Java SE - DmitryGontarenko/usefultricks GitHub Wiki
- JVM, JRE, JDK
- JVM Memory Model
- Access modifiers
- Data types
- Autoboxing & Unboxing
- Type Casting
- Overriding & Overloading
- Initialization block
- Abstract modifier
- Static modifier
- Final modifier
- Interface
- Enum
- VarArgs
- Array
- Exceptions
- Collections
- Object
- Comparable and Comparator
- Nested classes
JVM (Java Virtual Machine) - основная часть исполняющей системы Java, это виртуальная машина, которая исполняет байт-код Java, предварительно созданный из исходного кода Java-программы компилятором Java (javac). JVM может также использоваться для выполнения программ, написанных на других языках программирования.
Программы, предназначенные для запуска на JVM, должны быть скомпилированы в виде файлов «.class». Программа может состоять из множества классов, размещённых в различных файлах. Для облегчения размещения больших программ, часть файлов вида «.class» может быть упакована вместе в так называемом «.jar»-файле (сокращение от «Java Archive»).
Javac - компилятор языка java, включенный в состав многих Java Development Kit (JDK).
Компилятор принимает исходные коды, соответствующие спецификации Java language specification (JLS), и возвращает байт-код, соответствующий спецификации Java Virtual Machine Specification (JVMS).
JRE (Java Runtime Environment) - исполнительная система, минимальная реализация виртуальной машины, необходимая ТОЛЬКО для исполнения Java-приложений, без компилятора и других средств разработки. Состоит из виртуальной машины (JVM) и библиотек Java классов.
JDK (Java Development Kit) - это комплект разработчика приложений на языке Java (от компании Oracle), включающий в себя компилятор Java (javac), стандартные библиотеки классов Java, примеры, документацию, различные утилиты и исполнительную систему Java (JRE).
В состав JDK не входит среда разработки на Java, поэтому разработчик, использующий только JDK, вынужден использовать внешний текстовый редактор и компилировать свои программы, используя утилиты командной строки.
Все современные среды разработки для компиляции Java-программ используют компилятор из комплекта JDK. Поэтому эти среды требуют для своей работы предварительной инсталляции JDK на машине разработчика.
Коротко: JDK - среда для разработки программ на Java, включающая в себя JRE - среду для обеспечения запуска Java программ, которая в свою очередь содержит JVM - интерпретатор кода Java программ.
Для работы через консоль с Java в Windows, необходимо установить переменные окружения для Java-инструментов, а именно: JRE, JDK, Gradle и Maven.
Для этого необходимо зайти в Мой Компьютер -> Дополнительные параметры системы -> Переменные среды (на вкладке Дополнительно) -> в окне Системные параметры найти переменную Path -> нажать на кнопку Изменить и добавить все нужные параметры (путь до исполняемого файла) через точку с запятой, например: C:\Program Files\Java\jdk1.8.0_191\bin;C:\Program Files\Java\jre1.8.0_191\bin;G:\Java\gradle-5.6.3\bin;G:\Java\apache-maven-3.3.9\bin.
После этого можно проверить, установились ли правильные значения пути - для этого выведем поочередно версии всех инструментов:
java -version
gradle -v
mvn --version
Ниже будет описана реализация памяти в HotSpot. HotSpot - это реализация виртальной Java машины (JVM) для клиентского и серверного аппаратного обеспечения, разработанная Sun/Oracle.
Память делится на heap (кучу) и stack (стек).
Область памяти Стек работает по схеме LIFO (Last-In-First-Out, последним зашел-первым вышел). Память стека содержит только локальные примитивные переменные и ссылки на объекты в области heap. Всякий раз, когда вызывается новый метод, содержащий примитивы и ссылки на объекты, то на вершине стека под них выделяется блок памяти. Когда метод заверщает свое выполнение, блок памяти, выделенный для него, очищается и становится доступен для другого метода.
Особенности стека:

- Переменные в стеке существуют до тех пор, пока выполняется метод, в котором они были созданы;
- Если память стека будет заполнена, Java выбросит исключение
java.lang.StackOverFlowError; - Доступ к stack осуществляется быстрее, чем к heap;
- Stack является потокобезопасным, поскольку для каждого потока создается отдельный стек.
Эта область памяти используется для хранения объектов и классов. Новые объекты всегда создаются в куче, а ссылки на них хранятся в стеке. Такие объекты имеют глобальный доступ и могут быть получены в любом месте программы.
Область памяти Heap разбита на несколько более мелких частей - Young Generation (Eden + Survive) и Old (Tenured) Generation.
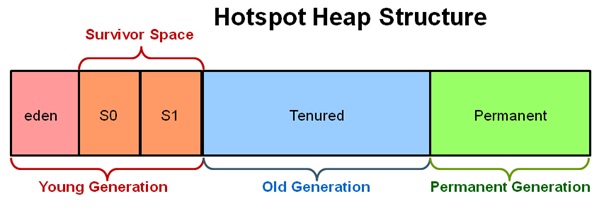
Особенности heap:
- Heap существует до конца выполнения приложения;
- При переполнении этой области памяти Java выбросит исключение
java.lang.OutOfMemoryError; - Доступ медленнее, чем к стеку;
- Эта область памяти, в отличии от стека, автоматически не освобождается. Для сбора неиспользуемых объектов используется Garbage Collectors (сборщик мусора);
- Эта область памяти не является потокобезопасной.
Рассмотрим небольшой пример:
int i1 = 1;
Integer i2 = 2;Если i1 и i2 являются локальными переменными метода, то i помещается в стек, i2 также помещается в стек, но как ссылка на объект Integer в куче.
Если же i1 и i2 являются полями класса, то i1 помещается в кучу как часть экземпляра или класса, i2 помещается в кучу.
Для повышения производительности JVM, Heap разбивается на более мелкие части или поколения, такие как: Young и Old (Tenured). Такую организацию памяти используют сборщики Serial, Parallel, CMS (подробнее ниже).
-
Young Generation - эта область где размещаются недавно созданные объекты. Когда она заполняется, происходит быстрая сборка мусора (minor collect). Эта область памяти состоит из трех областей:
- Eden space - в этой области выделяется память под все создаваемые программой объекты. Большая часть из них живет не долго (например, локальные переменные) и удаляются при выполнении сборки мусора. Когда данная область заполняется - GC выполняет быструю (minor collect) сборку мусора, а объекты, на которые есть ссылки, перемещает в следующую область S0.
-
Survivor space - содержит две области - S0 и S1. Сюда перемещаются объекты из предыдущей области памяти, после того, как они пережили сборку мусора. Время от времени, долгоживущие объекты перемещаются в Old Generation.
