str(station_name))
weather = get_weather_info(station, act_date.strftime("%Y-%m-%d"), act_date.strftime("%Y-%m-%d"))
# Determine if not an whole hour is found get nearest
act_datetime = datetime.combine(act_date, act_time)
i = 1
duration_in_ride=0
while duration_in_ride <= act_duration:
next_hour = datetime(act_date.year, act_date.month, act_date.day, act_time.hour + i, 0)
duration_in_ride = (next_hour - act_datetime).seconds
if duration_in_ride <= act_duration:
# find weather record
when = act_datetime + timedelta(seconds=duration_in_ride)
found = False
for weather_record in weather['data']:
local_time = weather_record['time_local']
local_time = datetime.strptime(local_time, "%Y-%m-%d %H:%M")
if local_time == when:
found = True
print("Weather_record: " + str(weather_record))
GC.xdataSeries("WEATHER", "secs").append(duration_in_ride)
index = len(GC.xdataSeries("WEATHER", "secs"))-1
GC.xdataSeries("WEATHER", "TEMPERATURE")[index] = weather_record['temperature']
GC.xdataSeries("WEATHER", "HUMIDITY")[index] = weather_record['humidity']
GC.xdataSeries("WEATHER", "WINDSPEED")[index] = weather_record['windspeed']
GC.xdataSeries("WEATHER", "WINDDIRECTION")[index] = weather_record['winddirection']
GC.xdataSeries("WEATHER", "DEWPOINT")[index] = weather_record['dewpoint']
break
if not found:
print("NO WEAHTER RECORD FOUND AT TIME: " + str(when))
else:
print("Next retrial is outside ride so skip")
i += 1
def get_station_id_nearby(lat, lon):
source = {"lat": lat,
"lon": lon,
"limit": 1,
"key": API_KEY,
}
resp = requests.get(BASE_URL + VERSION + STATION + NEARBY + QUERY, params=source)
if resp.status_code != 200:
raise Exception("GET " + BASE_URL + VERSION + STATION + NEARBY + QUERY + " ret: " + str(resp.status_code))
return resp.json()['data'][0]['id'], resp.json()['data'][0]['name']
def get_weather_info(station, start, end):
station_history = {"station": station,
"start": start,
"end": end,
"time_zone": timezone,
"time_format": "Y-m-d H:i",
"key": API_KEY,
}
resp = requests.get(BASE_URL + VERSION + HISTORY + HOURLY + QUERY, params=station_history)
if resp.status_code != 200:
raise Exception("GET " + BASE_URL + VERSION + STATION + NEARBY + QUERY + " ret: " + str(resp.status_code))
return resp.json()
if __name__ == "__main__":
main()
Another example for filtering spikes in power data for MTB rides. Downhill segments often produce power spikes when riding downhill on trails/rough terrain due to impacts. The filter is removing all spikes on downhill slopes that are above a certain threshold.
import numpy as np
from scipy.stats import linregress
def movingWindowSlope(altitude,window=5):
trendMat=[0]*len(altitude)
for i in range(window,len(altitude)):
slope, intercept, r_value, p_value,std_err=linregress(range(0,window),altitude[i-window:i])
trendMat[i]=slope
return trendMat
## import data
ride = GC.activity()
power=ride["power"]
altitude=ride["altitude"]
slope=np.array(movingWindowSlope(list(altitude)))
powerFiltered=np.array(power)
maxValue=np.quantile(powerFiltered,.97)
powerFiltered[(powerFiltered>maxValue) & (slope<=0)]=0
for i in range(0,len(power)):
power[i]=powerFiltered[i]
BACK: Special Topics: Overview
BACK: Table of contents