Reading Notes - Cyber-JL/Wiki GitHub Wiki
Def: an object is a collection of data and associated behaviors.
For example, we can assume that apples go in barrels and oranges go in baskets. Now, we have four kinds of objects: apples, oranges, baskets, and barrels. In object-oriented modeling, the term used for kind of object is class. So, in technical terms, we now have four classes of objects.
What's the difference between an object and a class? Classes describe objects. They are like blueprints for creating an object. You might have three oranges sitting on the table in front of you. Each orange is a distinct object, but all three have the attributes and behaviors associated with one class: the general class of oranges.
The relationship between the four classes of objects in our inventory system can be described using a Unified Modeling Language (invariably referred to as UML).
an Orange is somehow associated with a Basket and that an Apple is also somehow associated with a Barrel. Association is the most basic way for two classes to be related.
Data typically represents the individual characteristics of a certain object. A class can define specific sets of characteristics that are shared by all objects of that class. Any specific object can have different data values for the given characteristics.
Attributes are frequently referred to as members or properties.
Attribute types are often primitives that are standard to most programming languages, such as integer, floating-point number, string, byte, or Boolean. However, they can also represent data structures such as lists, trees, or graphs, or most notably, other classes. This is one area where the design stage can overlap with the programming stage.
Behaviors are actions that can occur on an object. The behaviors that can be performed on a specific class of objects are called methods. At the programming level, methods are like functions in structured programming, but they magically have access to all the data associated with this object. Like functions, methods can also accept parameters and return values.
Parameters to a method are a list of objects that need to be passed into the method that is being called (the objects that are passed in from the calling object are usually referred to as arguments). These objects are used by the method to perform whatever behavior or task it is meant to do. Returned values are the results of that task.
Adding models and methods to individual objects allows us to create a system of interacting objects. Each object in the system is a member of a certain class. These classes specify what types of data the object can hold and what methods can be invoked on it. The data in each object can be in a different state from other objects of the same class, and each object may react to method calls differently because of the differences in state.
The key purpose of modeling an object in object-oriented design is to determine what the public interface of that object will be. The interface is the collection of attributes and methods that other objects can use to interact with that object.
This process of hiding the implementation, or functional details, of an object, is suitably called information hiding. It is also sometimes referred to as encapsulation, but encapsulation is actually a more all-encompassing term. Encapsulated data is not necessarily hidden.
Abstraction (the process of encapsulating information with separate public and private interfaces. The private interfaces can be subject to information hiding.) is another object-oriented concept related to encapsulation and information hiding. Simply put, abstraction means dealing with the level of detail that is most appropriate to a given task. It is the process of extracting a public interface from the inner details.
Example: A driver of a car needs to interact with steering, gas pedal, and brakes. The workings of the motor, drive train, and brake subsystem doesn't matter to the driver. A mechanic, on the other hand, works at a different level of abstraction, tuning the engine and bleeding the breaks.
most design patterns rely on two basic object-oriented principles known as composition and inheritance.
Composition is the act of collecting several objects together to create a new one. Composition is usually a good choice when one object is part of another object.
ou could argue that pieces are not part of the chess set because you could replace the pieces in a chess set with a different set of pieces. While this is unlikely or impossible in a computerized version of chess, it introduces us to aggregation.
Aggregation is almost exactly like composition. The difference is that aggregate objects can exist independently. It would be impossible for a position to be associated with a different chess board, so we say the board is composed of positions. But the pieces, which might exist independently of the chess set, are said to be in an aggregate relationship with that set.
Another way to differentiate between aggregation and composition is to think about the lifespan of the object. If the composite (outside) object controls when the related (inside) objects are created and destroyed, composition is most suitable. If the related object is created independently of the composite object, or can outlast that object, an aggregate relationship makes more sense. Also, keep in mind that composition is aggregation; aggregation is simply a more general form of composition. Any composite relationship is also an aggregate relationship, but not vice versa.
The is a relationship is formed by inheritance. Inheritance is the most famous, well-known, and over-used relationship in object-oriented programming. Inheritance is sort of like a family tree.
For example, there are 32 chess pieces in our chess set, but there are only six different types of pieces (pawns, rooks, bishops, knights, king, and queen), each of which behaves differently when it is moved. All of these classes of piece have properties, such as color and the chess set they are part of, but they also have unique shapes when drawn on the chess board, and make different moves. Let's see how the six types of pieces can inherit from a Piece class.