При последующем Minor GC "выжившие" объекты перемещаются из области S0 в S1, а на их место приходят новые "выжившие" из Eden, после чего Eden полностью очищается. Однако при следующем Minor GC область Survivor переключается и все "выжившие" объекты перемещаются в S0, таким образом очищая Eden и S1.
Каждая такая итерация повышает порог "старения" объектов.
Но если в процессе копирования "живых" объектов, в области назначения (From Survivor Space) закончится доступное место, все объекты из Eden и области копирования (To Survivor Space) переместятся в Old Generation, независимо от того, сколько сборок мусора они пережили.
-
Old Generation - здесь скапливаются долгоживущие объекты (например, синглтоны и менеджеры объектов). Как правило, для объектов "молодого поколения" устанавливается порог, при достижении которого объекты перемещается в эту область. Когда заполняется эта область памяти, выполняется полная сборка мусора (major collect), которая обрабатывает все созданные JVM объекты.
Если размер объектов слишком велик, создавать их в Eden и перемещать потом между областями Survivor слишком затратная операция, поэтому они могут помещаться срзу в Old Generation.
Но помимо heap, JVM управляет еще одной областью памяти - non-heap, она как и heap - создается при запуске JVM и содержит следующие разделы:
-
Permanent Generation (non-heap) - здесь хранятся метаданные, необходимые JVM для описания классов и методов, используемых в приложении. Классы могут быть собраны, если JVM обнаружит, что они больше не нужны, и может потребоваться место для других классов. Область Permanent включена в полную сборку мусора (Major Collect).
Хотя область Permanent Generation и представлена на диаграмме выше в составе heap, по факту она не является частью heap, и не может перемещать объекты в памяти.
Permanent Generation заменена на область Metaspace в Java 8. Metaspace может увеличивать свой размер, в отличии от Permanent Generation. - Code Cache (non-heap) - HotSpot также включает кэш, который используется для компиляции и хранения собственного кода.
Minor Garbage collection - является событием "Stop The World". Это означает, что все потоки приложения останавливаются до завершения операции.
Major Garbage collection - также является событием Stop the World. Как правило медленнее чем Minor Collect, потому что включет в себя проверку всех созданных объектов.
В Java процесс освобождения памяти обрабатывается GC, основной процесс может быть описан следующим образом:
- Маркировка - на этом шаге сборщик мусора проводит сканирование объектов на которые нет ссылок и помечает их.
- Обычное удаление - удаляет только те объекты, на которые нет ссылок. Распределитель памяти содержит ссылки на блоки свободного пространства, где может быть размещен новый объект.
- Компактное удаление - для дальнейшего повышения производительности помимо удаления объектов, на которые нет ссылок, существует возможность сжать оставшиеся объекты. Перемещение ссылочных объектов "в начало" области памяти, делает новое выделение памяти намного быстрее.
В JDK 6 представлено 3 сборщика мусора: SerialGC (последовательный), ParallelGC (параллельный) и Concurrent Mark Sweep GC (совместный).
SerialGC используется по умолчанию в Java 5 и 6. Он всегда выполняет Minor и Major сборку последовательно (с использованием одного виртуального ЦП).
В случае, если в Old Generation уже не хватает места для новых объектов, выполняется Major Collect. При этом после удаления "мертвых" объектов из области Old Generation, производится не перенос (переносить их некуда), а уплотнение. Такой механизм называется Mark-Sweep-Compact по названию его шагов - пометить выжившие объекты, очистить память от "мертвых" объектов, уплотнить выжившие объекты (переместить в начало области памяти). В результате чего, свободная память после очистки, представляет собой непрерывную область, это позволяет выделять память для новых объектов намного быстрее.
-XX:+UseSerialGC - данная опция командной строки включает SerialGC.
ParallelGC использует несколько потоков для сборки мусора. По умолчанию, имея N процессоров, для сборки мусора будет использовано N потоков. Но на хосте с одним ЦП будет использоваться сборщик мусора по умолчанию, даже если запрошен параллельный сборщик. Количество потоков сборки мусора можно настраивать вручную.
Каждый поток ParallelGC получает свой участок памяти в области Old Generation, так называемый буфер повышения (promotion buffer), куда только он может переносить данные, чтобы не мешать другим потокам. Такой подход ускоряет сборку мусора, но имеет и небольшое негативное последствие в виде возможной фрагментации памяти.
ParallelGC имеет две вариации:
-XX:+UseParallelGC - с помощью данной опции можно получить многопоточный сборщик Young Generation с однопоточным сборщиком Old Generation. Эта опция также выполняет уплотнение Old Generation в однопоточном режиме.
-XX:+UseParallelOldGC - опция является как многопоточным сборщиком для молодого, так и для старого поколения. При этом уплотнение происходит только в Old Generation, в многопоточном режиме.
CMS нацелен на снижение максимальных задержек путем выполнения части работ по сборке мусора параллельно с основными потоками приложения.
CMS для сборки мусора в Young Generation использует тот же алгоритм, что и параллельный сборщик (ParallelGC), но для Old Generation отличается - в этом случае сборка не затрагивает область Young.
Важным отличием сборщика CMS от рассмотренных ранее является также то, что он не дожидается заполнения Old Generation для того, чтобы начать "старшую" сборку. Вместо этого он работает в фоновом режиме постоянно, пытаясь поддерживать Old Generation в компактном состоянии.
-XX:+UseConcMarkSweepGC - запуск CMS
Сборщик мусора G1 доступен в Java 7, он имеет измененный подход к организации heap. Здесь память разбивается на множество регионов одинакового размера. Исключение составляют только так называемые громадные (humongous) регионы, которые создаются объединением обычных регионов для размещения очень больших объектов.
Разделение регионов на Eden, Survivor и Old Generation в данном случае логическое, регионы одного поколения не обязаны идти подряд и даже могут менять свою принадлежность к тому или иному поколению.
Minor Collect для Young Generation происходит аналогично ранее рассмотренным GC, но выполняется в несколько потоков и не на всем поколении, а только на части регионов (при этом выбирая наиболее "загруженные", отсюда и название - Garbage First).
Полная сборка мусора в G1 называется Mixed Collect, в нем происходит "цикл пометки" (marking cycle, подробнее в источниках).
При заполнении всех регионов, G1 выполнит полную сборку мусора во всем heap с остановкой всех потоков.
-XX:+UseG1GC - запуск G1
Habr: про устройство памяти и GC в целом (Дюк, вынеси мусор! Часть 1)
Habr: подробно о Serial и Parallel GC (Дюк, вынеси мусор! Часть 2)
Habr: подробно о CMS и G1 GC (Дюк, вынеси мусор! Часть 3)
Habr: JVM изнутри – организация памяти внутри процесса Java
Habr: Java 8: от PermGen к MetaSpace
Topjava: Стек и куча в Java
StackOverFlow: PermGen is part of heap or not?
