2) Repaso Semana 4 a Semana 16 (Durante la cuarentena) - GabrielVL/Portafolio-I-2020 GitHub Wiki
Inicia la cuarentena el 15 de marzo
Repaso Semana 4, Día 7 (29 de abril)
Reanudamos el curso con un repaso, empezando desde 2 semanas antes de que empezara la cuarentera (en semana 4). Hablamos un poco de como va a estar modelada la clase virtual
Vimos paradigmas de programación con una sopa de letras y los conceptos de POO con un crucigrama.
Repaso Semana 5, Día 8 (6 de mayo)
El viernes fue libre por el día del trabajador. Acordamos en hacer un kahoot al inicio de cada clase para repasar la materia de la clase pasada.
- UML, diagrama de clases, sus relaciones
- Diseño orientado a objetos
Repaso Semana 5, Día 9 (8 de mayo)
Empezamos la clase con un kahoot repasando la materia de la clase pasada.
- Patrones de diseño y sus tipos, patrones de arquitectura (MVC)
También creamos en grupos de 5 el diagrama de clases que tendría un supermercado (nosotros lo representamos como uno en línea)
Semana 6, Día 10 (13 de mayo)
Vimos la diferencia entre un modelo de dominio y un diagrama de clases, armando primero el modelo y después convirtiéndolo en un diagrama. Además, empesamos a ver Abstract Data types (ADT) que son lists , queues, sets & graphs. También tienen operaciones asociadas, como add, remove o contains. No es un concepto de POO.
- Arrays: Tienen un límite de tamaño y no tienen una palabra específica para declararlo
int[] a; int a[]; int[] a = new int[10]; int[] b = {5, 4, 2, 1};Los datos del array están guardados secuencialmente en memoria. Cambiar el tamaño del array es costoso, ya que hay que crear otro array con el tamaño nuevo. - Matrices: Arrays en dos dimensiones
- Listas enlazadas: Cada nodo en la lista es un objeto separado y no está guardado secuencialmente en memoria. Cada nodo contiene una referencia a otro nodo, además del dato que guarda. Cada lista guarda el primer nodo que contiene. Existen varios tipos.
Insertar:

Eliminar:
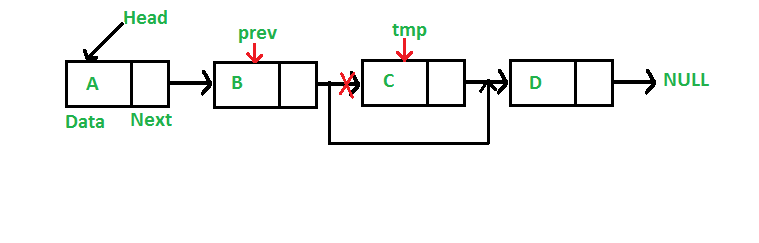
Semana 6, Día 11 (15 de mayo)
Seguimos repasando métodos de la lista enlazada simple, viendo cómo funciona el código.
Tipos de listas enlazadas:
- Linked List: La versión básica de la lista contiene una referencia a su primer nodo, y cada nodo contiene una referencia al nodo próximo.
- Double Ended List: Además de tener la referencia al primer nodo, contiene una referencia al último para no recorrer toda la lista para añadir un nodo al final.
- Doubly List: Cada nodo, además de tener una referencia al nodo próximo, tiene una referencia al nodo anterior. Una desventaja es que hay que trabajar más punteros a la hora de crear métodos, además de que los nodos ocupan un poco más de espacio.
Insertar:
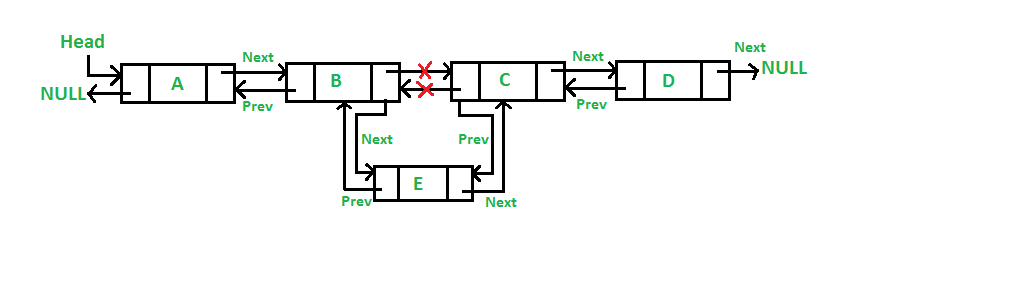
Eliminar:
- Circular List: El último nodo tiene una referencia al primero, por lo tanto ninguno referencia a null, lo que significa que no tiene final.