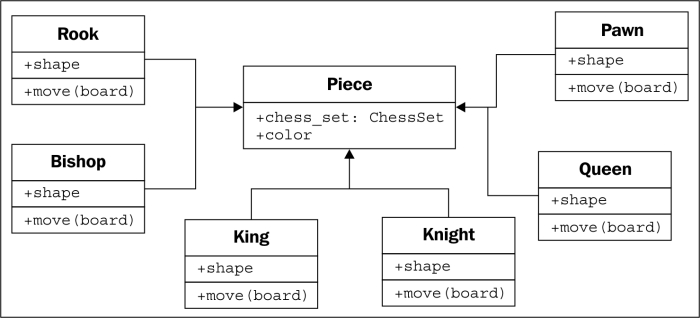
We actually know that all subclasses of the Piece class need to have a move method; otherwise, when the board tries to move the piece, it will get confused. It is possible that we would want to create a new version of the game of chess that has one additional piece (the wizard). Our current design allows us to design this piece without giving it a move method. The board would then choke when it asked the piece to move itself.
We can implement this by creating a dummy move method on the Piece class. The subclasses can then override this method with a more specific implementation. The default implementation might, for example, pop up an error message that says: That piece cannot be moved.
Overriding methods in subtypes allows very powerful object-oriented systems to be developed.
All we need to do is specify that the move method is required in any subclasses. This can be done by making Piece an abstract class with the move method declared abstract. Abstract methods basically say, "We demand this method exist in any non-abstract subclass, but we are declining to specify an implementation in this class."
Polymorphism is the ability to treat a class differently depending on which subclass is implemented.
Object-oriented design can also feature such multiple inheritance, which allows a subclass to inherit functionality from multiple parent classes. In practice, multiple inheritance can be a tricky business, and some programming languages (most notably, Java) strictly prohibit it. However, multiple inheritance can have its uses. Most often, it can be used to create objects that have two distinct sets of behaviors.
Classes in python look like:
class MyFirstClass:
pass
- class definition starts with
classfollowed by a name (of our choice) identifying the class and is terminated with a colon
We can set arbitrary attributes on an instantiated object using the dot notation:
class Point:
pass
p1 = Point()
p2 = Point()
p1.x = 5
p1.y = 4
p2.x = 3
p2.y = 6
print(p1.x, p1.y)
print(p2.x, p2.y)
returns:
5 4
3 6
This code creates an empty Point class with no data or behaviors. Then it creates two instances of that class and assigns each of those instances x and y coordinates to identify a point in two dimensions. All we need to do to assign a value to an attribute on an object is use the <object>.<attribute> = <value> syntax. This is sometimes referred to as dot notation.
Let's model a couple of actions on our Point class. We can start with a called reset that moves the point to the origin (the origin is the point where x and y are both zero).
class Point:
def reset(self):
self.x = 0
self.y = 0
p = Point()
p.reset()
print(p.x, p.y)
returns:
0 0
A method in Python is formatted identically to a function. It starts with the keyword def followed by a space and the name of the method. This is followed by a set of parentheses containing the parameter list (we'll discuss that self parameter in just a moment), and terminated with a colon. The next line is indented to contain the statements inside the method. These statements can be arbitrary Python code operating on the object itself and any parameters passed in as the method sees fit.
The one difference between methods and normal functions is that all methods have one required argument. This argument is conventionally named self.
The self argument to a method is simply a reference to the object that the method is being invoked on. We can access attributes and methods of that object as if it were any another object. This is exactly what we do inside the reset method when we set the x and y attributes of the self object.
Notice that when we call the p.reset() method, we do not have to pass the self argument into it. Python automatically takes care of this for us. It knows we're calling a method on the p object, so it automatically passes that object to the method.
