Algorithm Analysis - David-Chae/Algorithms_Notes_Solutions GitHub Wiki
Describe algorithm analysis.
Algorithm analysis is an important part of computational complexity theory, which provides theoretical estimation for the required resources of an algorithm to solve a specific computational problem. Analysis of algorithms is the determination of the amount of time and space resources required to execute it.
Why analysis of it is important?
In terms of designing a solution to an IT problem, computers are fast but not infinitely fast. The memory may be inexpensive but not free. So, computing time is therefore a bounded resource and so is the space in memory. So we should use these resources wisely and algorithms that are efficient in terms of time and space will help you do so. So, analysis is important for programmer to know if the program is efficient.
Here are few reasons:
- To predict the behavior of an algorithm without implementing it on a specific computer.
- It is much more convenient to have simple measures for the efficiency of an algorithm than to implement the algorithm and test the efficiency every time a certain parameter in the underlying computer system changes.
- It is impossible to predict the exact behavior of an algorithm. There are too many influencing factors. The analysis is thus only an approximation; it is not perfect.
- More importantly, by analyzing different algorithms, we can compare them to determine the best one for our purpose.
In the analysis of the algorithm, it generally focused on CPU (time) usage, Memory usage, Disk usage, and Network usage. All are important, but the most concern is about the CPU time. Be careful to differentiate between:
Performance: How much time/memory/disk/etc. is used when a program is run. This depends on the machine, compiler, etc. as well as the code we write.
Complexity: How do the resource requirements of a program or algorithm scale, i.e. what happens as the size of the problem being solved by the code gets larger.
Note: Complexity affects performance but not vice-versa.
Identify and Describe the types of algorithm analysis
There are three types of algorithm analysis.
Best case: Define the input for which algorithm takes less time or minimum time. In the best case calculate the lower bound of an algorithm. Example: In the linear search when search data is present at the first location of large data then the best case occurs.
Worst Case: Define the input for which algorithm takes a long time or maximum time. In the worst calculate the upper bound of an algorithm. Example: In the linear search when search data is not present at all then the worst case occurs.
Average case: In the average case take all random inputs and calculate the computation time for all inputs. And then we divide it by the total number of inputs. Average case = all random case time / total no of case.
What is Asymptotic Analysis?
The main idea of asymptotic analysis is to have a measure of the efficiency of algorithms that don’t depend on machine-specific constants and don’t require algorithms to be implemented and time taken by programs to be compared. Asymptotic notations are mathematical tools to represent the time complexity of algorithms for asymptotic analysis.
-
"Asymptotic analysis is the process of calculating the running time of an algorithm in mathematical units to find the program’s limitations, or “run-time performance.” The goal is to determine the best case, worst case and average case time required to execute a given task."
-
"In Asymptotic Analysis, we evaluate the performance of an algorithm in terms of input size (we don’t measure the actual running time). We calculate, how the time (or space) taken by an algorithm increases with the input size."
-
"Asymptotic analysis of an algorithm refers to defining the mathematical boundation/framing of its run-time performance. Using asymptotic analysis, we can very well conclude the best case, average case, and worst case scenario of an algorithm."
Popular Notations in Complexity Analysis of Algorithms
-
Big-O Notation We define an algorithm’s worst-case time complexity by using the Big-O notation, which determines the set of functions grows slower than or at the same rate as the expression. Furthermore, it explains the maximum amount of time an algorithm requires considering all input values.
-
Omega Notation It defines the best case of an algorithm’s time complexity, the Omega notation defines whether the set of functions will grow faster or at the same rate as the expression. Furthermore, it explains the minimum amount of time an algorithm requires considering all input values.
-
Theta Notation It defines the average case of an algorithm’s time complexity, the Theta notation defines when the set of functions lies in both O(expression) and Omega(expression), then Theta notation is used. This is how we define a time complexity average case for an algorithm.
Measurement of Complexity of an Algorithm
Based on the above three notations of Time Complexity there are three cases to analyze an algorithm:
1. Worst Case Analysis (Mostly used)
In the worst-case analysis, we calculate the upper bound on the running time of an algorithm. We must know the case that causes a maximum number of operations to be executed. For Linear Search, the worst case happens when the element to be searched (x) is not present in the array. When x is not present, the search() function compares it with all the elements of arr[] one by one. Therefore, the worst-case time complexity of the linear search would be O(n).