Medium: Understanding Java Memory Model
YouTube: Владимир Иванов — G1 Garbage Collector
Основы сборки мусора в Hotspot JVM
Oracle: Java Garbage Collection Basics
IBM: Garbage collection roots
public – публичный класс или член класса.
private – закрытый класс или член класса, доступен только для своего класса.
protected – такой член класса доступен из любого места в текущем класса, пакете или производном классе.
default – модификатор по умолчанию (отсутствие модификатора), такие поля или методы видны всем классам в текущем пакете.
- При объявлении классов и интерфейсов могут использоваться только два типа модификатора:
publicилиdefault. Это ограничение не касается вложенных классов. - Модификаторы доступа можно в произвольном порядке чередовать с еще несколькими ключевыми словами:
final,abstractилиstrictfp.
| Class | Package | Subclass (same pkg) | Subclass (diff pkg) | World | |
|---|---|---|---|---|---|
| public | + | + | + | + | + |
| protected | + | + | + | + | |
| no modifier | + | + | + | ||
| private | + |
В Java есть 8 примитивных типов, которые делят на 3 группы:
- Целые числа – byte, short, char, int, long;
- Числа с плавающей запятой – float, double;
- Логический – boolean.
| Тип | Размер | Диапазон |
|---|---|---|
| byte | 8 бит | От -128 до 127 |
| short | 16 бит | от -32768 до 32767 |
| char | 16 бит | беззнаковое целое число, представляющее собой символ UTF-16 (буквы и цифры) |
| int | 32 бит | от -2147483648 до 2147483647 |
| long | 64 бит | от -9223372036854775808L до 9223372036854775807L |
| float | 32 бит | от -3.402,823,5 E+38 до 1.4 E-45 |
| double | 64 бит | от -1.797,693,134,862,315,7 E+308 до 4.9 E-324 |
При инициализации переменных long, float и double, в конце значения переменной желательно указывать обозначения типа (L, f или d, регистр не важен), например:
long numl = 123_456_789L;
float numf = 32.125F;
double numd = 45.34d;Потому как без обозначения типа для поля float - компилятор посчитает что мы передаем тип double.
В случае с полем типа Long (т.е. это объект, а не примитив) - компилятор будет считать, что мы инициализируем поле типом int.
Для операции с деньгами рекомендуется использовать тип BigDecimal, а не float или double.
Ссылочные типы - это все остальные типы: классы, перечисления (Enum) и интерфейсы, а так же массивы.
Значение типов данных по умолчанию:
| Тип | Значение |
|---|---|
| byte, short, int, long | 0 |
| float, double | 0.0 |
| char | '\u0000' |
| boolean | false |
| Объекты (в том числе String) | null |
Обертка - это специальный класс, который хранит внутри себя значение примитива.
Поскольку это именно класс, он может создавать свои экземпляры. Они будут хранить внутри нужные значения примитивов, при этом будут являться настоящими объектами.
Названия классов-оберток схожи с названиями соответствующих примитивов:
| Тип | Класс-обертка |
|---|---|
| byte | Byte |
| short | Short |
| char | Character |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| boolean | Boolean |
Главным преимуществом Объектов над примитивами является наличие методов. Например:
String text = "112";
Integer num = Integer.parseInt(text); // преобразовали строку в число
String num_text = num.toString(); // преобразовали число в строку с помощью метода toString();
System.out.println(Double.MAX_VALUE); // получили максимальное значение типаТак же при использовании коллекций, просто необходимо значения примитивных типов каким-то образом представлять в виде объектов. Потому как обобщенные типы (Generics) должны быть ссылочными типами. Поскольку примитивы не расширяют класс Object, их нельзя использовать в качестве аргументов обобщенного типа для параметризованного типа.
Для более быстрой работы. Ведь переменные примитивного типа напрямую содержат свои значения. Примитивы хранятся в стеке, куда намного быстрее получить доступ, чем к объектам (wrapper`ам), которые хранятся в куче.
Автоупаковка (autoboxing) - это преобразование примитивного типа в соответствующий ему класс-обертку (оборачивание примитива в объект)
Autoboxing происходит:
- При присвоении значения примитивного типа переменной соответствующего класса-обертки;
- При передачи примитивного типа в параметр метода, ожидающего соответствующий ему класс-обертку.
Integer num1 = new Integer(5); // обычное создание
Integer num2 = 5; // автоупаковка соответствующего типа
method(7); // передача примитива в метод
public void method(Integer i) {...} // метод ожидает объект IntegerРаспаковка (unboxing) - это преобразование класса-обертки в соответствующий ему примитивный тип.
Unboxing происходит:
- При присвоении экземпляра класса-обертки переменной соответствующего примитивного типа;
- При передачи объекта класса-обертки в метод, ожидающий соответствующий примитивный тип. Но стоит отметить, что если для такого метода реализована перегрузка с соответствующим классом-оберткой, вызовется именно он;
Integer number = new Integer(5);
int i = number; // распаковка
method(number); // передаем в метод объект типа Integer
public void method(int i) {...}; // метод ожидает примитив- Если класс-обертка содержит null, при распаковке возникнет исключение NullPointerException;
- В выражениях, где один или два аргумента являются экземплярами классов-оберток (кроме операции == и !=).
Так как арифметические операторы и операторы сравнения (кроме == и !=) применяются только к примитивным типам. При сравнении классов-оберток оператором == или != происходит сравнение по ссылкам, а не по значениям, и может возникнуть путаница.
Integer obj1 = 100;
Integer obj2 = 100;
System.out.println(obj1 == obj2); // true
Integer obj3 = new Integer(120);
Integer obj4 = new Integer(120);
System.out.println(obj3 == obj4); // false
Integer obj5 = 200;
Integer obj6 = 200;
System.out.println(obj5 == obj6); // falseОбъяснение:
В первом случае объекты не создаются, а берутся из Integer pool (набор инициализированных и готовых к использовании объектов), который кэширует объекты от -128 до 127 и при повторном использовании обращается к ним.
Во втором случае происходит явное создание объектов, следовательно они имеют разные ссылки.
В третьем случае создаются два объекта, потому что "200" не входят в диапазон Integer pool и они имеют разные ссылки на объект.
Java Wrapper Classes Internal Caching
При работе с примитивами существует такое понятие как приведение типов. Существует два вида приведения (преобразования):
- неявное (с расширением/upcasting);
Если тип становится «старше» (был int, а стал long), то он расширяется (из 32 бита в 64). В этом случае нет риска потерять данные, т.к. все что помещалось в int, поместиться и в long.
В таком порядке преобразование будет без потерь:
byte->short->char->int->long->float->double. - явное (сужающее/downcasting).