We can include one that accepts another Point object as input and returns the distance between them:
import math
class Point:
def move(self, x, y):
self.x = x
self.y = y
def reset(self):
self.move(0, 0)
def calculate_distance(self, other_point):
return math.sqrt(
(self.x - other_point.x)**2 +
(self.y - other_point.y)**2)
# how to use it:
point1 = Point()
point2 = Point()
point1.reset()
point2.move(5,0)
print(point2.calculate_distance(point1))
assert (point2.calculate_distance(point1) ==
point1.calculate_distance(point2))
point1.move(3,4)
print(point1.calculate_distance(point2))
print(point1.calculate_distance(point1))
A lot has happened here. The class now has three methods. The move method accepts two arguments, x and y, and sets the values on the self object, much like the old reset method from the previous example. The old reset method now calls move, since a reset is just a move to a specific known location.
The calculate_distance method uses the not-too-complex Pythagorean theorem to calculate the distance between two points. I hope you understand the math (** means squared, and math.sqrt calculates a square root), but it's not a requirement for our current focus, learning how to write methods.
The sample code at the end of the preceding example shows how to call a method with arguments: simply include the arguments inside the parentheses, and use the same dot notation to access the method. The test code calls each method and prints the results on the console. The assert function is a simple test tool; the program will bail if the statement after assert is False (or zero, empty, or None). In this case, we use it to ensure that the distance is the same regardless of which point called the other point's calculate_distance method.
The Python initialization method is the same as any other method, except it has a special name, __init__. The leading and trailing double underscores mean this is a special method that the Python interpreter will treat as a special case.
Let's start with an initialization function on our Point class that requires the user to supply x and y coordinates when the Point object is instantiated:
class Point:
def __init__(self, x, y):
self.move(x, y)
def move(self, x, y):
self.x = x
self.y = y
def reset(self):
self.move(0, 0)
# Constructing a Point
point = Point(3, 5)
print(point.x, point.y)
Now, the point can never go without a y coordinate. If we try to construct a point without including the proper initialization parameters, it will fail with a not enough arguments error similar to the one we received earlier when we forgot the self argument.
What if we don't want to make those two arguments required?
use the same syntax Python functions use to provide default arguments. The keyword argument syntax appends an equals sign after each variable name. If the calling object does not provide this argument, then the default argument is used instead. The variables will still be available to the function, but they will have the values specified in the argument list. Here's an example:
class Point:
def __init__(self, x=0, y=0):
self.move(x, y)
The constructor function is called __new__ as opposed to __init__, and accepts exactly one argument; the class that is being constructed (it is called before the object is constructed, so there is no self argument). It also has to return the newly created object. This has interesting possibilities when it comes to the complicated art of metaprogramming, but is not very useful in day-to-day programming. In practice, you will rarely, if ever, need to use __new__ and __init__ will be sufficient.
- Modules are simply Python files, nothing more. The single file in our small program is a module. Two Python files are two modules. If we have two files in the same folder, we can load a class from one module for use in the other module.
The import statement is used for importing modules or specific classes or functions from modules.
ex1.
import database
db = database.Database()
# Do queries on db
ex2.
from database import Database
db = Database()
# Do queries on db
ex3.
from database import Database as DB
db = DB()
# Do queries on db
ex4.
from database import Database, Query
A package is a collection of modules in a folder. The name of the package is the name of the folder. All we need to do to tell Python that a folder is a package is place a (normally empty) file in the folder named __init__.py. If we forget this file, we won't be able to import modules from that folder.
Let's put our modules inside an ecommerce package in our working folder, which will also contain a main.py file to start the program. Let's additionally add another package in the ecommerce package for various payment options. The folder hierarchy will look like this:
parent_directory/
main.py
ecommerce/
__init__.py
database.py
products.py
payments/
__init__.py
square.py
stripe.py
Absolute imports specify the complete path to the module, function, or path we want to import. If we need access to the Product class inside the products module, we could use any of these syntaxes to do an absolute import:
import ecommerce.products
product = ecommerce.products.Product()
or
from ecommerce.products import Product
product = Product()
or
from ecommerce import products
product = products.Product()
The import statements use the period operator to separate packages or modules.
Relative imports are basically a way of saying find a class, function, or module as it is positioned relative to the current module. For example, if we are working in the products module and we want to import the Database class from the database module next to it, we could use a relative import:
from .database import Database
The period in front of database says "use the database module inside the current package".