2. Best Case Analysis (Very Rarely used)
In the best case analysis, we calculate the lower bound on the running time of an algorithm. We must know the case that causes a minimum number of operations to be executed. In the linear search problem, the best case occurs when x is present at the first location. The number of operations in the best case is constant (not dependent on n). So time complexity in the best case would be Ω(1)
3. Average Case Analysis (Rarely used)
In average case analysis, we take all possible inputs and calculate the computing time for all of the inputs. Sum all the calculated values and divide the sum by the total number of inputs. We must know (or predict) the distribution of cases. For the linear search problem, let us assume that all cases are uniformly distributed (including the case of x not being present in the array). So we sum all the cases and divide the sum by (n+1). Following is the value of average-case time complexity.
Which Complexity analysis is generally used?
Below is the ranked mention of complexity analysis notation based on popularity:
1. Worst Case Analysis:
Most of the time, we do worst-case analyses to analyze algorithms. In the worst analysis, we guarantee an upper bound on the running time of an algorithm which is good information.
2. Average Case Analysis
The average case analysis is not easy to do in most practical cases and it is rarely done. In the average case analysis, we must know (or predict) the mathematical distribution of all possible inputs.
3. Best Case Analysis
The Best Case analysis is bogus. Guaranteeing a lower bound on an algorithm doesn’t provide any information as in the worst case, an algorithm may take years to run.
Examples with their complexity analysis:
- Linear search algorithm: `
// Java implementation of the approach
public class GFG {
// Linearly search x in arr[]. If x is present then
// return the index, otherwise return -1
static int search(int arr[], int n, int x)
{
int i;
for (i = 0; i < n; i++) {
if (arr[i] == x) {
return i;
}
}
return -1;
}
/* Driver's code*/
public static void main(String[] args)
{
int arr[] = { 1, 10, 30, 15 };
int x = 30;
int n = arr.length;
// Function call
System.out.printf("%d is present at index %d", x,
search(arr, n, x));
}
}
`
Time Complexity Analysis: (In Big-O notation)
Best Case: O(1), This will take place if the element to be searched is on the first index of the given list. So, the number of comparisons, in this case, is 1.
Average Case: O(n), This will take place if the element to be searched is on the middle index of the given list.
Worst Case: O(n), This will take place if: The element to be searched is on the last index The element to be searched is not present on the list
- In this example, we will take an array of length (n) and deals with the following cases :
-
If (n) is even then our output will be 0.
-
If (n) is odd then our output will be the sum of the elements of the array.
1. Theta Notation (Θ-Notation):
Theta notation encloses the function from above and below. Since it represents the upper and the lower bound of the running time of an algorithm, it is used for analyzing the average-case complexity of an algorithm.
Let g and f be the function from the set of natural numbers to itself. The function f is said to be Θ(g), if there are constants c1, c2 > 0 and a natural number n0 such that c1* g(n) ≤ f(n) ≤ c2 * g(n) for all n ≥ n0
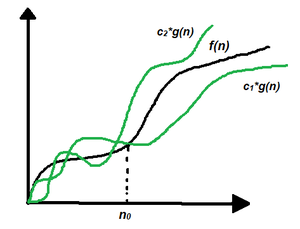
Θ (g(n)) = {f(n): there exist positive constants c1, c2 and n0 such that 0 ≤ c1 * g(n) ≤ f(n) ≤ c2 * g(n) for all n ≥ n0}
Note: Θ(g) is a set.
2. Big-O Notation (O-notation):
Big-O notation represents the upper bound of the running time of an algorithm. Therefore, it gives the worst-case complexity of an algorithm.
If f(n) describes the running time of an algorithm, f(n) is O(g(n)) if there exist a positive constant C and n0 such that, 0 ≤ f(n) ≤ cg(n) for all n ≥ n0

O(g(n)) = { f(n): there exist positive constants c and n0 such that 0 ≤ f(n) ≤ cg(n) for all n ≥ n0 }
For example, Consider the case of Insertion Sort. It takes linear time in the best case and quadratic time in the worst case. We can safely say that the time complexity of the Insertion sort is O(n2). Note: O(n2) also covers linear time.
