Вопросы на интервью - DmitryGontarenko/usefultricks GitHub Wiki
Оба эти интерфейса используются для реализации сортировки объектов.
Comparable используется для естественной сортировки, которая будет использоваться в большинстве случаев.
Comparator добавляет гибкости и позволяет создать свои собственные методы сортировки, при этом не меняя уже существующий код.
Использование Comparable:
public class Employees implements Comparable<Employees> {
private String name;
private int age;
private int salary;
@Override
public int compareTo(Employees employees) {
return (this.getSalary() - employees.getSalary());
}
}Использование Comparator:
// анонимный класс
Collections.sort(employeesList, new Comparator<Employees>() {
@Override
public int compare(Employees e1, Employees e2) {
return e1.getAge() - e2.getAge();
}
});
// использование в Java 8
employeesList.sort(Comparator.comparing(Employees::getAge));Существует три вида внедрения зависимостей: через конструктор, сеттер и поле.
Почему не желательно использовать внедрение через поле:
- Нарушение принципа единой ответственности. При использовании внедрения через конструктор, наличие слишком большого количества зависимостей означает, что у класса чрезмерно много зон ответственности - это может говорить о нарушении Single Responsibility. А при использовании внедрения через поле такую проблему сложнее заметить, что ведет к еще большему разрастанию зависимостей;
- Сокрытие зависимостей. Когда класс более не отвечает за получение зависимостей, он все равно должен явно взаимодействовать с ними. Таким образом становится четко понятно, что требует класс - опциональные это зависимости (через сеттер) или обязательные (конструктор);
-
Зависимость от DI-контейнера. При внедрении через поле не предоставляется прямой способ создания экземпляра класса со всеми необходимыми зависимостями. Это означает, во-первых, что при создании класса через оператор
newему может не хватить некоторых зависимостей и его использование приведет к NPE, а во-вторых, что такой класс не может быть использован вне DI-контейнера (тесты, другие модули) и нет способа кроме рефлексии предоставить ему необходимые зависимости; - Неизменность. В отличии от использование конструктора, внедрение через поле не может использоваться для присвоения зависимостей final-полям, что приводит к тому, что объекты становятся изменяемыми.
Конструкторы vs. сеттеры
Сеттеры стоит использовать для внедрения опциональных зависимостей. Класс должен функционировать, даже если они не были предоставлены.
Конструкторы подходят для внедрения обязательных зависимостей - тех, которые требуются для корректной работы объекта. Поля, инициализированные в конструкторе, могут быть final, что позволяет объекту защитить необходимые поля.
Источники: Habr. Внедрение зависимостей через поля — плохая практика
Если у одной родительской сущности N дочерних сущностей, значит будет N вызовов дочерней сущностей и 1 родительский.
Эти дополнительные SQL select-ы нужны для заполнения поля, ссылающегося на другие сущности.
Представим, что у нас есть таблица students, которая имеет связь М:1 с таблицей university.
Проблемный запрос на примере: select s from Students s
Если посмотрим в логи Hibernate, то увидим примерно следующее (пример упрощен):
Hibernate: select students id, name, university_id from students
Hibernate: select university id, name from university where university.id = ?
Hibernate: select university id, name from university where university.id = ?
Hibernate: select university id, name from university where university.id = ?
В результате видно, что помимо одного основного запроса, выполнилось еще 4 дополнительных, которые понадобились для заполнения поля (дочерней сущности).
Эту ситуацию можно исправить двумя способами:
С помощью добавления fetch join в запрос, например так:
select s from Students s join fetch s.university uПри использовании Spring Data добавить аннотацию @EntityGraph:
@Repository
public interface StudentsRepository extends JpaRepository<Students, Long> {
@Override
@EntityGraph(attributePaths = {"university"})
List<Students> findAll();
}Аннотация @Component используется для определения компонентов Spring, а @Service для какой-либо бизнес логики. В плане функциональности между ними нет разницы.
Для @Repository существует одна особенность - все бины, помеченные этой аннотацией, перехватывают специфичные исключения и повторно генерируют их как одно из непроверяемых исключений доступа к данным. Именно поэтому ее есть смысл использовать только в DAO-классах.
Аннотацию @Controller нельзя заменить на другую, например @Service или @Repository. Потому что аннотацию @RequestMapping мы можем использовать только в классах, помеченных @Controller.