Преобразование в обратную сторону (был long, а стал int), требует от нас явного преобразования (явного указания типа). Т.к. в этом случае есть риск потерять данные и Java не будет проводить такое преобразование автоматически.
В таком порядке преобразования возможна потеря точности и требует явного указания типа:
double->float->long->int->char->short->byte
double num1 = 10d;
int num2 = (int)10; // явное преобразованиеСвойства преобразования:
- При арифметических операциях с типом double, результат всегда будет преобразован в double, т.е. если переменную типа byte, short, int, long или float сложить с переменной типа double, результатом всегда будет double. Исходя из этого, переменная которая будет принимать результат сложения должна быть double.
- То же правило действует для всех остальных типов данных, результат будет всегда иметь самый «старший» тип данных.
- Если достигнуто максимальное значение примитива, например, диапазон типа
byteот -128 до 127, для того, что бы увеличить значение переменной, потребуется явное указании типа. После этого, значение такой переменной будет "перекручено":
byte b2 = (byte) (127 + 1);
System.out.println(b2); // -128Overloading (Перегрузка метода) – это создание методов с одинаковыми именами, но разным количеством параметров и/или их типом.
- Различие в типе возвращаемого значения метода перегрузкой не считается.
- Статические методы могут перегружаться нестатическими и наоборот.
- При передачи параметра методу, который имеет перегрузку, например:
method(5); // вызываем метод
method (Integer i){...} // метод 1
method (double i){...} // метод 2Предпочтение будет отдано расширению типов, а не автобоксингу, т.е. вызовется метод 2, который принимает аргумент типа double.
Override (Переопределение метода) – это возможность подкласса изменять поведение уже существующего метод из суперкласса. Метод переопределения имеет то же возвращаемое значение и сигнатуру, что и у метода, который он переопределяет.
- При переопределении метода можно использовать аннотацию
@Override– она указывает что мы собираемся переопределять метод суперкласса и служит лишь для контроля успешности действий при сборке проекта. Без этой аннотации перегрузка все равно произойдет, но в случае не совпадения сигнатур с методом, который мы собираемся переопределить, может возникнуть трудноуловимая ошибка, создаться отдельный независимый метод. - При переопределении метода нельзя сузить его модификатор доступа.
- При переопределении метода изменить тип возвращаемого значения нельзя, но можно сузить тип возвращаемого значения (пример указать тип подкласса).
- Переопределить статический метод нельзя.
Блок инициализации (далее БИ) – это один из элементов (по мимо полей и классов) который может входить в состав класса. Все действия в БИ происходят в момент инициализации.
- Если БИ несколько, они будут выполнятся в порядке следования.
- БИ могут быть статическими, они выполняются при первом обращении к классу.
- добавить пример кода и еще свойств
Абстрактные классы призваны предоставлять базовый функционал для классов-наследников, а они в свою очередь уже реализуют этот функционал.
Абстрактные методы – это методы, которые не имеют реализации.
public abstract class Output {
abstract void show();
public String text() {
return "Hello!";
}
}
public class Input extends Output {
@Override
void show() {
System.out.println(text()); // Hello!
}
}Свойства модификатора abstract:
- Если в классе есть хотя бы один абстрактный метод, класс должен быть абстрактным.
- Абстрактные классы могут содержать не абстрактные методы и поля, статические в том числе.
- Если класс наследуется от абстрактного класса, он обязан переопределить все абстрактные методы этого класса.
- Абстрактные методы не могут быть private.
- Абстрактный метод не может быть static, т.к. модификатор abstract показывает, что метод будет реализован в другом классе, а static наоборот указывает, что метод будет доступен по имени класса.
- Абстрактные классы не могут быть с модификатором final. Так как абстрактные классы нужно наследовать, а final это запрещает.
- В абстрактных классах есть конструкторы. Но мы не можем создать экземпляр абстрактного класса не потому что у него нет конструктора, а потому что мы через экземпляр абстрактного класса не можем вызвать метод без тела.
- Если вызвать метод экземпляра класса, который реализует абстрактный класс, первым будет вызов конструктора абстрактного класса.
- Экземпляр абстрактного класса можно создать исключительно путем полиморфных ссылок. Абстрактный класс подразумевает, что у него обязательно должны быть наследники, которые реализуют его абстрактные методы. Нет смысла создания абстрактного класса без наследника. Пример:
Animal instance = new Dog(); // класс Animal абстрактныйМодификатор static - говорит о том, что метод или поле принадлежат не объекту, а классу. То есть доступ можно получить не создавая объект класса.
Свойства модификатора static:
- Поля помеченные static инициализируются при инициализации класса;
- Статические методы могут вызывать только другие статические методы;
- Статические методы осуществляют доступ только к статическим полям;
- Статические методы не могут ссылаться на членов класса с помощью ключевых слов
thisилиsuper.
Модификатор final - говорит о том, что член класса неизменяемый. Может быть применен к полям, методам или классам.
- Класс final не может иметь наследников и все его методы косвенным образом приобретают свойство final.
- Метод final не может быть переопределен (override) в классах наследниках.
- Поле final необходимо явным образом инициализировать. Это можно сделать непосредственно при объявлении, в поле инициализации, либо в конструкторе того класса, в котором оно объявлено; поле final не сможет изменить свое значение после инициализации. Наследникам оставлять инициализацию final нельзя.
Интерфейс - это набор сигнатур методов. Интерфейс используется для создания полностью абстрактных классов.
Свойства интерфейса:
- При объявлении интерфейсов могут использоваться только два типа модификатора:
publicи по умолчанию. - Методы в интерфейсах по умолчанию
public abstract. - Все поля интерфейса по умолчанию являются константой и имеют модификатор
public final static. - Отсутствует конструктор.
- Интерфейс не может содержать конкретных методов.
- Интерфейс может расширять (extends) один или несколько других интерфейсов. Ничего кроме интерфейсов он расширять не может.
- Интерфейс не может реализовать (implements) другие интерфейсы.
- Метод не может быть помечен как
final, так как его нельзя будет реализовать. - Абстрактным классам не обязательно реализовывать методы интерфейса при «наследовании».
- Коллизия может произойти если интерфейс наследует методы других интерфейсов с одинаковыми именами, но разными типами возвращаемого значения.
Интерфейс-маркер - шаблон-проектирования, который позволяет связать метаданные с классом. Маркер лишь является признаком наличия определённого поведения у объектов класса, помеченного маркером. Пример применения маркеров-интерфейсов является интерфейс Serializable.
В современных языках программирования вместо этого могут применяться аннотации.
Enum - это пользовательский тип перечисления, который содержит константы. Можно использовать как хранилище состояния, в зависимости от которого производятся некоторые действия.
