Kafka - DmitryGontarenko/usefultricks GitHub Wiki
Kafka - распределенный брокер сообщений.
Брокер - система, обеспечивающая возможность взаимодействия приложений между собой с помощью отправки сообщений от источника данных (producer) к принимающей стороне (consumer).
Producer - поставщик данных.
Consumer - потребитель данных.
Сообщение (событие) в Kafka - это данные, которые поступают из какого либо сервиса читаются другими сервисами. Сообщение состоит из:
- Key - опциональный ключ, нужен для распределения сообщений по кластеру;
- Value - массив байт, бизнес-данные;
- Timestamp - текущее системное время, устанавливается отправителем или кластером во время обработки;
- Headers - пользовательские атрибуты key-value, которые прикрепляют к сообщению.
- В Kafka существует кластер, который хранит в себе один или несколько брокеров.
- Каждый брокер может хранить в себе один или больше топиков, через которые осуществляется передача сообщений.
- Топик может быть разделен на разделы (partitional), каждый раздел может быть расположен на отдельной машине, что позволяет получить параллельный доступ к топику.

- Топик может быть разделен на разделы (partitional), каждый раздел может быть расположен на отдельной машине, что позволяет получить параллельный доступ к топику.
- Каждый брокер может хранить в себе один или больше топиков, через которые осуществляется передача сообщений.
ZooKeeper - инструмент-координатор, действует как общая служба конфигурации в системе. Работает как база для хранения метаданных о состоянии узлов кластера и расположении сообщений. ZooKeeper обеспечивает гибкую и надежную синхронизацию в распределенной системе, позволяя нескольким клиентам выполнять одновременно чтение и запись.
Без брокера producer должен знать основного consumer и резервного, если основной недоступен. К тому же, поставщикам данных придется самостоятельно регистрировать новых consumers. С помощью брокера producer просто отправляют данные в единый узел.
Взаимодействие через API - брокеры решают проблему интеграции разных технических стеков и протоколов. Интеграция происходит просто: producer и consumer необходимо знать только API брокера. Они не контактируют между собой, с помощью чего достигается высокая интегрируемость с другими системами.
Для чтения используется poll-механика, т.е. поставщик не сообщает потребителю о новых сообщениях, потребитель сам должны подписаться на топик и проверять наличие сообщений.
Топик - базовая и основная сущность Kafka. Это логическое объединение нескольких партиций.
Порядок потребления сообщений на уровне топика не гарантирован, если топик имеет несколько партиций. По умолчанию топик создается с 1 партицией.
Время, которые сообщения хранятся в топике и максимальный объем сообщений определяются с помощью специальных параметров топика.
Partition (раздел) - это единицы хранения сообщений, которые хранятся в топике.
Топик - это логическое объединение, а партиция - физическая единица, она хранится на диске.
Партиция представляет собой последовательность сообщений (лог). Поставщик можно добавлять сообщение в партицию, но не может удалять.
При отправке, если поставщик не указывает в сообщении ключ партиции, первое сообщение Kafka сохраняет в произвольную партицию, а все последующие распределяет по кругу (round-robin). Kafka хранит все сообщение с одним ключом в одной и той же патриции.
Каждому новому сообщению в партиции присваивается Id на одну единицу больше предыдущего. Этот id называют смещением (offset).
Еще одно важное уточнение, партиция всегда привязана к брокеру. Т.е. у одного топика могут быть партиции в нескольких брокерах, но одна партиция всегда существует только в одном брокере.

Офсет (смещение) - это индекс, указывающий на положение записи в партиции.
Kafka не отправляет сообщения потребителям напрямую. Вместо этого потребители должны сами извлекать сообщения из топиков. Потребитель подключается к разделу и читает сообщения в том порядке, в котором они были записаны.
В этот момент смещение сообщения работает как курсор на стороне потребителя. Потребитель отслеживает, какие сообщения он уже прочитал, основываясь на положении курсора. После прочтения сообщения потребитель перемещает курсор на следующее сообщение и продолжает работу. Продвижение вперед и запоминание последнего смещения в разделе происходит исключительно на стороне потребителя.
Запоминая положения курсора для каждого раздела, потребитель может присоединиться к разделу в любой момент и возобновить чтение начиная от туда. Это поможет, например, чтобы возобновить работу после после сбоя системы на стороне потребителя.