If we were editing the paypal module inside the ecommerce.payments package, we would want to say "use the database package inside the parent package" instead. This is easily done with two periods, as shown here:
from ..database import Database
We can use more periods to go further up the hierarchy. Of course, we can also go down one side and back up the other. We don't have a deep enough example hierarchy to illustrate this properly, but the following would be a valid import if we had an ecommerce.contact package containing an email module and wanted to import the send_mail function into our paypal module:
from ..contact.email import send_mail
Inside any one module, we can specify variables, classes, or functions. They can be a handy way to store the global state without namespace conflicts. For example, we have been importing the Database class into various modules and then instantiating it, but it might make more sense to have only one database object globally available from the database module. The database module might look like this:
class Database:
# the database implementation
pass
database = Database()
Then we can use any of the import methods we've discussed to access the `database object, for example:
from ecommerce.database import database
A problem with the preceding class is that the database object is created immediately when the module is first imported, which is usually when the program starts up. This isn't always ideal since connecting to a database can take a while, slowing down startup, or the database connection information may not yet be available. We could delay creating the database until it is actually needed by calling an initialize_database function to create the module-level variable:
class Database:
# the database implementation
pass
database = None
def initialize_database():
global database
database = Database()
The global keyword tells Python that the database variable inside initialize_database is the module level one we just defined. If we had not specified the variable as global, Python would have created a new local variable that would be discarded when the method exits, leaving the module-level value unchanged.
As these two examples illustrate, all module-level code is executed immediately at the time it is imported. However, if it is inside a method or function, the function will be created, but its internal code will not be executed until the function is called. This can be a tricky thing for scripts (such as the main script in our e-commerce example) that perform execution. Often, we will write a program that does something useful, and then later find that we want to import a function or class from that module in a different program. However, as soon as we import it, any code at the module level is immediately executed. If we are not careful, we can end up running the first program when we really only meant to access a couple functions inside that module.
To solve this, we should always put our startup code in a function (conventionally, called main) and only execute that function when we know we are running the module as a script, but not when our code is being imported from a different script. But how do we know this?
class UsefulClass:
'''This class might be useful to other modules.'''
pass
def main():
'''creates a useful class and does something with it for our module.'''
useful = UsefulClass()
print(useful)
if __name__ == "__main__":
main()
prefix it with a double underscore, __. This will perform name mangling on the attribute in question. This basically means that the method can still be called by outside objects if they really want to do it, but it requires extra work and is a strong indicator that you demand that your attribute remains private. For example:
class SecretString:
'''A not-at-all secure way to store a secret string.'''
def __init__(self, plain_string, pass_phrase):
self.__plain_string = plain_string
self.__pass_phrase = pass_phrase
def decrypt(self, pass_phrase):
'''Only show the string if the pass_phrase is correct.'''
if pass_phrase == self.__pass_phrase:
return self.__plain_string
else:
return ''
All python classes are subclasses of the special class named object. This class allows python to treat all objects the same way.
If we don't explicitly inherit from, a different class, our classes will automatically inherit from object. However, we can openly state that our class derives from object.
class MySubClass(object):
pass
This is an example of inheritance.
If we don't explicitly provide a different superclass, python automatically inherits from object. A superclass/parent class is a class that is being inherited from. A subclass is a class that is inheriting from a superclass. The superclass is object, and MySubClass is the subclass.
The simplest use of inheritance is to add functionality to an existing class.start with a simple contact manager that tracks the name and e-mail address of several people. The contact class is responsible for maintaining a list of all contacts in a class variable, and for initializing the name and address for an individual contact:
class Contact:
all_contacts = []
def __init__(self, name, email):
self.name = name
self.email = email
Contact.all_contacts.append(self)
This example introduces us to class variables. The all_contacts list, because it is part of the class definition, is shared by all instances of this class. This means that there is only one Contact.all_contacts list, which we can access as Contact.all_contacts. Less obviously, we can also access it as self.all_contacts on any object instantiated from Contact. If the field can't be found on the object, then it will be found on the class and thus refer to the same single list.