Метод equals() сравнивает состояние объекта.
По умолчанию используется его реализация из класса Object, которая сравнивает переданные объекты по ссылке ==. Но если мы хотим сравнивать объекты именно по значению, метод equals() нужно переопределять (Подробнее с примерами ниже).
Метод hashCode() представляет объект в целочисленной форме.
Реализация этого метода в классе Object по умолчанию возвращает значение идентификационного хеша (формирование которого зависит от версии JDK), поэтому его надо преопределить.
Следует учитывать, что множество хэш-кодов ограничено типом int, а множества объектов - нет, из за этого хэш-коды разных объектов могут совпадать (коллизия).
Эти методы обязательно перепределять вместе.
Если переопределить equals(), но не переопределять hashCode() - это не позволит классу работать в сочетании с любыми коллекциями, построенными на использовании хэш-таблиц - HashMap, HashSet, Hashtable. Т.к. хэш-код объекта, который записывается в хэш-таблицу, может отличаться от искомого объекта, в результате чего вернется null (даже если помещаемый и искомый объект логически равны).
Пример:
Map<Employee, String> employeeMap = new HashMap<>();
employeeMap.put(new Employee("John", 23), "employee1");
System.out.println(employeeMap.get(new Employee("John", 23))); // result: nullЕсли переопределить hashCode(), но не переопределять equals() - это аналогичну примеру выше не позволит классу работать в сочетании с любыми коллекциями, построенными на использовании хэш-таблиц - HashMap, HashSet, Hashtable. Т.к. для сравнения равенства ключей в хэш-таблице используется метод equals().
Коллекия - это структура данных, которая служит хранилищем объектов и обеспечивает доступ к ним.
Коллекции в Java реализует набор классов и интерфейсов под названием Java Collection Framework.
На вершине иерархии в Java Collection Framework располагаются 2 интерфейса: Collection и Map. Эти интерфейсы разделяют все коллекции, входящие во фреймворк на две части по типу хранения данных:
Collection - это последовательность элементов. Этот интерфейс расширяет интерфейсы List, Set и Queue.
Map - это совокупность пар «ключ-значение» (словарь).
Интерфейс Collection расширяет интерфейсы:
- List - упорядоченный список объектов, в котором допустимы дублирующие значения. Элементы списка могут вставляться или извлекаться по индексу. Реализации:
- ArrayList - реализован в виде обычного массива. ArrayList в сравнении с обычными массивом теряет в производительности из за возможности автоматического увеличения (на половину) и сопутствующих проверок.
- LinkedList - реализован в виде двунаправленного связанного списка (каждый элемент имеет ссылку на предыдущий и следующий).
- Vector - динамический массив, все операции синхронизированы (потоко-безопасен). Удваивает свой размер, когда заканчивается память.
- Stack - является подклассом Vector и работает по принципу LIFO (последним пришел-первым вышел), также является потоко-безопасным.
- Set - не упорядоченная коллекция, которая не может содержать дублированные значения. Реализации:
- HashSet - внутри использует объект HashMap для хранения данных. В качестве ключа используется добавляемый элемент, а в качестве значения — объект-пустышка (new Object()).
- LinkedHashSet - расширяет класс HashSet и поддерживает список элементов в том порядке, в котором они добавлялись.
- TreeSet - при вставке элементов сортирует их в порядке возрастания (natural order). TreeSet использует самобалансируещееся двоичное дерево (красно-черное дерево). Но при создании TreeSet с конструктором, мы можем указать определенный порядок с помощью Comparable или Comparator:
Set<String> treeSet = new TreeSet<>(Comparator.comparing(String::length));
- Queue - очередь представляет собой упорядоченный список элементов. Вставка рабоатет как FIFO (первым пришел-первым ушел), т.е. элементы вставляются в конец очереди, а извлкаются только из начала очереди. Реализации:
- PriorityQueue - хранит элементы либо в естественном порядке (natural order) либо в соответсвии с Comparator, переданым в конструктор, не поддерживает null в качестве элементов.
Интерфейс Map<K, V> представляет собой структуру, где каждый элемент представляет собой пару "ключ-значение". При этом все ключи уникальны в рамках объекта Map. Если в Map положить значение с одинаковым ключом, старое значение будет перезаписано.
Реализации интерфейса Map:
- HashMap - основана на хеш-таблицах. HashMap не синхронизирована, может содержать значения null для ключей и значений. Данная реализация не является упорядоченной.
