3. Job Processing Flow - GeniusVentures/SuperGenius GitHub Wiki
All queueing of Jobs/MacroJobs/MicroJobs are using a locking queue with timeout to be able to handle node drop outs/disconnects when joining a room for a MicroJob or creating a MacroJob room. When querying open jobs (Jobs,MacroJobs,MicroJobs) it is the union of jobs that have exceeded the timestamp lock & jobs that are have not been previously timestamp locked.
Job Placement
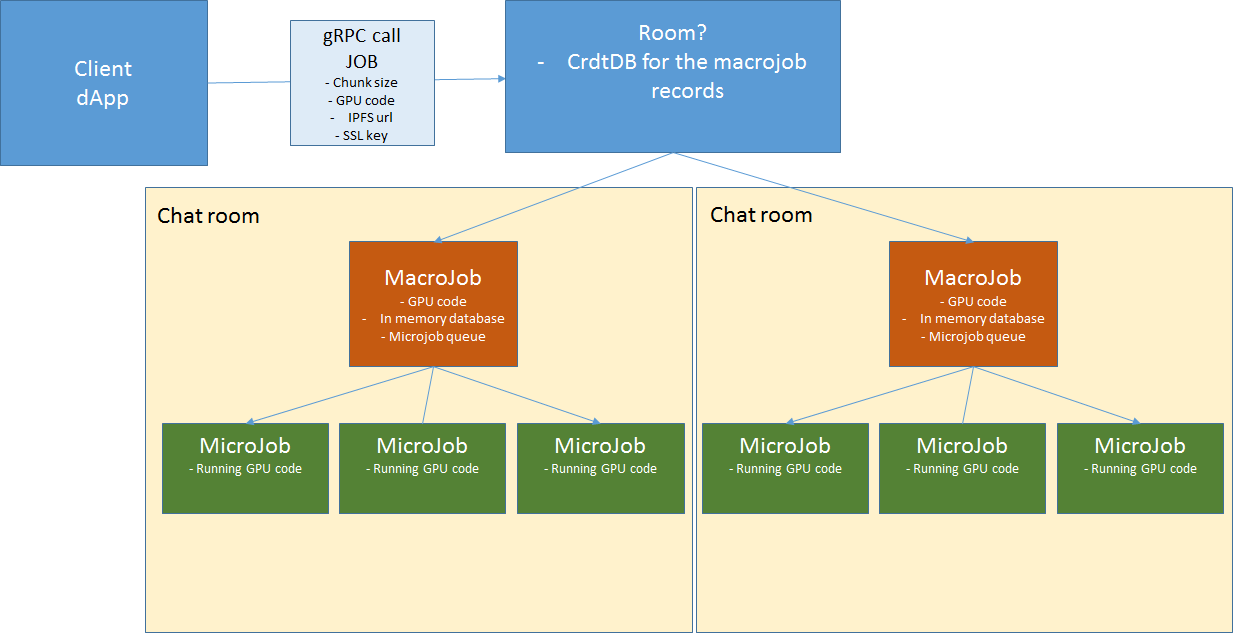
DApp creates a Job:
- DApp specifies Job code (shader/Tensorflow/OpenCL) URI to source from (IPFS/SFTP/WS/HTTPS).
- DApp specifies Job data URI to source from (IPFS/SFTP/WS/HTTPS).
- DApp fills a JobInfo structure, including Job slicing parameters and a seed for random number generator and places it into CRDT.
- Dapp Slices Job with slicing parameters and creates MacroJobs & MicroJobs with random ID's from random seed saving into the CRDT DB
- DApp doesn't need to wait until job completion as the Polygon (Matic) BlockChain Smart Contract will create a transaction block on Verify Job Function/Release Escrow call. The Dapp can poll into Polygon (Matic) blockchain to check job completion.
Processing node initialization
- Once a Job processor is started it is linked/synced to CRDT DB.
- Create or Join Jobs PubSub Channel (first bootstrap node should do this)
Job Processing
- Job processor asks for open jobs via the PubSub Channel, if none exist, loop here (step 3)
- Join Job{ID}/MacroJob PubSub channel
MacroJob Processing
-
Job processor asks for open MacroJobs from the PubSub Channel (because CRDT DB might not be synced) Job processor asks for open MacroJobs from the PubSub Channel. CRDT is not used as MacroJobs storage.
-
if MacroJob open, Join Job{id}/MacroJob{id} Channel, goto 'MicroJob Processing'.
*** This can also in the future check for locality of processing nodes
-
If no MacroJobs open goto 'Job Processing'.
-
Mark CRDT DB with timeout timestamp/lock and create channel Job{id}/MacroJob{id} and notify PubSub Create in-memory MicroJob queue, set itself as the current queue owner. To create a validation MicroJob a random number generator should be used with seed equal to Job input seed + MacroJob index {id}
-
Create PubSub channel Job{id}/MacroJob{id} and notify over Job PubSub channel about the created MacroJob channel.
-
Job Processor joins MacroJob PubSub Channel
-
Go to MicroJob Processing
MicroJob Processing
- Job Processor asks for open MicroJobs via PubSub, if none goto 'MacroJob Processing' Job Processor requests for in-memory MicroJob queue via PubSub. Once a Microjob queue owner receives the request it marks the requestor as the current queue owner and sends the queue to PubSub. Note: All Processors receive the updated in-memory queue but only the current queue owner can operate with it.
- Job processor marks MicroJob CRDT DB with timeout timestamp/lock and notifies PubSub Channel Job processor receives the MicrJobs queue. If it is marked as the current queue it checks if there is an open Microjob and marks it with with timeout timestamp/lock and notifies PubSub Channel
- Job processor applies the code algorithm for data blocks that are specified in the MicroJob.
- Job processor writes MicroJob processing results into CRDT when the MicroJob processing is finished. a. Data should be written to IPFS b. CRDT record should be written with Job{ID}/MacroJob{ID}/MicroJob{ID} = data: { wallet address, hashes of processed blocks } + hash (Job{ID}/MacroJob{ID}/MicroJob{ID} & data) c. Job processor publishes to Job channel, 1 MicroJob is complete
- Job Processor checks if final MicroJob for a Job, if so jump to Job Finalization
- Job processor checks if there are non-processed Micro Jobs and repeats p.1-6 until all Micro Jobs are processed.
- Go to 'Macro Job Processing'
Job Finalization.
-
When a Job processor finishes a MicroJob processing it checks if Job's MicroJob count finished is equal to MicroJob count.
-
if not goto Job Processing
-
Last MicroJob scans MacroJobs and finds verifier hashes by checking all MicroJob hashes to see which matches the other 10 nodes hashes
-
It sends this hash to the Smart Contract along with wallet addresses to release the Escrow
-
Smart Contract ZkSnark algorithm can verify because {ID}'s are generated from RandomSeed, encrypted with zkSnark
*** If smart contract fails to verify. Culprit can be figured out, by getting index of MacroJob verifier node and checking hashes against other non-verifier nodes to find the mismatch.