Рассмотрим на примере.
Создадим перечисление, которое будет содержать только константы, а затем получим этим значения:
enum Status {
CONNECTED,
BLOCKED;
}
public class App {
public static void main(String[] args) {
System.out.println(Status.CONNECTED.name());
}
}Создадим Enum, который будет содержать сезоны года и температуру, в качестве конструктора:
public enum Seasons {
SPRING(21),
SUMMER(23) {
@Override
void hobby() {
super.hobby();
System.out.println("and swimming");
}
},
AUTUMN(11),
WINTER(1);
private int temperature;
Seasons(int temperature) { this.temperature = temperature; }
public int getTemperature() { return temperature; }
void hobby() { System.out.println("walking"); }
} Seasons[] seasons = Seasons.values();
for (Seasons temp : seasons) {
System.out.println(temp.toString() +
", temperature = " + temp.getTemperature());
temp.hobby();
}
/* Output:
SPRING, temperature = 21
walking
SUMMER, temperature = 23
walking
and swimming
... */Еще один пример:
public enum CalcEnum {
SUM {
@Override
int calculate(int x, int y) {
return x + y;
}
};
abstract int calculate(int x, int y); // метод обязателен для реализации
}
System.out.println(CalcEnum.SUM.calculate(5, 5)); // 10Свойства Enum:
- По умолчанию имеет тип
int; - Элементы указываются через запятую, первый элемент по умолчанию идентифицируется как 0;
- Каждый элемент перечисления - константа (
final static), так что желательно именовать их большими буквами; - Может иметь конструктор;
- По умолчанию конструктор с модификатором
private - От Enum нельзя наследоваться;
- В Enum можно добавлять переменные, конструкторы, методы (в том числе и абстрактные) и блоки инициализации;
- У Enum есть характерные только для него методы:
-
values()- возвращает массив из всех хранящихся в Enum значений; -
ordinal()- возвращает порядковый номер константы; -
valueOf()- возвращает объект Enum, соответствующий переданному значению.
-
Variable Arguments (Аргументы переменной длины) - помогает нам обрабатывать произвольное количество параметров автоматически - помещая их в массив. Его синтаксис - method(int...array), с начало тип, три точки, а затем имя массива, который будет использоваться в рамках метода.
Когда мы вызываем такой метод, мы можем передавать туда как массив, так и несколько параметров.
method(array); // массив
method(new int[] {1,2,3}); // массив
method(1, 2, 3); // список параметров
// реализация
public void method(int...array) {
for (Integer temp : array) {
System.out.println(temp);
}
}Свойства varargs:
- varargs может иметь любой тип;
- В метод могут передаваться и другие параметры, но в этом случае параметр vararg должен быть последним;
- Из этого следует, что в методах может быть только один vararg параметр;
- Методы с varargs можно перегружать (Overloading), но такие методы будут использоваться в перегрузке в самую последнюю очередь.
Например, если в данном случае вызвать перегруженный метод, то отработает метод 1:
method(1, 2); // Вызываем перегруженный метод
void method(int i, int y) {...} // 1
void method(int...array) {...} // 2Массив - это набор однотипных элементов, которые расположены в памяти непосредственно друг за другом и доступ к которым осуществляется по индексу. Индекс массива - это целое число, указывающее на конкретный элемент массива.
Свойства массива:
- Длину массива после создания изменить нельзя;
- При объявлении массива рекомендовано придерживаться такого синтаксиса:
int[] array;- Объявление массива таким образом
String[] array[], означает создание двумерного массива строк; - При объявлении массива нельзя указывать его размер, так как память выделяется только в момент создания массива;
- Объявление массива таким образом
- При передачи в метод в качестве аргумента можно создать анонимный массив
method(new arra[]{1, 2, 3}), размер такого массива будет вычисляется исходя из его объявления.
Исключения делятся на несколько классов и все они имеют общего предка - класс Throwable, его потомками являются подклассы Exception и Error.
Exception является результатом ошибок в программе, которые можно предсказать (например, деление на ноль).
Error представляет собой более серьезные ошибки на уровне JVM (например, переполнение памяти).
Так же исключения делятся на два типа:
- контролируемые (checked/compil-time exception) - ошибки, которые можно обработать, к этому типу относятся все потомки класса
Exception, но неRuntimeException.
Например, при создании нового файлаnew File("C:\\text.txt").createNewFile();, компилятор будет настаивать на обработке исключенияIOException. - неконтролируемые (unchecked/runtime exception) - к ним относятся класс
Errorи исключения времени выполнения -RuntimeException(потомок классаException).
Например, при делении на 0 появится исключениеArithmeticException, но компилятор не может заранее знать, вызовет такой код исключение или нет, поэтому такие исключения и называются неконтролируемыми. Такие исключение надо не обрабатывать, а пытаться избавляться от такого рода ошибок.
Обработка этих самых исключений в программе основана на следующих ключевых словах:
-
try- отметка блока кода, которые может привести к ошибке; -
catch- предназначен для перехвата и обработки исключения; -
finally- блок завершающего действия, выполняется почти всегда после блоковtryиcatch; -
throw- предназначен для генерации исключений; -
throws- пишется в сигнатуре метода и показывает, что данный метод потенциально может "выбросить" указанное исключение.
Свойства исключений:
- блоков
catchможет быть любое количество; - в блоке
catchнельзя обрабатывать потомка после предка (например,RuntimeExceptionпослеException); - если исключение перехвачено, будут выполнены операторы идущие после последних скобок
try/catch; - если исключение не перехвачено - в
catchне заходим; - если зашли в
catchи выбросили исключение - будет выброшено исключение и весь код после блокаcatchбудет проигнорирован, даже если ниже есть еще один блокcatch, который мог бы обработать наше исключение, т.к.catchимеет отношения исключительно кtry/catchсекции, но не к другим блокамcatch; - с помощью
throw newможно выбросить какое-либо исключение в определенном месте программы, ноthrowиnew- это две независимые операции, мы можем создать объект и "выбросить его":
void method() {
try {
throw new IOException();
} catch (IOException e) {
throw e; // требует обработки (возможна обработка в другом методе)
}
}- блок
finallyможно использовать безcatch, но обязательно в связке ctry; - блок
finallyНЕ вызывается если мы принудительно остановили или завершили JVM (System.exit(0)илиRuntime.getRuntime().halt(0)); - блок
finallyможет "перебить"throw/returnпри помощи другогоthrow/return:
public static void main(String[] args) throws IOException {
System.out.println(method()); // 1
}
public static int method() {
try {
return 0;
} finally {
return 1;
}
}- В Java 7 появилась новая конструкция, с помощью которой можно перехватывать несколько исключений в одном блоке
catch:
try {
// some logic
} catch (CustomException | IOException e) {
System.out.println("catch block");
}- В Java 7 помимо обычной конструкции
try-catch-finally, в Java 7 можно использовать конструкциюtry-with-resources. Новая конструкция позволяет использовать блокtryне заботясь о закрытии ресурсов, используемых в данном сегменте кода. Ресурсы объявляются в скобках сразу после try, а компилятор уже сам неявно создаёт секциюfinallyв которой и происходит закрытие без участия разработчика.
try (Scanner scanner = new Scanner(new File("test.txt"))) {
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
}При попытки закрыть ресурс в блоке try вручную - scanner.close();, компилятор покажет предупреждение Redundant close();
Блоки catch и явный finally выполняются уже после того, как закрываются ресурсы в неявном finally;
Под ресурсами подразумеваются сущности, реализующие интерфейс java.lang.Autocloseable.