Semana 7, Día 12 (20 de mayo)
Pilas (Stack): apilan los elementos que se van añadiendo, como una pila de platos. Last in, first out (LIFO)
Métodos:
- Pop: quita el elemento encima de la pila.
- Push: añade a un elemento encima de la pila.
- Peek: obtiene el elemento encima de la pila sin quitarlo.
Colas (Queues): First in, first out (FIFO). Similar a una fila en una soda. Se utiliza el método "wrapping" para añadir elementos cuando aún hay espacio pero el final está ocupado.
Métodos:
- Enqueue: qgrega un elemento a la parte trasera de la cola
- Dequeue: quita un elemento que está al frente de la cola
- Peek: obtiene el primer elemento de la cola
Priority queue: Una cola que tiene cada elemento en una llave, enlazado a un valor de prioridad. Similar a una fila del CCSS.
Semana 7, Día 13 (22 de mayo)
Hicimos el quiz 3 de patrones de diseño, diseño orientado a objetos y patrones de arquitectura (MVC)
Luego practicamos listas con un método swap(int indexA, int IndexB) que cambia a los nodos según los índices que se colocan.
Semana 8, Día 14 (29 de mayo)
Hicimos el quiz 4 de listas enlazadas
Algortimos
- Son efectivos, cumplen su propósito
- Tiene un output
- Los resultados de cada paso son definidos únicamente poer el input y el resultado que da.
Algortimos de ordenamiento: Al comparar estos algoritmos se define su eficiencia por medio de la rapidez en la que comparan dos valores.
Semana 9, Día 15 (3 de junio)
Semana 9, Día 16 (5 de junio)
Hicimos el quiz 5 de algoritmos de ordenamiento
Semana 10, Día 17 (10 de junio)
Algoritmos de búsqueda
- Binary search
- Interpolation search
- Hash search
Semana 10, Día 18 (12 de junio)
Estructuras de datos de almacenamiento
Árboles:
- Consisten de nodos (nodes) conectados por aristas (edges).
- Son especializaciones del grafo.
- Son pequeños en la cima y grandes en la base.
Tipos de árboles:
- Binarios
- Heap
- AVL
Se aplica a sistemas de archivos, organizan datos que necesitan ser buscados y, en bases de datos, los datos se almacenan en árboles B o sus varaiciones.
Cuando uno recorre (walk) de nodo a nodo un árbol sigue una ruta (path). Solo existe una raíz (root) en la cima, y todos los nodos (excepto la raíz) tienen solo una arista hacia arriba que va a otro nodo, al que se le llama nodo padre (parent) (los nodos abajo se les llaman hijos (children) y los que no tienen hijos se l es llama nodos hoja) y los que tienen al mismo padre se les llama hermanos (siblings)). El largo (length) de la ruta se mide contando el número de aristas de nodo a nodo. La profundidad (depth) de un nodo es el largo de la ruta tiene hasta la raíz. La profundidad de la raíz es zero. El alto (height) es el largo desde el nodo hasta su hijo que esté más abajo. Un nodo es visitado (visited) cuando el programa hace una operación sobre los datos del nodo, o al menos lo retorna.
Árboles binarios
Es un árbol en el que cada nodo tiene máximo 2 nodos hijos: el hijo izquierdo y el derecho. si los hijos izquierdos son menores que el padre y los derechos son mayores, se le llama árbol binario de búsqueda (binary search tree).
Semana 11, Día 18 (17 de junio)
Operaciones de árboles binarios:
- contains(): retorna un true si el elemento que se recibe se encuentra en el árbol y false si no lo tiene.
- findMin/findMax(): busca el menor o el mayor nodo del árbol
- insert(): Se añade un elemento nuevo al árbol. Si el elemento ya existe, se actualiza el nodo o se deja intacto.
- delete(): elimina un nodo. Es la operación más compleja, ya que hay 3 casos diferentes: si el nodo es una hoja, si tiene un hijo y si tiene dos hijos.
Semana 11, Día 19 (19 de junio)
Árboles AVL
Árbol binario que siempre está balanceado. Si se le añade un elemento que altera su balance, busca el balance por su cuenta. Esto es gracias a un factor de balance que tiene cada nodo, definido por la altura del subárbol derecho menos la altura del subárbol izquierdo. Si el factor de balance es -1, 0 o 1 en todos los nodos, el árbol está balanceado.
