Counting Sort - Eishaaya/GMRDataStructuresTest GitHub Wiki
Counting Sort is an O(n) algorithm that relies heavily on arrays and indexing. As its name suggests, it makes use of an array of buckets to count how many of each value exists in the inputted dataset. Since the only datatype the algorithm ever runs on is an integer, we can use fast O(1) array operations to index into our buckets, and increment them. Arrays are ordered by index, so the data just placed into the buckets can just be incrementally moved back into our input array.
Simple Counting Sort
Parameter: uint[] or List<uint>
Returns: void
As mentioned above, counting sort relies on arrays, more specifically, it relies on an array of buckets (similar to a dictionary's buckets) to count the occurrences of each individual value in our dataset. The amount of buckets directly corresponds to the range of data in the dataset, as in: if our data goes from 0-10, we would have 11 buckets, 0-150? 151 buckets, and so on... As you might guess, we might end up with an extremely large quantity of buckets depending on what range our data falls into, even if we only had 2 items, if the first item is zero, and the last is a billion, we would end up using at least four gigabytes of RAM to sort two items!
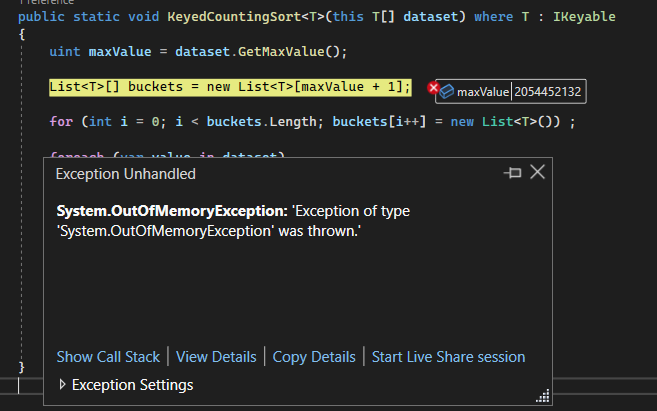
Pictured above, A minor issue with counting sort
In the example below, our dataset ranges from 0 - 5, meaning we need six buckets

We then loop through our dataset, and increment the count of the bucket corresponding to each value we see.

Finally, we loop through our now filled buckets, and copy each bucket's value n times, where n is the count stored within the bucket back into our input array in the same order as the buckets (which are already sorted from 0-max because the buckets' value is just their position in the array)

-
Minimizing Buckets: If our data ranges from 10-20, we only need 11 buckets, but if we only look at our max, we would end up with 21. If we use our minimum as an offset, and make the smallest value map to bucket zero, we no longer need buckets corresponding to integer values below zero.
-
Negatives: Negatives are actually quite easy to account for, funnily enough, just offset using the method mentioned above. (Also, if you want negatives, make sure you take in a signed
intinstead of auint)
EG: Keyed Counting Sort
Parameter: T[] or List<T> in which T has some sort of accessible integer key
Returns: void
So, as you know, comparison-based sorts can sort anything, anything comparable that is, which includes a tad more than just integers. So how could we get our integer based sorts to do the same? Well, we can't, but we can get close. What if we were to link values with integer keys representing their value, perhaps by encapsulating them into something like a KeyValuePair, or creating and using an interface of some sort? Now we should be able to sort any values as if they were integers!

However, the previous method of counting each integer value doesn't really cut it anymore, since that only preserves our keys, but not our values. To adapt, each of our buckets should store our values directly, rather than just a count, probably in a list of some sort. Pigeonhole sort is stable, so the order of any equivalent values should be preserved.
n = number of inputs, k = range of inputs
Even though this algorithm can technically be classified as O(n), after implementing it, you can see that running time isn't just based off of the amount of items we have! Big O doesn't account for the size of the buckets array, since that's entirely disconnected from the input quantity, and so we end up technically qualifying as a linear time algorithm, with O(1) space complexity when only considering n. To be more accurate on our complexity, time is O(n + k), and space is O(k) or O(n + k) if you are doing the keyed variant
- Take a look at our implementation if you are stuck.