Так же можно создавать собственные исключения. Для этого нужно наследоваться от класса Exception и переопределить необходимые методы класса Throwable.
Создадим собственный класс:
class CustomException extends Exception {
public CustomException() {}
public CustomException(String message) { super(message); }
}Применим созданное исключение:
try {
throw new CustomException("my exception");
} catch (CustomException e) {
System.out.println(e.getMessage()); // my exception
}Java Collections Framework - иерархия интерфейсов и их реализаций, которые используются для сохранения и обаботки данных.
На вершине иерархии в Java Collections Framework располагаются 2 интерфейса: Collection и Map.
Collection - содержит простые последовательные наборы элементов. Этот интерфейс расширяет интерфейсы List, Set и Queue.
Map - содержит наборы пар "ключ-значение" (словари).
Интерфейс представляет собой неупорядоченную коллекцию. Элементы такой коллекции пронумерованы, начиная с нуля, к ним можно обратиться по индексу. Так же допустимо хранение дубликатов, результатом поиска по таким значениям будет первый найденный результат.
Реализации интерфейса List:
-
ArrayList - реализован в виде обычного массива.
ArrayListв сравнении с обычными массивами теряют в производительности из за возможности автоматического увеличения и сопутствующих проверок. - LinkedList - реализован в виде двунаправленного связанного списка (каждый элемент имеет ссылку на предыдущий и следующий).
- Vector - динамический массив, все операции синхронизированы. Удваивает свой размер, когда заканчивается память. Не рекомендуется использовать, если не требуется достижения потокобезопасности.
-
Stack - данная коллекцию является расширением
Vector, работает про принципу LIFO.
Интерфейс представляет собой коллекцию, которая не может содержать дублируемые значения.
Реализации интерфейса Set:
-
HashSet - базируется на
HashMap. Внутри использует объектHashMapдля хранения данных. В качестве ключа используется добавляемый элемент, а в качестве значения — объект-пустышка (new Object()). Данная реализация не является упорядоченной. -
LinkedHashSet - отличается от HashSet только тем, что в основе лежит
LinkedHashMapвместоHashSet. Благодаря этому отличию порядок элементов при обходе коллекции является идентичным порядку добавления элементов. -
TreeSet - базируется на
HashMap.
Этот интерфейс описывает коллекции с предопределённым способом вставки и извлечения элементов — очереди FIFO (first-in-first-out). Помимо методов, определённых в интерфейсе Collection, определяет дополнительные методы для извлечения и добавления элементов в очередь.
Реализации интерфейса Queue:
-
PriorityQueue - хранит элементы либо в естественном порядке (natural order) либо в соответсвии с
Comparator, переданым в конструктор. Данная коллекция не поддерживает null в качестве элементов.
Map<K, V> - этот интерфейс представляет собой структуру, где каждый элемент представляет собой пару "ключ-значение". При этом все ключи уникальны в рамках объекта Map. Если в Map положить значение с одинаковым ключом, старое значение будет перезаписано. Интерфейс Map НЕ расширяет интерфейс Collections.
Реализации интерфейса Map:
-
HashMap - основана на хеш-таблицах.
HashMapне синхронизирована, может содержать значенияnullдля ключей и значений. Данная реализация не является упорядоченной. - LinkedHashMap - это упорядоченная реализация хэш-таблицы, порядок итерирования равен порядку добавления элементов. Данная особенности достигается благодаря двунаправленным связям между элементами (аналогично LinkedList).
- TreeMap - основана на красно-чёрных деревьях. Как и LinkedHashMap является упорядоченной.
-
Hashtable - реализация структуры хеш-таблица. Она не позволяет использовать
nullв качестве ключа или значения.Hashtableявляется синхронизированной, что ведет к проблеам производительности. Рекомендуется использовать другие реализацииMap.
Источники:
Java Collections Framework: почти все и сразу
Справочник по Java Collections Framework
Коллекции в Java
Попробуем сравнить два объекта с помощью оператора ==:
Car car1 = new Car();
car1.name = "Mazda";
Car car2 = new Car();
car2.name = "Mazda";
System.out.println(car1 == car2); // falseРезультат, как и ожидалось - false, т.к. оператор == сравнивает ссылки на объект (адрес объекта в памяти), а не их содержимое. И в нашем примере экземпляры car1 и car2 как раз ссылаются на два разных объекта в памяти.
Если нам надо произвести сравнение именно по значению, в Java представлен специальный метод equals(), который определен в классе Object.
Но если мы не переопределим его в нашем классе, результат будет аналогичен примеру выше:
System.out.println(car1.equals(car2)); // falseДело в том, что сейчас мы используем его реализацию из класса Object и внутри метода лежит то же самое сравнение ссылок с помощью ==:
public boolean equals(Object obj) {
return (this == obj); // car1 == car2
}Что бы выводить правильный результат, с помощью Intellij Idea переопределим метод equals() в классе Car:
class Car {
public String name;
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null || getClass() != obj.getClass())
return false;
Car car = (Car) obj;
return Objects.equals(name, car.name);
}
}Теперь результат выполнения будет правильным:
System.out.println(car1.equals(car2)); // trueРассмотрим следующий пример сравнения с помощью оператора ==:
String text1 = "Строка для проверки";
String text2 = new String("Строка для проверки");
String text3 = "Строка для проверки";
System.out.println(text1 == text2); // false
System.out.println(text1 == text3); // trueТеперь разберем полученный результат
Оператор == сравнивает адреса в памяти и это работает всегда, а это значит, если text1 == text3 возвращает true, то у этих двух строк одинаковый адрес в памяти - и это действительно так. Такой результат достигается с помощью пула строк.
Пул строк (Spring pool) - область в памяти для хранения всех строковых значений, которые создаются в программе. Пул создан с целью экономии памяти, в него помещается созданная строка и в дальнейшем вновь созданные строки ссылаются на одну и ту же область памяти (с условием, что они имеют одинаковое содержимое), что избавляет от необходимости каждый раз выделять дополнительную память.