- LinkedHashMap - это связанный двунаправленный список, который хранит ключи в порядке вставки.
- TreeMap - основана на красно-чёрных деревьях и хранит ключи в отсортированными по возрастанию (natural order), либо в соответствии с Comparator, переданным в конструктор.
- Hashtable - аналогичен HashMap, но его методы являются
synchronized, поэтому его работа не такая быстрая. Не позволяет использовать null в качестве ключа или значения.
Bucket - это элемент массива HashMap, он используется для хранения узлов (Node).
В случае коллизии при записи, один Bucket может иметь несколько Node, в этом случае для связи узлов используется связанный список.
Node - это вложенный класс HashMap, который имеет следующие поля:
| Поле | Описание |
|---|---|
| int hash | хеш-код текущего элемента |
| K key | ключ текущего элемента |
| V value | значение текущего элемента |
| Node<K, V> next | ссылка на следующий узел в пределах одной корзины |
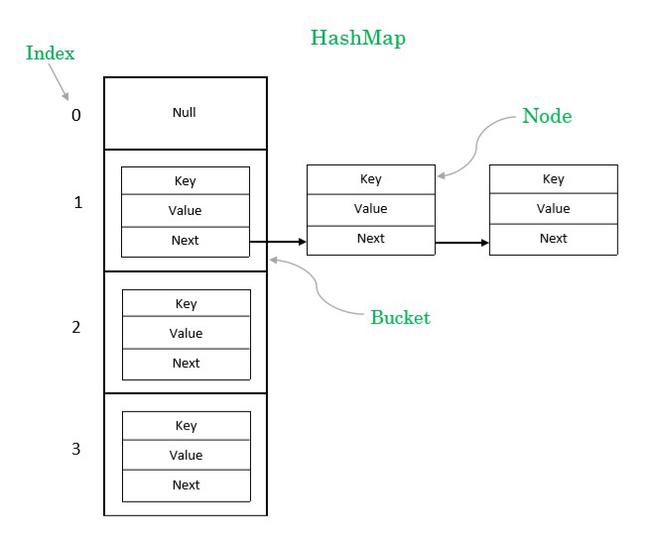
Пример вставки значения в HashMap:
- Вычисляем хэш-значение ключа;
- При первом добавлении элемента создается хэш-таблица размером 16 (если создана, сразу переходим к п.3);
- Вычисляем индекс бакета (массива), в который будет добавлен наш элемент;
- Создается объект Node;
- Производится проверка, если количество элементов превышает размер таблицы - она увеличивается вдвое.
Случается так, что разные ключи попадают в один и тот же бакет (даже с разными хэшами), это называет Коллизией. Но при этом их все равно надо сохранять.
Рассмотрим ситуацию с добавлем значения в HashMap, но с коллизией:
- Вычисляем хэш-значение ключа;
- Проверяем, создана ли таблица;
- Вычисляем индекс бакета (в данном случае происходит коллизия - по индексу уже есть элемент);
- Сравниваем добавляемый элемент с существующим (если хэши и ключи равны, значение текущего элемента будет перезаписано новым);
- Если элементы не равны, то в пределах одного бакета проверяем наличие указателя на следующий элемент и если он равен null, добавляем новый элемент Node в конец списка.
Если элементов в одном Бакете будет равно 8, то размер хэш-таблицы увеличится с перераспределением элементов. Но если при этом общее количество бакетов в таблице больше 64, то этот конкретный Бакет будет преобразован в Красно-черное дерево.
Первый элемент списка записывается как корень, остальные элементы распределяются налево и направо в зависимости от значения хэша.
В дереве узел представляется типом TreeNode, который расширяет тип Node.
Если при удалении количество узлов вернется к значению 6, тогда дерево перестроится в связный список.
При удалении элементов в HashMap размер массива (таблицы) не уменьшается.
Источники:
JavaRush. Подробный разбор класса HashMap
Habr. Внутренняя работа HashMap в Java
Habr. Структуры данных в картинках. HashMap
Habr. Как работает hashCode() по умолчанию?
Объектно-ориентированное программирование (ООП) - методология программирования, основанная на представлении программы в виде совокупности объектов.
Основные понятия:
Класс - это сложный тип данных, имеющий состояние (поля) и поведение (методы), а также правила для взаимодействия с данной сущностью (контракт).