This is a simple class that allows us to track a couple of pieces of data about each contact. But what if some of our contacts are also suppliers that we need to order supplies from? We could add an order method to the Contact class, but that would allow people to accidentally order things from contacts who are customers or family friends. Instead, let's create a new Supplier class that acts like our Contact class, but has an additional order method:
class Supplier(Contact):
def order(self, order):
print("If this were a real system we would send "
"'{}' order to '{}'".format(order, self.name))
An interesting use of inheritance is adding functionality to built-in classes. In the Contact class seen earlier, we are adding contacts to a list of all contacts. What if we also wanted to search that list by name? Well, we could add a method on the Contact class to search it, but it feels like this method actually belongs to the list itself. We can do this using inheritance:
class ContactList(list):
def search(self, name):
'''Return all contacts that contain the search value
in their name.'''
matching_contacts = []
for contact in self:
if name in contact.name:
matching_contacts.append(contact)
return matching_contacts
class Contact:
all_contacts = ContactList()
def __init__(self, name, email):
self.name = name
self.email = email
self.all_contacts.append(self)
Instead of instantiating a normal list as our class variable, we create a new ContactList class that extends the built-in list. Then, we instantiate this subclass as our all_contacts list. We can test the new search functionality as follows:
>>> c1 = Contact("John A", "[email protected]")
>>> c2 = Contact("John B", "[email protected]")
>>> c3 = Contact("Jenna C", "[email protected]")
>>> [c.name for c in Contact.all_contacts.search('John')]
['John A', 'John B']
To change the built-in syntax [] into something we can inherit from we creating an empty list with [] is actually a shorthand for creating an empty list using list(); the two syntaxes behave identically:
>>> [] == list()
True
In reality, the [] syntax is actually so-called syntax sugar that calls the list() constructor under the hood. The list data type is a class that we can extend. In fact, the list itself extends the object class:
>>> isinstance([], object)
True
We can extend the dict class, which is, similar to the list, the class that is constructed when using the {} syntax shorthand:
class LongNameDict(dict):
def longest_key(self):
longest = None
for key in self:
if not longest or len(key) > len(longest):
longest = key
return longest
Most built-in types can be similarly extended. Commonly extended built-ins are object, list, set, dict, file, and str. Numerical types such as int and float are also occasionally inherited from.
Our contact class allows only a name and an e-mail address. This may be sufficient for most contacts, but what if we want to add a phone number for our close friends? we can do this easily by just setting a phone attribute on the contact after it is constructed. But if we want to make this third variable available on initialization, we have to override init. Overriding means altering or replacing a method of the superclass with a new method (with the same name) in the subclass. No special syntax is needed to do this; the subclass's newly created method is automatically called instead of the superclass's method. For example:
class Friend(Contact):
def __init__(self, name, email, phone):
self.name = name
self.email = email
self.phone = phone
Any method can be overridden, not just init. Before we go on, however, we need to address some problems in this example. Our Contact and Friend classes have duplicate code to set up the name and email properties; this can make code maintenance complicated as we have to update the code in two or more places. More alarmingly, our Friend class is neglecting to add itself to the all_contacts list we have created on the Contact class.
What we really need is a way to execute the original init method on the Contact class. This is what the super function does; it returns the object as an instance of the parent class, allowing us to call the parent method directly:
class Friend(Contact):
def __init__(self, name, email, phone):
super().__init__(name, email)
self.phone = phone
This example first gets the instance of the parent object using super, and calls init on that object, passing in the expected arguments. It then does its own initialization, namely, setting the phone attribute.
A super() call can be made inside any method, not just init. This means all methods can be modified via overriding and calls to super. The call to super can also be made at any point in the method; we don't have to make the call as the first line in the method. For example, we may need to manipulate or validate incoming parameters before forwarding them to the superclass.
Multiple inheritance is a touchy subject. In principle, it's very simple: a subclass that inherits from more than one parent class is able to access functionality from both of them. In practice, this is less useful than it sounds and many expert programmers recommend against using it.
The simplest and most useful form of multiple inheritance is called a mixin. A mixin is generally a superclass that is not meant to exist on its own, but is meant to be inherited by some other class to provide extra functionality. For example, let's say we wanted to add functionality to our Contact class that allows sending an e-mail to self.email. Sending e-mail is a common task that we might want to use on many other classes. So, we can write a simple mixin class to do the e-mailing for us:
class MailSender:
def send_mail(self, message):
print("Sending mail to " + self.email)
# Add e-mail logic here
This class doesn't do anything special (in fact, it can barely function as a standalone class), but it does allow us to define a new class that describes both a Contact and a MailSender, using multiple inheritance:
class EmailableContact(Contact, MailSender):
pass
The Contact initializer is still adding the new contact to the all_contacts list, and the mixin is able to send mail to self.email so we know everything is working.