If we use Θ notation to represent the time complexity of Insertion sort, we have to use two statements for best and worst cases:
The worst-case time complexity of Insertion Sort is Θ(n2). The best case time complexity of Insertion Sort is Θ(n). The Big-O notation is useful when we only have an upper bound on the time complexity of an algorithm. Many times we easily find an upper bound by simply looking at the algorithm.
Examples :
{ 100 , log (2000) , 10^4 } belongs to O(1) U { (n/4) , (2n+3) , (n/100 + log(n)) } belongs to O(n) U { (n^2+n) , (2n^2) , (n^2+log(n))} belongs to O( n^2)
Note: Here, U represents union, we can write it in these manner because O provides exact or upper bounds .
3. Omega Notation (Ω-Notation):
Omega notation represents the lower bound of the running time of an algorithm. Thus, it provides the best case complexity of an algorithm.
Let g and f be the function from the set of natural numbers to itself. The function f is said to be Ω(g), if there is a constant c > 0 and a natural number n0 such that c*g(n) ≤ f(n) for all n ≥ n0

Mathematical Representation of Omega notation : Ω(g(n)) = { f(n): there exist positive constants c and n0 such that 0 ≤ cg(n) ≤ f(n) for all n ≥ n0 }
Let us consider the same Insertion sort example here. The time complexity of Insertion Sort can be written as Ω(n), but it is not very useful information about insertion sort, as we are generally interested in worst-case and sometimes in the average case.
Examples :
{ (n^2+n) , (2n^2) , (n^2+log(n))} belongs to Ω( n^2) U { (n/4) , (2n+3) , (n/100 + log(n)) } belongs to Ω(n) U { 100 , log (2000) , 10^4 } belongs to Ω(1)
Note: Here, U represents union, we can write it in these manner because Ω provides exact or lower bounds.
Properties of Asymptotic Notations:
1. General Properties:
If f(n) is O(g(n)) then a*f(n) is also O(g(n)), where a is a constant.
Example:
f(n) = 2n²+5 is O(n²) then, 7*f(n) = 7(2n²+5) = 14n²+35 is also O(n²).
Similarly, this property satisfies both Θ and Ω notation.
We can say,
If f(n) is Θ(g(n)) then af(n) is also Θ(g(n)), where a is a constant. If f(n) is Ω (g(n)) then af(n) is also Ω (g(n)), where a is a constant.
2. Transitive Properties:
If f(n) is O(g(n)) and g(n) is O(h(n)) then f(n) = O(h(n)).
Example:
If f(n) = n, g(n) = n² and h(n)=n³ n is O(n²) and n² is O(n³) then, n is O(n³)
Similarly, this property satisfies both Θ and Ω notation.
We can say,
If f(n) is Θ(g(n)) and g(n) is Θ(h(n)) then f(n) = Θ(h(n)) . If f(n) is Ω (g(n)) and g(n) is Ω (h(n)) then f(n) = Ω (h(n))
3. Reflexive Properties:
Reflexive properties are always easy to understand after transitive. If f(n) is given then f(n) is O(f(n)). Since MAXIMUM VALUE OF f(n) will be f(n) ITSELF! Hence x = f(n) and y = O(f(n) tie themselves in reflexive relation always.
Example:
f(n) = n² ; O(n²) i.e O(f(n)) Similarly, this property satisfies both Θ and Ω notation.
We can say that,
If f(n) is given then f(n) is Θ(f(n)). If f(n) is given then f(n) is Ω (f(n)).
4. Symmetric Properties:
If f(n) is Θ(g(n)) then g(n) is Θ(f(n)).
Example:
If(n) = n² and g(n) = n² then, f(n) = Θ(n²) and g(n) = Θ(n²)
This property only satisfies for Θ notation.
5. Transpose Symmetric Properties:
If f(n) is O(g(n)) then g(n) is Ω (f(n)).
Example:
If(n) = n , g(n) = n² then n is O(n²) and n² is Ω (n)
This property only satisfies O and Ω notations.