Объект - это сущность в памяти, появляющаяся при создании экземпляра класса.
Основные принципы:
Инкапсуляция - сокрытие реализации.
Это свойство системы, позволяющее скрыть детали реализации от пользователя, открыв только то, что необходимо при последующем использовании.
Наследование - это передача состояния или поведения от одного класса к другому.
Наследование позволяет описать новый класс на основе уже существующего, при этом свойства и функциональность базового класса заимствуются новым классом (подклассом).
Полиморфизм - это возможность объектов с одинаковым назначением иметь различную реализацию.
Абстракция - это способ выделить набор общих характеристик объекта, исключая из рассмотрения незначимые.
public – публичный класс или член класса.
private – закрытый класс или член класса, доступен только для своего класса.
protected – такой член класса доступен из любого места в текущем класса, пакете или производном классе.
default – модификатор по умолчанию (отсутствие модификатора), такие поля или методы видны всем классам в текущем пакете.
В Java существует 8 примитивных типов, которые делят на 3 группы:
- Целые числа – byte, short, char, int, long;
- Числа с плавающей запятой – float, double;
- Логический – boolean.
Ссылочные типы - это все остальные типы: классы, перечисления (Enum) и интерфейсы, а так же массивы.
Обертка (wrapper) - это специальный класс, который хранит внутри себя значение примитива.
Поскольку это именно класс, он может создавать свои экземпляры и иметь соответствующие методы.
Так же при использовании коллекций, просто необходимо значения примитивных типов каким-то образом представлять в виде объектов. Потому как обобщенные типы (Generics) должны быть ссылочными типами.
Зачем тогда нужны примитивы?
Для более быстрой работы. Ведь переменные примитивного типа напрямую содержат свои значения. Примитивы хранятся в стеке, куда намного быстрее получить доступ, чем к объектам (wrapper`ам), которые хранятся в куче.
Автоупаковка (autoboxing) - это преобразование примитива в соответствующий ему класс-обертку.
Это происходит при присвоении примитива соответствующему ему классу-обертке или при передачи примитива в параметр метода, ожидающего соответствующий ему класс-обертку.
Распаковка (unboxing) - это преобразование класса-обертки в соответствующий ему примитивный тип.
Integer pool - это набор инициализированных и готовых к использовании объектов, который кэширует объекты со значением от -128 до 127 и при повторном использовании обращается к ним.
Пример:
Integer obj1 = 100;
Integer obj2 = 100;
System.out.println(obj1 == obj2); // true. Объекты берутся из integer pool
Integer obj3 = new Integer(120);
Integer obj4 = new Integer(120);
System.out.println(obj3 == obj4); // false. Объекты явно созданы, следовательно имеют разные ссылки
Integer obj5 = 200;
Integer obj6 = 200;
System.out.println(obj5 == obj6); // false. Значение 200 уже не входит в диапазон integer poolUpcasting (расширение типов) - если тип становится «старше», то он расширяется. В этом случае нет риска потерять данные.
Примитивы расширяются в таком порядке: byte -> short -> char -> int -> long -> float -> double.
Для объектов «расширением типов» считается преобразование подкласса в суперкласс.
Downcasting (сужение) - преобразование в обратную сторону (был long, а стал int). Такая операция потребует от нас явного преобразования (явного указания типа), потому что в этом случае есть риск потерять данные и Java не будет проводить такое преобразование автоматически.
Примитивы сужаются в таком порядке: double -> float -> long -> int -> char -> short -> byte.
Для объекта сужением типов считается преобразование суперкласса в подкласс.
Блок инициализации – это один из элементов класса. Все действия в БИ происходят в момент инициализации.
- Если БИ несколько, они будут выполнятся в порядке следования.
- БИ могут быть статическими, тогда они выполняются при первом обращении к классу.
Подядок вызова БИ и конструкторов при наследовании:
Parent static init block → Child static init block
Parent init block → Parent default constructor
Child init block → Child default constructor
JDK - это виртуальная машина, которая исполняет байт-код Java, предварительно созданный из исходного кода Java-программы компилятором Java (javac). JVM предоставляет функции управления памятью, сборки мусора и т.д.
JVM может также использоваться для выполнения программ, написанных на других языках программирования.
JRE - система для запуска скомпилированной Java-программы. Состоит ТОЛЬКО из JVM и библиотек Java классов.