Multiple inheritance works all right when mixing methods from different classes, but it gets very messy when we have to call methods on the superclass. There are multiple superclasses. How do we know which one to call? How do we know what order to call them in?
Inheritance is also a viable solution, and that's what we want to explore. Let's add a new class that holds an address. We'll call this new class "AddressHolder" instead of "Address" because inheritance defines an is a relationship. It is not correct to say a "Friend" is an "Address" , but since a friend can have an "Address" , we can argue that a "Friend" is an "AddressHolder". Later, we could create other entities (companies, buildings) that also hold addresses. Here's our AddressHolder class:
class AddressHolder:
def __init__(self, street, city, state, code):
self.street = street
self.city = city
self.state = state
self.code = code
We can use multiple inheritance to add this new class as a parent of our existing Friend class. The tricky part is that we now have two parent init methods both of which need to be initialized. And they need to be initialized with different arguments. How do we do this? Well, we could start with a naive approach:
class Friend(Contact, AddressHolder):
def __init__(
self, name, email, phone,street, city, state, code):
Contact.__init__(self, name, email)
AddressHolder.__init__(self, street, city, state, code)
self.phone = phone
we directly call the init function on each of the superclasses and explicitly pass the self argument. This example technically works; we can access the different variables directly on the class. But there are a few problems.
First, it is possible for a superclass to go uninitialized if we neglect to explicitly call the initializer. This could cause hard-to-debug program crashes in common scenarios.
Second, and more sinister, is the possibility of a superclass being called multiple times because of the organization of the class hierarchy. Look at this inheritance diagram:

The init method from the Friend class first calls init on Contact, which implicitly initializes the object superclass (remember, all classes derive from object). Friend then calls init on AddressHolder, which implicitly initializes the object superclass again. This means the parent class has been set up twice. With the object class, that's relatively harmless, but in some situations, it could spell disaster. Imagine trying to connect to a database twice for every request!
Let's look at a second contrived example that illustrates this problem more clearly. Here we have a base class that has a method named call_me. Two subclasses override that method, and then another subclass extends both of these using multiple inheritance. This is called diamond inheritance because of the diamond shape of the class diagram:

Let's convert this diagram to code; this example shows when the methods are called:
class BaseClass:
num_base_calls = 0
def call_me(self):
print("Calling method on Base Class")
self.num_base_calls += 1
class LeftSubclass(BaseClass):
num_left_calls = 0
def call_me(self):
BaseClass.call_me(self)
print("Calling method on Left Subclass")
self.num_left_calls += 1
class RightSubclass(BaseClass):
num_right_calls = 0
def call_me(self):
BaseClass.call_me(self)
print("Calling method on Right Subclass")
self.num_right_calls += 1
class Subclass(LeftSubclass, RightSubclass):
num_sub_calls = 0
def call_me(self):
LeftSubclass.call_me(self)
RightSubclass.call_me(self)
print("Calling method on Subclass")
self.num_sub_calls += 1
This example simply ensures that each overridden call_me method directly calls the parent method with the same name. It lets us know each time a method is called by printing the information to the screen. It also updates a static variable on the class to show how many times it has been called. If we instantiate one Subclass object and call the method on it once, we get this output:
>>> s = Subclass()
>>> s.call_me()
Calling method on Base Class
Calling method on Left Subclass
Calling method on Base Class
Calling method on Right Subclass
Calling method on Subclass
>>> print(
... s.num_sub_calls,
... s.num_left_calls,
... s.num_right_calls,
... s.num_base_calls)
1 1 1 2
Thus we can clearly see the base class's call_me method being called twice. This could lead to some insidious bugs if that method is doing actual work—like depositing into a bank account—twice.