Каждый раз, когда создается String field = "some text", Java проверяет, есть ли строка с таким текстом в пуле, если есть - новая строка создаваться не будет, и такая строка будет указывать на уже существующую область в памяти.
Теперь рассмотрим первый пример, когда результат false.
Как видно, строка text2 создается с помощью оператора new, что предполагает выделение для нее новой области в памяти. И такая строка не попадает в String pool, а становится отдельным объектом (даже если ее текст совпадает с содержимым String pool).
Рассмотрим пример сравнения с помощью метода equals():
String country1 = "France";
String country2 = new String("France");
System.out.println(country1.equals(country2)); // trueКак было написано выше, для правильной работы метода equals() необходимо переопределить этот метод в своем классе, но в классе String метод equals() уже переопределен. Он сравнивает именно последовательность символов в строках. И если текст в строках одинаковый, неважно, как они были созданы и где хранятся: в пуле строк, или в отдельной области памяти - результатом сравнения будет true.
А помощью метода equalsIgnoreCase() можно сравнивать последовательность символов без учета регистра:
String country1 = "Russia";
String country2 = new String("RUSSIA");
System.out.println(country1.equals(country2)); // false
System.out.println(country1.equalsIgnoreCase(country2)); // trueСравнение с помощью метода String.intern():
String car1 = "BMW";
String car2 = new String("BMW");
System.out.println(car1 == car2); // false
System.out.println(car1 == car2.intern()); // trueМетод intern() напрямую работает со String Pool. Если мы вызываем метод intern() у какой-либо строки, он проверяет, есть ли строка с таким текстом в пуле строк и если есть - возвращает значение этой строки из пула, если же нет - помещает строку с этим текстом в пул строк и значение.
Источники:
JavaRash: Equals и сравнение строк
Хабр: Все о String.intern()
StackOverflow: Что такое interning и как им пользоваться
Хэш-код - это 10-значное число, которое в Java представлено как примитив int, т.е. оно имеет свой предел.
Хэширование -это процесс преобразования объекта в целочисленную форму, выполняется с помощью метода hashCode().
Переопределение метода equals() это еще не все, существует правило - Вы должны переопределять метод hashCode() в каждом классе, где переопределен метод equals. Невыполнение этого условия приведет к нарушению соглашений для метода Object.hashCode(), что не позволит вашему классу работать в сочетании с любыми коллекциями, построенными на использовании хэш-таблиц, таких как - HashMap, HashSet и HashTable.
- Если во время работы приложения несколько раз обратиться к одному и тому же объекту, метод hashCode должен постоянно возвращать одно и то же целое число, показывая тем самым, что информация при сравнении этого объекта с другим (метод equals), не поменялась;
- если два хэш-кода НЕ равны, объекты НЕ равны;
- если два объекта равны (equals), то их хэш-коды равны (но не наоборот);
- эквивалентность (equals) и хеш-код тесно связанны между собой, поскольку хеш-код вычисляется на основании содержимого объекта (значения полей) и если у двух объектов одного и того же класса содержимое одинаковое, то и хеш-коды должны быть одинаковые. Т.е.
object1.equals(object2) && (object1.hashCode() == object2.hashCode())- должно быть true; - ситуация, когда у разных объектов одинаковые хеш-коды называется — коллизией. Вероятность возникновения коллизии зависит от используемого алгоритма генерации хеш-кода.
- эквивалентность (equals) и хеш-код тесно связанны между собой, поскольку хеш-код вычисляется на основании содержимого объекта (значения полей) и если у двух объектов одного и того же класса содержимое одинаковое, то и хеш-коды должны быть одинаковые. Т.е.
Два различных экземпляра с точки зрения метода equals могут быть логически равны, однако для метода hashCode это лишь два объекта, не имеющих ничего общего. Поэтому метод hashCode, если его не переопределить, скорее всего возратит для этих объектов два случайных числа, а не одинаковых, как того требует соглашение.
Метод hashCode() используется для получения хэш-кода объекта. Метод hashCode() класса Object возвращает ссылку памяти объекта в целочисленной форме (идентификационный хеш (identity hash code)).
В классе HashMap метод equals() используется для проверки равенства ключей. В случае, если ключи равны, метод equals() возвращает true, иначе false.
Структура хэш-таблицы (HashCode Buckets):
| KEY=HashCode_1 | KEY=HashCode_2 | KEY=HashCode_n |
|---|---|---|
| value_1 | value_1 | value_1 |
| value_2 | value_2 | value_2 |
| value_n | value_n | value_n |
Каждому хэш-коду соответствует один столбец.
У объекта вычисляется хэш-код и его значение кладется в соответствующую ячейку.
Поиск по хэш-таблице происходит следующим образом:
- У объекта вычисляется хэш-код и находится соответствующуая ячейка в таблице
- Метод
equals()сравнивает каждое значение из столбца с искомым значением
В методе hashCode() для расчета значения должны использоваться те же поля, что и в методе equals(), или меньше, но ни как не поля, которые отсутствуют в методе equals().
Источники:
Java. Эффективное программирование / Блох Дж.
https://stackoverflow.com/questions/2265503/why-do-i-need-to-override-the-equals-and-hashcode-methods-in-java
Разбираемся с hashCode() и equals()
https://javarush.ru/groups/posts/2179-metodih-equals--hashcode-praktika-ispoljhzovanija
SmartMe
Конспект
Comparable и Comparator - интерфейсы, которые предназначены для сортировки коллекций.
Например, надо отсортировать коллекцию, состоящую из имен сотрудников:
List<String> employeesName = new ArrayList<String>() {{
add("John");
add("Daniel");
add("Kate");
}};
Collections.sort(employeesName);
System.out.println(employeesName); // [Daniel, John, Kate]Сортировка прошла успешна, тот же результат будет и с числами.
Но что если класс будет содержать несколько объектов , как Java поймет, по какому из них проводить сортировку? Например, класс Employees содержит 3 поля - имя, возраст и зарплата сотрудника:
List<Employees> employeesList = new ArrayList<Employees>() {{
add(new Employees("John", 28,9000));
add(new Employees("Daniel", 30, 7500));
add(new Employees("Kate", 24, 8000));
}};Мы сами должны указать Java метод сортировки, для этого воспользуемся специальным инструментом - интерфейсом Comparable.