JDK - это комплект Java разработчика, включающий в себя JRE, компилятор Java (javac), стандартные библиотеки классов Java и различные утилиты.
JAR (Java ARchive) - это ZIP архив, в котором содержится часть Java программы (файлы и классы).
Override (переопределение) - это переопределение поведения метода в классах-потомках.
Overload (перегрузка) - это создание методов с одинаковыми именами, но разным количеством параметров и/или их типом.
String pool - это область в памяти (часть кучи), хранящая все созданные, уникальные строковые значения в программе. В дальнейшем вновь созданные строки будут ссылаться на одну и ту же область памяти (с условием, что они имеют одинаковое содержимое).
Метод intern() позволяет по содержимому найти строку в пуле, например:
String car1 = "BMW";
String car2 = new String("BMW");
System.out.println(car1 == car2); // false
System.out.println(car1 == car2.intern()); // trueString - неизменяемый набор символов (константа).
StringBuilder - изменяемый набор символов для построения строк. Не гарантирует синхронизацию.
StringBuffer - поточно-ориентированный, изменяем набор символов для построения строк. Безопасен при использовании в нескольких потоках.
Конструктор - это специальный метод, который вызывается при создании объекта.
Цель конструктора - инициализировать поля объекта.
Существуют три типа конструкторов:
- конструктор по умолчанию (default constructor);
- конструктор без аргументов (no-args constructor);
- конструктор с параметрами (parameterized constructor).
- Использовать ключево слово
new
Dog dog = new Dog("sombra");- Использовать
Class.forName()
Dog dog = (Dog) Class.forName("com.home.temp.Dog").getConstructor(String.class).newInstance("spike");- Использовать
clone()
Dog clone = (Dog) dog.clone();Для клонирования необходимо реализовать интерфейс Cloneable и метод clone().
Для примитивов передается копия текущего значения.
Для объектов передается копия ссылки и поскольку работа ведется с копией, на исходный объект это никак не влияет.
Таким образом в Java передача происходит только по значению.
Сериализация - это механизм сохранения объекта в виде последовательности байтов, а десериализация - это обратный процесс.
Классы, нуждающиеся в сериализации, должны реализовать маркерный интерфейс Serializable.
Рефлексия (reflection) - это механизм языка, который позволяет изменить или проверить внутреннее состояние объектов во время выполнения. При использовании рефлексии можно получить доступ ко всем возможным членам класса, независимо от модификатора доступа. Доступ через рефлексию можно ограничить путем настройки политики безопасности JVM.
Транзакция - это операция с БД, которая может быть совершена только либо полностью и успешно, либо не выполнена вообще.
Транзакция должна удовлетворять свойствам ACID (Atomacity, Consistency, Isolation, Durability):
- атомарность - транзакция должна быть выполнена целиком или не выполнена вовсе;
- согласованность - транзакция может фиксировать только допустимый (например для БД) результат;
- изолированность - транзакции должны выполняться изолирована друг от друга. Параллельные транзакции не должны оказывать влияния на результат;
- долговечность - если транзакция завершена успешно, изменённые данные не могут быть потеряны даже из за каких-либо программных или аппаратных сбоях.
Транзакции, охватывающие множество систем, называются распределенными транзакциями. Такие транзакции распределяются между множеством микросервисов, которые вызываются в некоторый последовательности для завершения всей транзакции.
В связи с этим возникают проблемы поддержки атомарности транзакции - в случае ошибки необходимо откатывать изменения для всех задействованных сервисов.
Возможны несколько вариантов решения проблемы:
-
Двухфазная фиксация. Состоит из двух этапов: фазу подготовки и фазу фиксации (коммит). Для организакции такого жизненного цикла транзакции должен быть реализован координатор транзакций.
На первом этапе все микросервисы, задействованный в транзакции, уведомляют координатора что готовы произвести транзакцию (и блокируют объекты для изменения). Затем либо происходит коммит, либо координатор дает коману сервисам выполнить откат. -
SAGA/ Согласованность в конечном счете и компенсация. Каждый сервис публикует события каждый раз, когда обновляет свои данные. Другие сервисы подписываются на события и при их получении обновляют своим данные.