6. Some More Properties:
- If f(n) = O(g(n)) and f(n) = Ω(g(n)) then f(n) = Θ(g(n))
- If f(n) = O(g(n)) and d(n)=O(e(n)) then f(n) + d(n) = O( max( g(n), e(n) ))
Example:
f(n) = n i.e O(n) d(n) = n² i.e O(n²) then f(n) + d(n) = n + n² i.e O(n²)
- If f(n)=O(g(n)) and d(n)=O(e(n)) then f(n) * d(n) = O( g(n) * e(n))
Example:
f(n) = n i.e O(n) d(n) = n² i.e O(n²) then f(n) * d(n) = n * n² = n³ i.e O(n³)
Note: If f(n) = O(g(n)) then g(n) = Ω(f(n))
How to Analyse Loops for Complexity Analysis of Algorithms
Constant Time Complexity O(1):
The time complexity of a function (or set of statements) is considered as O(1) if it doesn’t contain a loop, recursion, and call to any other non-constant time function. i.e. set of non-recursive and non-loop statements
Example:
swap() function has O(1) time complexity. A loop or recursion that runs a constant number of times is also considered O(1). For example, the following loop is O(1).
Linear Time Complexity O(n):
The Time Complexity of a loop is considered as O(n) if the loop variables are incremented/decremented by a constant amount. For example following functions have O(n) time complexity.
Quadratic Time Complexity O(nc):
The time complexity is defined as an algorithm whose performance is directly proportional to the squared size of the input data, as in nested loops it is equal to the number of times the innermost statement is executed. For example, the following sample loops have O(n2) time complexity
Logarithmic Time Complexity O(Log n):
The time Complexity of a loop is considered as O(Logn) if the loop variables are divided/multiplied by a constant amount. And also for recursive calls in the recursive function, the Time Complexity is considered as O(Logn).
for (int i = 1; i <= n; i *= c) { // some O(1) expressions } for (int i = n; i > 0; i /= c) { // some O(1) expressions }
// Recursive function void recurse(n) { if (n == 0) return; else { // some O(1) expressions } recurse(n - 1); }
Logarithmic Time Complexity O(Log Log n):
The Time Complexity of a loop is considered as O(LogLogn) if the loop variables are reduced/increased exponentially by a constant amount.
// Here c is a constant greater than 1 for (int i = 2; i <= n; i = pow(i, c)) { // some O(1) expressions } // Here fun is sqrt or cuberoot or any other constant root for (int i = n; i > 1; i = fun(i)) { // some O(1) expressions }
How to calculate time complexity when there are many if, else statements inside loops?
As discussed here, the worst-case time complexity is the most useful among best, average and worst. Therefore we need to consider the worst case. We evaluate the situation when values in if-else conditions cause a maximum number of statements to be executed. For example, consider the linear search function where we consider the case when an element is present at the end or not present at all. When the code is too complex to consider all if-else cases, we can get an upper bound by ignoring if-else and other complex control statements.
How to calculate the time complexity of recursive functions?
The time complexity of a recursive function can be written as a mathematical recurrence relation. To calculate time complexity, we must know how to solve recurrences.
There are mainly three ways of solving recurrences:
Substitution Method: We make a guess for the solution and then we use mathematical induction to prove the guess is correct or incorrect.
For example consider the recurrence T(n) = 2T(n/2) + n
We guess the solution as T(n) = O(nLogn). Now we use induction to prove our guess.
We need to prove that T(n) <= cnLogn. We can assume that it is true for values smaller than n.
T(n) = 2T(n/2) + n <= 2cn/2Log(n/2) + n = cnLogn – cnLog2 + n = cnLogn – cn + n <= cnLogn
Recurrence Tree Method: In this method, we draw a recurrence tree and calculate the time taken by every level of the tree. Finally, we sum the work done at all levels. To draw the recurrence tree, we start from the given recurrence and keep drawing till we find a pattern among levels. The pattern is typically arithmetic or geometric series.
For example, consider the recurrence relation
T(n) = T(n/4) + T(n/2) + cn2
cn2
/ \
T(n/4) T(n/2)
If we further break down the expression T(n/4) and T(n/2), we get the following recursion tree.
cn2
/ \
c(n2)/16 c(n2)/4
/ \ /
T(n/16) T(n/8) T(n/8) T(n/4)
Breaking down further gives us following
cn2
/ \
c(n2)/16 c(n2)/4
/ \ / \
c(n2)/256 c(n2)/64 c(n2)/64 c(n2)/16 / \ / \ / \ / \
To know the value of T(n), we need to calculate the sum of tree nodes level by level. If we sum the above tree level by level,
we get the following series T(n) = c(n^2 + 5(n^2)/16 + 25(n^2)/256) + …. The above series is a geometrical progression with a ratio of 5/16.