Раздел может потребляться одним или несколькими потребителями, каждый из которых читает с разным смещением.
В Kafka есть концепция групп потребителей (Consumer Group), в которой несколько потребителей группируются для использования определённого топика.
Такая концепция гарантирует, что сообщение будет прочитано только одним потребителем в группе.
Такой подход можно применять тогда, когда одного потребителя недостаточно, что бы читать все партиции из определенного топика, а работая в группе - потребители автоматически ребалансируют работу между собой.
Такая стратегия позволяет добавить хорошей отработки отказов. Например, у нас есть N+1 потребителей для топика с N партициями, то есть первыми N потребителям будет назначены партиции, а оставшийся потребитель будет бездействовать, если только один из N потребителей не выйдет из строя, тогда ожидающему потребителю будет назначена его партиция.

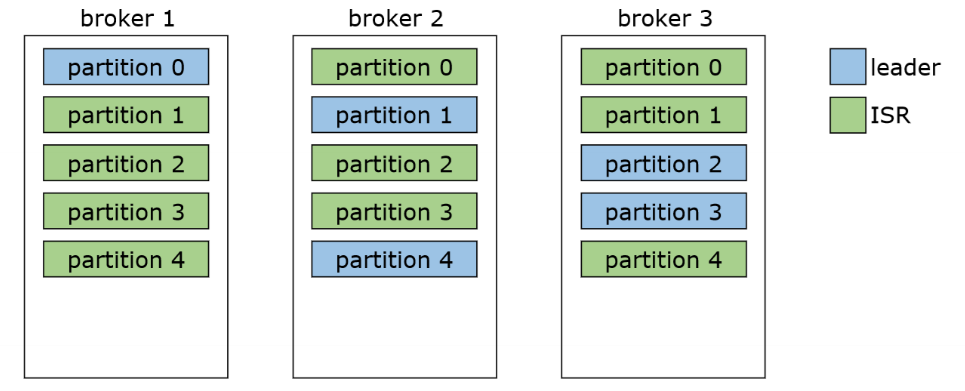
Для того, что бы лучше разобраться в репликации, представим, что у нас есть 3 брокера, в которые помещен один топик, имеющий 4 партиции (которые распределены по созданным брокерам).
replication factor (количество реплик) для этих партиций установим в количестве 2. То есть для каждого из партиции будет создано по 2 реплики.
Один брокер хранит только одну реплику, следовательно не может быть больше реплик, чем число брокеров!
Каждая партиция должна иметь своего лидера, а остальные реплики будут за ней следовать. Такого лидера назначает Контроллер.
Контроллер - это брокер, который координирует работу кластера.
Лидер отвечает за запись в конкретную позицию. Не может быть несколько лидеров у одной партиции, иначе каждый из них писал бы что-то свое.
Данные, которые пишутся в Лидера, должны быть скопированы по репликам. Те реплики, которые скачивают данные из Лидера, называются follower. Реплики, которые полностью идентичны по составу данных с лидером, называют ISR (In-Sync Replica).
Если партиция с Лидером стала недоступна, Контроллер назначит нового лидера из числа follower. Следовательно, при восстановлении упавшей партиции, она становится follower.
Acknowledgement (ack) - подтверждение записи. Это настройка, с помощью которой Producer может убедиться, что данные записались.
- acks = 0: Продюсер передает сообщение в топик и не дожидается никакого подтверждения об успешности сохранения данных;
- acks = 1: Продюсер передает сообщение в топик и ждет, пока сообщение будет сохранено (в Лидера партиции) и ему вернется подтверждение об успехе;
- acks = all: Продюсер передает сообщение в топик, Лидер партиции сохраняет данные у себя и только после того, как все его follower скачали данные, брокер вернет подтверждение об успехе. Количество followers, в которые нужно записать данные, для положительного ответа, можно регулировать.
Как мы помним, топик - это логическое объединение, а партиции - физическое. Теперь рассмотрим, как партиции хранятся на жестком диске.
Представим, что мы создали топик с 3 партициями:
kafka-topics --create --topic first-topic --bootstrap-server localhost:9092 --replication-factor 1 --partitions 3
У нас будут созданы 3 папки: first-topic-0, first-topic-1 и first-topic-2, каждая из них будет содержать в себе следующие файлы:
10M 00000000000000000000.index
0M 00000000000000000000.log
10M 00000000000000000000.timeindex
0M leader-epoch-checkpoint
0M partition.metadata
Отправим два сообщения в топик с помощью команды kafka-console-producer --topic first-topic --broker-list localhost:9092
Отправленные сообщения заняли две партиции и записались в файлы *.log (ранее пустые) в папках first-topic-1 и first-topic-2.