Для того что бы объекты нашего класса Employees можно было сравнивать между собой, класс должен реализовать один единственный метод из этого интерфейса - compareTo():
public class Employees implements Comparable<Employees> {
private String name;
private int age;
private int salary;
public Employees() {}
public Employees(String name, int age, int salary) {
this.name = name;
this.age = age;
this.salary = salary;
}
@Override
public int compareTo(Employees employees) {
return (this.getSalary() - employees.getSalary());
}
// getters, setters, toString
}Интерфейс Comparable<Employees> типизированный и требует конкретного класса, с которым он будет связан, в данном случае это Employees. Можно убрать типизацию, тогда интерфейс по умолчанию реализует метод compareTo() с аргументом типа Object, что потребует кастинг до нужного класса:
@Override
public int compareTo(Object employees) {
return (this.getSalary() - ((Employees)employees).getSalary());
}Внутри метода compareTo() мы реализуем логику сравнения, в данном случае - будет сортировка по зарплате сотрудников.
Важно отметить, что метод compareTo возвращает значение int и результатом сравнения может быть 3 варианта:
- a < b, возвращается значение < 0
- a > b, значение > 0
- a == b, возвращается 0
Именно по такой логике мы и реализуем метод compareTo() - берется один объект (this), зарплата сотрудника и отнимается от зарплаты другого сотрудника (другого объекта), и в зависимости от результат - вернет <, > или =, и так с каждым объектом.
После того как мы реализовали интерфейс Comparable, попробуем произвести сортировку:
List<Employees> employeesList = new ArrayList<Employees>() {{
add(new Employees("John", 28,9000));
add(new Employees("Daniel", 30, 7500));
add(new Employees("Kate", 24, 8000));
}};
System.out.println("Before: " + employeesList);
Collections.sort(employeesList);
System.out.println("After: " + employeesList);
// Output:
// Before: [{John, 28, 9000}, {Daniel, 30, 7500}, {Kate, 24, 8000}]
// After: [{Daniel, 30, 7500}, {Kate, 24, 8000}, {John, 28, 9000}]Как видно из примера, сортировка сотрудников по зарплате успешно выполнена.
Реализованный с помощью интерфейса Comaparble метод сравнения называют "natural ordering" - естественной сортировкой. Потому как в методе compareTo() описывается наиболее распространенный способ сравнения, который будет использоваться для объектов этого класса в программе.
Natural Ordering в Java уже реализован по умолчанию, если вызвать метод sort() класса java.util.Collections для строк - будет произведена сортировка по алфавиту, а для числе - по возрастанию.
Кстати, в приведенных выше примерах мы сравнивали только числа, но если коллекцию необходимо отсортировать по строкам, необходимо вызвать метод String.compareTo(), например:
@Override
public int compareTo(Employees employees) {
return this.getName().compareTo(employees.getName());
}В классе String уже реализован метод compareTo(), который проводит лексикографическое сравнение (сортировка в алфавитном порядке).
Но бывают случаи, когда для какой-то конкретной задачи естественная сортировка нам не подходит или нам нужно реализовать специфическую сортировку, в этом случае может помочь интерфейс Comparator<>.
Этот интерфейс позволяет не менять уже установленную логику в методе compareTo(), а реализовать свою, создав отдельный класс, например:
public class EmployeesAgeComparator implements Comparator<Employees> {
@Override
public int compare(Employees employees1, Employees employees2) {
return employees1.getAge() - employees2.getAge();
}
}Интерфейс Comparator имеет один обязательный метод - compare(), который нужно реализовать. Принцип его работы схож с методом compareTo().
Теперь используем новый метод сортировки по возрасту:
List<Employees> employeesList = new ArrayList<Employees>() {{
add(new Employees("John", 28, 5000));
add(new Employees("July", 30, 7500));
add(new Employees("Steven", 24, 8000));
}};
System.out.println("Before: " + employeesList);
Collections.sort(employeesList, new EmployeesAgeComparator());
System.out.println("After: " + employeesList);
// Output:
// Before : [{John, 28, 9000}, {Daniel, 30, 7500}, {Kate, 24, 8000}]
// After: [{Kate, 24, 8000}, {John, 28, 9000}, {Daniel, 30, 7500}]Метод sort(), получив на качестве второго аргумента компаратор, не будет использовать естественную сортировку, вместо этого он применит алгоритм сортировки из переданного ему компаратора.
Можно так же передать анонимный класс:
Collections.sort(employeesList, new Comparator<Employees>() {
@Override
public int compare(Employees e1, Employees e2) {
return e1.getAge() - e2.getAge();
}
});Какая разница между Comparable и Comparator?
Оба эти интерфейса используются для реализации сортировки объектов.
Comparable используется для естественной сортировки, которая будет использоваться в большинстве случаев.
Comparator добавляет гибкости и позволяет создать свои собственные методы сортировки, при этом не меняя уже существующий код.
Java 8 добавила ряд изменений, которые повлияли на работу с сортировкой:
во-первых, добавился метод List.sort(comparator), который позволяет передавать компаратор "напрямую" коллекции, например:
// Java 1.2
EmployeesAgeComparator employeesAgeComparator = new EmployeesAgeComparator();
Collections.sort(employeesList, employeesAgeComparator);
// Java 8
employeesList.sort(employeesAgeComparator);во-вторых, добавился более короткий синтаксис с помощью лямбда-выражений - теперь не придется создавать анонимные классы:
employeesList.sort((Employees emp1, Employees emp2) -> {
return emp1.getAge() - emp2.getAge();
});Для однострочных методов можно опустить скобки {} и ключевое слово return. Компилятору так же известны типы параметров, поэтому их тоже можно опустить, результат:
employeesList.sort((emp1, emp2) -> emp1.getAge() - emp2.getAge());В-третьих - появилась статическая функция Comparator.comparing(), которая в качестве параметра принимает ключ сортировки (объект, по которому будет произведена сортировка) и возвращает объект Comparator<> того типа, который содержит ключ сортировки, т.е. в нашем случае Comparator<Employees>:
employeesList.sort(Comparator.comparing(employees -> employees.getAge()));В-четвертых - ссылки на метод. С помощью ключевого слово :: можно передать ссылку на метод:
employeesList.sort(Comparator.comparing(Employees::getAge));Результаты данных примеры аналогичны друг-другу и предыдущим.
Источники:
JavaRush: Comparator в Java
Habr: Новое в Java 8
Java позволяет создавать одни классы внутри других. Такие классы называются вложенными.
Вложенные классы (Nested) делятся на две основных категории:
- статические (Static nested classes);
- нестатические (Non-static nested) или как их еще называют - внутренние классы (Inner classes);
- локальные (Method-local inner class)
- анонимные (Anonymous inner class)
https://juja.com.ua/java/inner-and-nested-classes/#_Ref472190742
https://javarush.ru/groups/posts/2181-vlozhennihe-vnutrennie-klassih
https://stackoverflow.com/questions/70324/java-inner-class-and-static-nested-class