В таком подходе транзакции между микросервисами выполняется асинхрнонно. Обмен информацией происходит через очередь сообщений, а за организацию (хореографию) обмена сообщений отвечает другая система - координатор. В случае ошибок на каком-либо этапе, координатор слушает это событие и запускает компинсирующую транзакцию, которая откатит изменения.
Источники: Обработка распределенных транзакций в микросервисной архитектуре
Если суперкласс реализовал интерфейс Serializable, это означает, что подкласс также является сериализуемым (поскольку подкласс всегда наследует все функции своего родительского класса).
Чтобы избежать сериализации в подклассе, мы можем определить в нем метод writeObject() и выбросить NotSerializableException():
// define how Serialization process will write objects.
private void writeObject(ObjectOutputStream os) throws NotSerializableException {
throw new NotSerializableException("This class cannot be Serialized");
}Статический импорт позволяет получить прямой доступ к статическому члену класса без необходимости указывать его имя.
import static com.home.temp.ErrorList.PASSWORD_EXPIRED;
import static java.lang.Math.*;
public class TempApp {
public static void main(String[] args) {
System.out.println(PASSWORD_EXPIRED);
System.out.println(abs(2));
}
}Оператор assert позволяет проверить любые логические условия, а в случае false выкинуть исключение AssertionError.
boolean b = 5 > 10;
assert b;
assert b : "It`s error";По умолчанию в JVM отключена такая проверка, разрешить ее можно при помощи установки ключа -ea при запуске программы.
transient используется, что бы исключить поле из сериализации (точнее, его значение).
После десериализации поле будет иметь значение по умолчанию (в соответствии с типом).
private transient String name;Результат десериализации:
Object{name=null}volatile объявляет, что значение поля должно быть прочитано и записано в основную память, минуя кэш ЦП.
Это нужно, что бы обеспечить когерентность (согласованность) кэшей и что бы у разных потоков была одна и та же версия определенного поля, которое они оба используют. Т.к. если потоки запущены на двух разных ядрах, кэши ядер тоже будут разные.
Поле с именем serialVersionUID используется, что бы сохранить состояние класса при сериализации. Это помогает определить совместимость классов при десериализации.
Таким образом, при изменении структуры класса (например добавления новых полей) поле serialVersionUID нужно перегенерировать, что бы избежать ошибок при десериализации уже устаревшего объекта.
private static final long serialVersionUID = 2829837622107417665L;Что бы иметь возможность генерировать это поле автоматически, можно установить проверку на его отсутствие. Для этого в Intellij IDEA - Settings -> Inspections -> включить Serializable class without 'serialVersionUID'.
Ключевое слово native используется для определение методов, реализация которых была написана на отличном от Java языке программирования. Такой метод не имеет тела.
Например:
protected native Object clone() throws CloneNotSupportedException;Возможность вызова функций других языков реализована с помощью стандарного механизма JVM - JNI (Java Native Interface).
С момента создания строка остаётся в пуле, до тех пор, пока не будет удалена сборщиком мусора. Поэтому, даже после окончания использования пароля, он некоторое время продолжает оставаться доступным в памяти и способа избежать этого не существует. Это представляет определённый риск для безопасности, поскольку кто-либо, имеющий доступ к памяти сможет найти пароль в виде текста. В случае использования массива символов для хранения пароля имеется возможность очистить его сразу по окончанию работы с паролем (например перезаписать другими значениями), позволяя избежать риска безопасности, свойственного строке.
Идемпотентность - это действие, многократное повторение которого эквивалентно однократному. Идемпотентность решает проблему дубликации данных при работе с БД.
Свойства идемпотентности у HTTP методы:
PUT - идемпотентный.
DELETE - идемпотентный. Можно многократно использовать удаление, но результат всегда будет таким же, как после первого выполнения операции.
GET - идемпотентный и безопасный метод. Он просто получает данные и его результат всегда будет одинаковым.
POST - не относится к идемпотентным методам.
GET, HEAD, OPTIONS и TRACE - безопасные, что также делает их идемпотентными. Они предназначены только для получения информации и не должны изменять состояние сервера, даже при многократном вызове.
Методы close() и registerShutdownHook() используются для закрытия контекста бинов при использовании спринга.
close() - закрывает контекст приложения, уничтожив все компоненты;
registerShutdownHook() - закрывает контекст приложений непосредственно перед остановкой работы JVM.
