Deformable Convolutional Networks - Deepest-Project/Greedy-Survey GitHub Wiki
Resources
Abstract
기존 CNN 구조의 한계:
Convolutional neural networks (CNNs) are inherently limited to model geometric transformations due to the fixed geometric structures in their building modules.
논문에서 제시하는 해결 방법:
In this work, we introduce two new modules ..., deformable convolution and deformable RoI pooling.
Introduction
기존 모델의 두 가지 단점:
First, the geometric transformations are assumed fixed and known. Such prior knowledge is used to augment data, and design the features and algorithms.
Second, handcrafted design of invariant features and algorithms could be difficult or infeasible for overly complex transformations, even when they are known.
이러한 단점의 원인:
... a convolution unit samples the input feature map at fixed locations; a pooling palyer reduces the spatial resolution at a fixed ratio; a RoI pooling layer separates a RoI into fixed spatial bins, etc.
... all approaches still rely on the primitive bounding box based feature extraction.
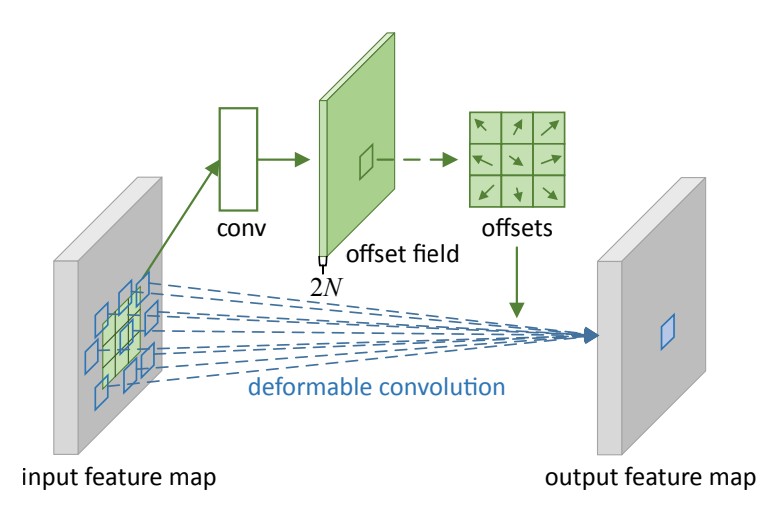
Deformable Convolution:
It adds 2D offsets to the regular grid sampling locations in the standard convolution.
The offsets are learned from the preceding feature maps, via additional convolutional layers.
Deformable RoI pooling:
It adds an offset to each bin position in the regular bin partition of the previous RoI pooling. Similarly, the offsets are learned from the preceding feature maps and RoIs, ...
Detail
Deformable Convolutions
A 3 by 3 kernel vanilla convolution can be written as follows:
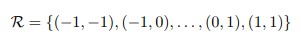
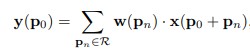
where R defines the 3 by 3 grid, w is the filter weight matrix, and x is the input feature map.
Then we add an extra offset parameter to change this to deformable convolution:
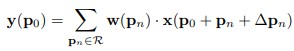
This offset parameter is learned through a second convolutional network. The N on the following figure is 3 * 3 = 9 for the 3 by 3 deformable convolution case.
Deformable RoI Pooling
As in the case of deformable convolutions, from the following vallina RoI pooling,
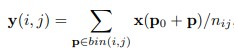
we add an extra offset parameter to change this to deformable RoI pooling:
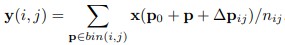
This offset parameter is learned through a fully connected layer.
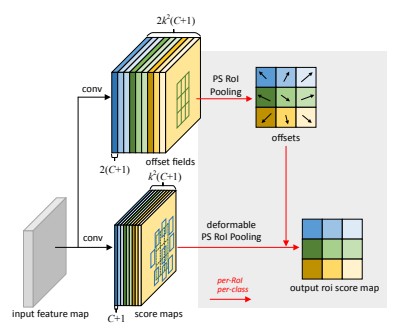
Deformable Position-Sensitive RoI Pooling
We obtain PS-RoI pooling from the RoI pooling equation by changing the x to x_{i,j}.
In this case, the offset parameters are learned from a second convolutional network, following the spirit of Fast R-CNN.
Deformable Convolutional Networks
Both deformable convolutional layers and deformable RoI pooling layers have the same input and output dimensions as their vanilla versions. Thus, they can readily replace their vanilla counterparts. The resulting CNNs are called deformable ConvNets.
The main effect of adding these deformable layers is that the receptive field is adaptively adjusted according to the objects' scale and shape.

Experiments and Results
이 부분은 논문으로 대체합니다.
Discussion
Parameter 개수가 많이 늘지는 않아 모델의 측면에서는 lightweight이지만, 구현이 상당히 귀찮은데 비해 성능 향상은 그리 높지는 않은 것 같습니다. Default convolution grid + offset으로 이원화하여 각각을 convolution layer로 나눠 학습하기 보다는 이 둘을 합쳐서 하나로 만들어보고 싶습니다.