To get an upper bound, we can sum the infinite series. We get the sum as (n2)/(1 – 5/16) which is O(n2)
Master Method: Master Method is a direct way to get the solution. The master method works only for the following type of recurrences or for recurrences that can be transformed into the following type.
T(n) = aT(n/b) + f(n) where a >= 1 and b > 1
There are the following three cases:
If f(n) = O(nc) where c < Logba then T(n) = Θ(nLogba) If f(n) = Θ(nc) where c = Logba then T(n) = Θ(ncLog n) If f(n) = Ω(nc) where c > Logba then T(n) = Θ(f(n)) How does this work? The master method is mainly derived from the recurrence tree method. If we draw the recurrence tree of T(n) = aT(n/b) + f(n), we can see that the work done at the root is f(n), and work done at all leaves is Θ(nc) where c is Logba. And the height of the recurrence tree is Logbn
In the recurrence tree method, we calculate the total work done. If the work done at leaves is polynomially more, then leaves are the dominant part, and our result becomes the work done at leaves (Case 1). If work done at leaves and root is asymptotically the same, then our result becomes height multiplied by work done at any level (Case 2). If work done at the root is asymptotically more, then our result becomes work done at the root (Case 3).
Examples of some standard algorithms whose time complexity can be evaluated using the Master Method
Merge Sort: T(n) = 2T(n/2) + Θ(n). It falls in case 2 as c is 1 and Logba] is also 1. So the solution is Θ(n Logn) Binary Search: T(n) = T(n/2) + Θ(1). It also falls in case 2 as c is 0 and Logba is also 0. So the solution is Θ(Logn) Notes:
It is not necessary that a recurrence of the form T(n) = aT(n/b) + f(n) can be solved using Master Theorem. The given three cases have some gaps between them. For example, the recurrence T(n) = 2T(n/2) + n/Logn cannot be solved using master method. Case 2 can be extended for f(n) = Θ(ncLogkn) If f(n) = Θ(ncLogkn) for some constant k >= 0 and c = Logba, then T(n) = Θ(ncLogk+1n) For more details, please refer: Design and Analysis of Algorithms.
Amortized Analysis Introduction
Amortized Analysis is used for algorithms where an occasional operation is very slow, but most of the other operations are faster. In Amortized Analysis, we analyze a sequence of operations and guarantee a worst-case average time that is lower than the worst-case time of a particularly expensive operation. The example data structures whose operations are analyzed using Amortized Analysis are Hash Tables, Disjoint Sets, and Splay Trees.
Let us consider an example of simple hash table insertions. How do we decide on table size? There is a trade-off between space and time, if we make hash-table size big, search time becomes low, but the space required becomes high.
In computer science, amortized analysis is a method for analyzing a given algorithm's complexity, or how much of a resource, especially time or memory, it takes to execute. The motivation for amortized analysis is that looking at the worst-case run time can be too pessimistic. Instead, amortized analysis averages the running times of operations in a sequence over that sequence.1(https://en.wikipedia.org/wiki/Amortized_analysis#cite_note-tarjan-1): 306 As a conclusion: “Amortized analysis is a useful tool that complements other techniques such as worst-case and average-case analysis.“2(https://en.wikipedia.org/wiki/Amortized_analysis#cite_note-fiebrink-2): 14
For a given operation of an algorithm, certain situations (e.g., input parametrizations or data structure contents) may imply a significant cost in resources, whereas other situations may not be as costly. The amortized analysis considers both the costly and less costly operations together over the whole sequence of operations. This may include accounting for different types of input, length of the input, and other factors that affect its performance
Reference:
https://www.geeksforgeeks.org/what-is-algorithm-and-why-analysis-of-it-is-important/?ref=lbp https://deepai.org/machine-learning-glossary-and-terms/asymptotic-analysis https://www.geeksforgeeks.org/analysis-of-algorithms-set-1-asymptotic-analysis/?ref=lbp https://www.geeksforgeeks.org/analysis-of-algorithms-set-2-asymptotic-analysis/?ref=lbp https://www.geeksforgeeks.org/analysis-of-algorithms-set-3asymptotic-notations/?ref=lbp https://www.geeksforgeeks.org/analysis-of-algorithms-set-4-analysis-of-loops/?ref=lbp https://www.geeksforgeeks.org/analysis-algorithm-set-5-amortized-analysis-introduction/ https://en.wikipedia.org/wiki/Amortized_analysis