Партиция - не минимальная единица хранения данных в Kafka. Каждая партиция разделена на сегменты, Kafka не хранит все сообщения в одной партиции (другими словами в одном файле), а разделяет их на части - сегменты.
Такой подход позволяет упросить работы с данными, их поиском и удалением (в т.ч. целых сегментов).
Нули (00000000000000000000) в наименованиях файлов в каждой папке партиции - это и есть имя сегмента.
Kafka записывает сообщение в файлы сегментов только в рамках одной партиции, причем всегда есть активный сегмент для записи. Когда Kafka достигает лимита по размеру сегмента (по умолчанию 1Gb) или по заданному временному лимиту, создается новый файл сегмента, который станет активным.
В имени каждого файла сегмента отражается смещение (офсет) от первого сообщения.
Представим, что сегмент вмещает только 3 сообщения, тогда на следующем сообщении Kafka автоматически создаст новый сегмент с именем "...0003" и сделает его активным.
Так как офсет и наименование сегмента у нас связаны напрямую, мы можем быть уверены, что все сообщения с офсетом до 3 находятся в сегменте "...0000", с 3 до 6 в "...0003" и т.д.
Стоит еще сказать о файле *.index.
Поиск сообщений с определённым офсетом в файле *.log довольно затратный, в виду того, то этот файл может достигать большого объема.
Для этого нужен файл *.index. Он хранит в себе 2 поля - офсет и физическое расположение сообщения в файле *.log. Такой способ позволяет быстро находить нужную запись в *.log
 Но не каждое сообщение будет иметь соответствующую запись в индексе. Параметр конфигурации
Но не каждое сообщение будет иметь соответствующую запись в индексе. Параметр конфигурации index.interval.bytes, который по умолчанию равен 4096 байт, задает интервал индекса, который в основном описывает, как часто (через сколько байтов) будет добавляться запись индекса.
За размера файла *.index отвечает параметр segment.index.bytes, который по умолчанию равен 10 МБ.
Стоит добавить, что похожим образом устроен файл *.timeindex. Он необходим для поиска сообщений по времени.
ZooKeeper - это сервис, который используется для обслуживания данных имен и конфигурации, а также для обеспечения гибкой и надежной синхронизации в распределенных системах. Zookeeper отслеживает статус узлов кластера Kafka, а также отслеживает темы Kafka, разделы и т.д.
Установка Windows:
- Прежде чем приступить к установке, убедитесь, что установлена Java и добавлена переменная JAVA_HOME
Проверить можно с помощью команд "java -version" и "echo %JAVA_HOME%" - Скачиваем Zookeeper - https://zookeeper.apache.org/releases.html#download
- Распаковываем
tar -xvf apache-zookeeper-3.7.0-bin.tar.gz
tar.exe является средством архивирования данных в Windows 10.
используемые параметры:
-x- извлечь файлы из архива;
-v- подробный режим вывода информации на экран;
-f< filename > - путь и имя файла архива. - Копируем файл conf/zoo_sample.cfg и меняем название на zoo.cfg
- В файле zoo.cfg прописываем путь до директории, например:
dataDir=E:\\Java\\Kafka\\apache-zookeeper-3.8.0-bin, обратите внимание на формат записи! - Создаем системную переменную ZOOKEEPER_HOME, прописываем путь до директории - "...\apache-zookeeper-3.7.0" и добавляем в Path - "%ZOOKEEPER_HOME%\bin".
Проверить корректность созданных переменных можно с помощью команд "echo %ZOOKEEPER_HOME%" и "echo %Path%" - Запускаем в командной строке командой
zkserverили вручную, файлом zkServer.cmd
Kafka - распределенный программный брокер сообщений.
Установка Windows:
- Скачиваем - https://kafka.apache.org/downloads (binary дистрибутив)
- Создаем в корне папку data, а в ней две подпапки - zookeeper и kafka-logs.