The thing to keep in mind with multiple inheritance is that we only want to call the "next" method in the class hierarchy, not the "parent" method. In fact, that next method may not be on a parent or ancestor of the current class. The super keyword comes to our rescue once again. Indeed, super was originally developed to make complicated forms of multiple inheritance possible. Here is the same code written using super:
class BaseClass:
num_base_calls = 0
def call_me(self):
print("Calling method on Base Class")
self.num_base_calls += 1
class LeftSubclass(BaseClass):
num_left_calls = 0
def call_me(self):
super().call_me()
print("Calling method on Left Subclass")
self.num_left_calls += 1
class RightSubclass(BaseClass):
num_right_calls = 0
def call_me(self):
super().call_me()
print("Calling method on Right Subclass")
self.num_right_calls += 1
class Subclass(LeftSubclass, RightSubclass):
num_sub_calls = 0
def call_me(self):
super().call_me()
print("Calling method on Subclass")
self.num_sub_calls += 1
The change is pretty minor; we simply replaced the naive direct calls with calls to super(), although the bottom subclass only calls super once rather than having to make the calls for both the left and right. The change is simple enough, but look at the difference when we execute it:
>>> s = Subclass()
>>> s.call_me()
Calling method on Base Class
Calling method on Left Subclass
Calling method on Base Class
Calling method on Right Subclass
Calling method on Subclass
>>> print(s.num_sub_calls, s.num_left_calls, s.num_right_calls, s.num_base_calls)
1 1 1 1
Looks good, our base method is only being called once. But what is super() actually doing here? Since the print statements are executed after the super calls, the printed output is in the order each method is actually executed. Let's look at the output from back to front to see who is calling what.
First, call_me of Subclass calls super().call_me(), which happens to refer to LeftSubclass.call_me(). The LeftSubclass.call_me() method then calls super().call_me(), but in this case, super() is referring to RightSubclass.call_me().
Pay particular attention to this: the super call is not calling the method on the superclass of LeftSubclass (which is BaseClass). Rather, it is calling RightSubclass, even though it is not a direct parent of LeftSubclass! This is the next method, not the parent method. RightSubclass then calls BaseClass and the super calls have ensured each method in the class hierarchy is executed once.
In the init method for Friend, we were originally calling init for both parent classes, with different sets of arguments:
Contact.__init__(self, name, email)
AddressHolder.__init__(self, street, city, state, code)
How can we manage different sets of arguments when using super? We don't necessarily know which class super is going to try to initialize first. Even if we did, we need a way to pass the "extra" arguments so that subsequent calls to super, on other subclasses, receive the right arguments. Specifically, if the first call to super passes the name and email arguments to Contact.init, and Contact.init then calls super, it needs to be able to pass the address-related arguments to the "next" method, which is AddressHolder.init.
This is a problem whenever we want to call superclass methods with the same name, but with different sets of arguments. Most often, the only time you would want to call a superclass with a completely different set of arguments is in init, as we're doing here. Even with regular methods, though, we may want to add optional parameters that only make sense to one subclass or set of subclasses.
Sadly, the only way to solve this problem is to plan for it from the beginning. We have to design our base class parameter lists to accept keyword arguments for any parameters that are not required by every subclass implementation. Finally, we must ensure the method freely accepts unexpected arguments and passes them on to its super call, in case they are necessary to later methods in the inheritance order.
Python's function parameter syntax provides all the tools we need to do this, but it makes the overall code look cumbersome. Have a look at the proper version of the Friend multiple inheritance code:
class Contact:
all_contacts = []
def __init__(self, name='', email='', **kwargs):
super().__init__(**kwargs)
self.name = name
self.email = email
self.all_contacts.append(self)
class AddressHolder:
def __init__(self, street='', city='', state='', code='', **kwargs):
super().__init__(**kwargs)
self.street = street
self.city = city
self.state = state
self.code = code
class Friend(Contact, AddressHolder):
def __init__(self, phone='', **kwargs):
super().__init__(**kwargs)
self.phone = phone
We've changed all arguments to keyword arguments by giving them an empty string as a default value. We've also ensured that a **kwargs parameter is included to capture any additional parameters that our particular method doesn't know what to do with. It passes these parameters up to the next class with the super call.