Пример использования:
AbstractApplicationContext context = new ClassPathXmlApplicationContext("spring-context.xml");
MessageDto message = (MessageDto) context.getBean("messageDto");
System.out.println(message.getMessage());
// context.close();
context.registerShutdownHook();Правило наименьшего удивления или principle of least astonishment гласит, что результат выполнения операции должен быть очевидным и предсказуемым по названию операции.
Разница между Наследованием и Композицией?
Композиция - это метод проектирования, при котором ваш класс может иметь экземпляр другого класса в качестве поля вашего класса. Наследование - это механизм, с помощью которого один объект может получить свойства и поведение родительского объекта путем расширения класса.
Пример Наследования:
class Fruit {
//...
}
class Apple extends Fruit {
//...
}Пример Композиции:
class Fruit {
//...
}
class Apple {
private Fruit fruit = new Fruit();
//...
}Что значит модификатор final при объявлении класса?
Класс с модификатором final не может иметь наследников и все его методы косвенным образом приобретают свойство final.
Какая разница между перегруженными и переопределенными методами?
Overloading (Перегрузка метода) – это создание методов с одинаковыми именами, но разным количеством параметров и/или их типом.
Override (Переопределение метода) – это возможность подкласса изменять поведение уже существующего метод из суперкласса. Метод переопределения имеет то же возвращаемое значение и сигнатуру, что и у метода, который он переопределяет.
Подробнее здесь
Правильный способ конкатенации строк. Чем различаются классы StringBuilder и StringBuffer?
1
2
3 ответы
Отличия метода equals и ==. В каком случае оператор == будет действовать аналогично equals?
Java Collection
https://github.com/DmitryGontarenko/usefultricks/wiki/Java-SE#collections
Для чего необходим Dependency Injection?
Spring помещает объекты (бины) в Spring Application Context, а так же берет на себя управление их жизненным циклом. При этом он сам внедряет все необходимые зависимости, нам остается только описать эту связь (Dependency Injection);
Какие есть scope бинов в Spring, в чем отличие, какие используются по умолчанию?
https://github.com/DmitryGontarenko/usefultricks/wiki/Spring-Framework#bean-scope
Паттерны проектирования, какие существуют, на какие группы разделены?
Паттерны проектирования - это повторяемая архитектурная конструкция.
Группы паттернов:
- Порождающие - отвечают за удобное и безопасное создание новых объектов или даже целых семейств объектов.
- Фабричный метод (Factory Method)
- Абстрактная фабрика (Abstract Factory)
- Строитель (Builder)
- Прототип (Prototype)
- Одиночка (Singleton)
- Структурные - отвечают за построение удобных в поддержке иерархий классов.
- Компоновщик (Composite)
- Декоратор (Decorator)
- Адаптер (Adapter)
- Заместитель (Proxy)
- Фасад (Fasade)
- Мост (Bridge)
- Легковес (Flyweight)
- Поведенческие - решают задачи эффективного и безопасного взаимодействия между объектами программы.
- Стратегия (Strategy)
- Состояние (State)
- Команда (Command)
- Итератор (Iterator)
- Посредник (Mediator)
- Наблюдатель (Observer)
- Посетитель (Visitor)
- Снимок (Memento)
- Цепочка обязанностей (Chain of Responsibility)
- Шаблонный метод (Template method)
JMS, как создать текстовое сообщение, topic/queue, selector?
Тема и очередь создаются с помощь Spring-аннотаций или конфигурирования бинов.
Подробнее здесь
Селектор сообщений - это строка, содержащая выражение. Селектор используется если вашему приложению для обмена сообщениями необходимо отфильтровать полученные сообщения.
Что нового в JMS 2.0?
В JMS 2.0 новое API призвано упростить отправку и прием JMS-сообщений (следовательно сократить написание кода). Прежнее API продолжает работать наравне с новым.
В API JMS 2.0 появились новые интерфейсы: JMSContext, JMSProducer и JMSConsumer.
JMSContext заменяет Connection и Session в классическом JMS API.
JMSProducer — это легковесная замена MessageProducer, которая позволяет задавать настройки доставки сообщений, заголовки, свойства, через вызов цепочки методов (паттерн Строитель).
JMSConsumer заменяет MessageConsumer и используется по такому же принципу.
Знакомство с JMS 2.0
What's New in JMS 2.0
XML JAXB
https://javarush.ru/quests/lectures/questcollections.level03.lecture07
https://habr.com/ru/post/437914/