- В файле config/zookeeper.properties находим и изменяем строку на dataDir=C:/kafka-2.7.0/data/zookeeper
- В файле config/server.properties находим и изменяем строку на log.dirs=C:/kafka-2.7.0/data/kafka-logs
Обратите внимание на формат записи в этих двух файлах, должна быть правая косая черта! - Открываем cmd в папке bin\windows и запускаем zookeeper:
zookeeper-server-start.bat ../../config/zookeeper.properties
далее в новом окне запускаем kafka:
kafka-server-start.bat ../../config/server.properties
Возможные ошибки:
- the input line is too long - следует разместить дистрибутив диске C и сократить наименование, например kafka_2.12-2.7.0 > kafka-2.7.0;
- Classpath is empty. Please build the project first e.g. by running 'gradlew jarAll' - нужно скачать binary дистрибутив, а не source.
После запуска zookeeper и kafka можно взаимодействовать с ними с помощью командой строки.
Следующие команды работают для Windows и Kafka 3.2.3, предварительно открыв cmd в bin\windows
Создание топика: kafka-topics --create --topic test-topic --bootstrap-server localhost:9092 --replication-factor 1 --partitions 4
Показать список топиков: kafka-topics.bat --bootstrap-server localhost:9092 --list
Kafkatool (или Offset Explorer) - это графический интерфейс Kafka.
Установка
- Скачать дистрибутив https://www.kafkatool.com/download.html
- После установки создать новое подключение.
Параметр Cluster name может быть любым;
Параметр Kafka Cluster Version устанавливаем в зависимости от версии Kafka.
После успешного подключения нам доступна информация о всех брокерах, консьюмерах и топиках.
Например, можно зайти в топик my_topic (созданный в примере выше) и во вкладке Data посмотреть все отправленные продюсером сообщения (предварительно нажав кнопку Retrieve Messages).
Во вкладке Properties можно указать Content Types для Key и Value, т.е. корректный тип для отображения ключа и значения сообщений.
Conduktor - это графический интерфейс Kafka.
Установка
- Скачать дистрибутив - https://www.conduktor.io/download/
- Установить и запустить. Сервер Kafka должен подхватиться автоматически.
После успешного подключения нам доступна информация о всех брокерах, консьюмерах и топиках.
Например, можно зайти в топик my_topic (созданный в примере выше). Для этого заходим во вкладку Topics, выбираем топик и нажимаем View the data ..., после этого откроется окно с детальной информацией о топике, включая настройки типа данных для параметров ключ-значение.
После нажатия на кнопку START программа будет монитирить новые входящие сообщения, а нажав кнопку Details у сообщения, можно увидеть его детальную информацию.
Создадим минимальный пример Продюсера и Консюмера:
С помощью spring-init создаем проект, добавляя spring-boot-starter-web и spring-kafka
Создаем контроллер для отправки сообщений:
@RestController
@RequestMapping("msg")
public class MsgController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping
public void sendMsg(String msgId, String msg){
kafkaTemplate.send("my_topic", msgId, msg);
}
}Объект KafkaTemplate<K, V> нужен для отправки сообщений. Первый параметр - это тип ключа, второй - самого сообщения.
Первым параметром метода send() является топик/тема, в которую будет отправляться сообщение, и на которую могут подписаться консьюмеры, чтобы их получать. Если топик, указанный в методе send() не существует, он будет создан автоматически.
Создаем слушателя:
@EnableKafka
@SpringBootApplication
public class KafkaApplication {
@KafkaListener(topics="my_topic")
public void msgListener(String msg){
System.out.println(msg); // выводим полученное сообщение
}
public static void main(String[] args) {
SpringApplication.run(KafkaApplication.class, args);
}
}Класс, в котором будет создаваться консьюмер, необходимо пометить аннотацией @EnableKafka.
В файле настроек application.property необходимо указать идентификатор консьюмера параметром groupe-id:
spring.kafka.consumer.group-id=kafka_test_appНастройка завершена. Теперь можно попробовать отправить POST-запрос через Postmen.
Указать URL http://localhost:8080/msg, а в теле запроса добавить параметры msgId:1 и msg:Hello world!
В случае успеха, в консоли должно отобразиться отправленное сообщение - Hello world!.
TAR - архивирование данных в Windows 10
Install Apache Kafka on Windows
Habr. Apache Kafka для чайников
GUI for Apache Kafka
Habr. Настройки и требования Kafka
Что такое Apache Kafka
Habr. Apache Kafka: основы технологии
Habr. Практический взгляд на хранение в Kafka
Harb. Григорий Кошелев – А вы Кафку пробовали