Semana 12, Día 20 (24 de junio)
El árbol AVL contiene métodos de rotaciones para balancear el árbol cuando se inserta o se elimina un nodo. Left-left y right-right hacen una sola rotación, mientras que right-left y left-right hacen doble rotación.
Árboles splay
Árbol binario de busca que usa el principio de localidad, lo que hace que el último nodo que fue accedido pase a ser la raíz. Contiene las rotaciones zig, zig-zig y zig-zag que son iguales a las rotaciones simples del árbol AVL.
Árboles heap
Árbol binario que se implementa con colas de prioridad (priority queues). Se puede hacer con arrays.
- Está completo: todos los nodos están ocupados de izquierda a derecha.
- Se puede implementar como array
- Satisface la condición heap: Los nodos padre tienen que ser mayores que sus hijos.
- Siempre se elimina el nodo que es mayor que todos, luego se mueve el último a la raíz y se mueve hasta que llegue donde pertenece.
- Siempre se inserta al final y se va moviendo a donde pertenece.
Semana 12, Día 21 (26 de junio)
Árboles n-arios (n-ary)
Árbol con una cantidad arbitraria de hijos. Son más difíciles de implementar que lso binarios. Le brinda acceso al hijo que está más a la izquierda y a partir de él se accede a los demás nodos, como una lista.
Árboles B
Mientras que los demás árboles se almacenan en la memoria RAM, este árbol utiliza el almacenamiento de memoria secundario, lo que significa que dura más en ser accesado. Se utiliza cuando haya que guardar demasiados datos. Un árbol B de órden m tiene las siguientes características:
- Todos sus nodos hoja están en el mismo nivel.
- Todas las páginas internas excepto la raíz van a tener un máximo de m branches y un mínimo de m/2 branches
Semana 13, Día 22 (1° de julio)
Árboles B+
- Variacón del árbol B
- Los datos solo están almacendaos en las hojas
- Los nodos internos tienen llaves de los datos en las hojas
Árboles B*
- Variacón del árbol B
- Todos los nodos excepto la raíz tienen m hijos
- Su inserción es más compleja, ya que hace rotaciones en vez de dividir los nodos
Semana 13, Día 22 (1° de julio)
Árbol de expresión
- Cada hoja tiene un operando
- La raíz y los nodos internos son operadores
- Existen varias maneras de interpretarlo: infix, prefix, postfix
Semana 14, Día 23 (15 de julio)
Grafos
Estructura de datos en donde existen varias rutras entre sus nodos. Un grafo está compuesto por vértices, nodos o puntos, y aristas, arcos o líneas. Un grafo se denota como G = {V, A}.
- Un grafo puede ser dirigido o no dirigido. El dirigido tiene rutas con dirección, mientras que en el no dirigido las rutas van a ambas direcciones.
- Los grafos pueden tener peso, en los que se le asigna un valor a cada ruta.
- Una ruta simple entre dos nodos es cuando ningún nodo se repite en esta ruta.
- Un grafo es conectado si extiste una ruta para llegar a cada uno de sus nodos desde cualquier nodo. Además, es fuertemente conectado si además de ser conectado, es dirigido.
- La matriz de adyacencia muestra la conexión que existe entre los nodos de un grafo, mostrando un 1 si existe conexión y 0 si no existe conexión. Los grafos con peso contienen el valor del peso en vez de un 1 cuando se muestra una conexión.
Existen varios métodos para recorrer un grafo:
- Breadth-First (FIFO, utiliza una cola)
- Depth-First (LIFO, utiliza una pila)
Semana 14, Día 24 (17 de julio)
Algortimos para encontrar la ruta más corta en un grafo
Dijkstra
- Se utiliza en con peso, preferiblemente en grafos dirigidos.
- Se suma el peso de la ruta más corta.
- Sirva para encontrar la ruta más corta de un nodo en específico a cualquiera de los demás nodos.
Semana 15, Día 25 (22 de julio)
Floyd
- Utiliza programación dinámica para encontrar la ruta más corta de cualquier nodo a cualquier otro nodo
- Si no existe unión entre nodos, se marcar el valor de la ruta entre ellos como infinito
Semana 15, Día 26 (24 de julio)
Warshall
- Calcula la matriz de las rutas de un grafo.
- Solo dice si hay comunicación o no con un par de nodos.
Semana 16, Día 27 (29 de julio)
Árbol de expansión mínima
Es una sección del grafo que contiene las rutas con la suma de los pesos mínimos
- No tiene ciclos
- Solo existe una ruta entre dos vértices del árbol
- Si una ruta se añade en cualquier lugar, se forma un ciclo
- Se obtiene con el algoritmo de Prim o el de Kruskal