It is a fancy name describing a simple concept: different behaviors happen depending on which subclass is being used, without having to explicitly know what the subclass actually is. As an example, imagine a program that plays audio files. A media player might need to load an AudioFile object and then play it. We'd put a play() method on the object, which is responsible for decompressing or extracting the audio and routing it to the sound card and speakers. The act of playing an AudioFile could feasibly be as simple as:
audio_file.play()
We can use inheritance with polymorphism to simplify the design. Each type of file can be represented by a different subclass of AudioFile, for example, WavFile, MP3File. Each of these would have a play() method, but that method would be implemented differently for each file to ensure the correct extraction procedure is followed. The media player object would never need to know which subclass of AudioFile it is referring to; it just calls play() and polymorphically lets the object take care of the actual details of playing. Let's look at a quick skeleton showing how this might look:
class AudioFile:
def __init__(self, filename):
if not filename.endswith(self.ext):
raise Exception("Invalid file format")
self.filename = filename
class MP3File(AudioFile):
ext = "mp3"
def play(self):
print("playing {} as mp3".format(self.filename))
class WavFile(AudioFile):
ext = "wav"
def play(self):
print("playing {} as wav".format(self.filename))
class OggFile(AudioFile):
ext = "ogg"
def play(self):
print("playing {} as ogg".format(self.filename))
All audio files check to ensure that a valid extension was given upon initialization. But did you notice how the init method in the parent class is able to access the ext class variable from different subclasses? That's polymorphism at work. If the filename doesn't end with the correct name, it raises an exception (exceptions will be covered in detail in the next chapter). The fact that AudioFile doesn't actually store a reference to the ext variable doesn't stop it from being able to access it on the subclass.
In addition, each subclass of AudioFile implements play() in a different way (this example doesn't actually play the music; audio compression algorithms really deserve a separate book!). This is also polymorphism in action. The media player can use the exact same code to play a file, no matter what type it is; it doesn't care what subclass of AudioFile it is looking at. The details of decompressing the audio file are encapsulated.
While duck typing is useful, it is not always easy to tell in advance if a class is going to fulfill the protocol you require. Therefore, Python introduced the idea of abstract base classes. Abstract base classes, or ABCs, define a set of methods and properties that a class must implement in order to be considered a duck-type instance of that class. The class can extend the abstract base class itself in order to be used as an instance of that class, but it must supply all the appropriate methods.
In practice, it's rarely necessary to create new abstract base classes, but we may find occasions to implement instances of existing ABCs. We'll cover implementing ABCs first, and then briefly see how to create your own if you should ever need to.
Most of the abstract base classes that exist in the Python Standard Library live in the collections module. One of the simplest ones is the Container class. Let's inspect it in the Python interpreter to see what methods this class requires:
>>> from collections import Container
>>> Container.__abstractmethods__
frozenset(['__contains__'])
So, the Container class has exactly one abstract method that needs to be implemented, contains. You can issue help(Container.contains) to see what the function signature should look like:
Help on method __contains__ in module _abcoll:__contains__(self, x) unbound _abcoll.Container method
So, we see that contains needs to take a single argument. Unfortunately, the help file doesn't tell us much about what that argument should be, but it's pretty obvious from the name of the ABC and the single method it implements that this argument is the value the user is checking to see if the container holds.
This method is implemented by list, str, and dict to indicate whether or not a given value is in that data structure. However, we can also define a silly container that tells us whether a given value is in the set of odd integers:
class OddContainer:
def __contains__(self, x):
if not isinstance(x, int) or not x % 2:
return False
return True
Now, we can instantiate an OddContainer object and determine that, even though we did not extend Container, the class is a Container object:
>>> from collections import Container
>>> odd_container = OddContainer()
>>> isinstance(odd_container, Container)
True
>>> issubclass(OddContainer, Container)
True
And that is why duck typing is way more awesome than classical polymorphism. We can create is a relationships without the overhead of using inheritance (or worse, multiple inheritance).
It's not necessary to have an abstract base class to enable duck typing. However, imagine we were creating a media player with third-party plugins. It is advisable to create an abstract base class in this case to document what API the third-party plugins should provide. The abc module provides the tools you need to do this, but I'll warn you in advance, this requires some of Python's most arcane concepts:
import abc
class MediaLoader(metaclass=abc.ABCMeta):
@abc.abstractmethod
def play(self):
pass
@abc.abstractproperty
def ext(self):
pass
@classmethod
def __subclasshook__(cls, C):
if cls is MediaLoader:
attrs = set(dir(C))
if set(cls.__abstractmethods__) <= attrs:
return True
return NotImplemented
The first weird thing is the metaclass keyword argument that is passed into the class where you would normally see the list of parent classes. This is a rarely used construct from the mystic art of metaclass programming. We won't be covering metaclasses in this book, so all you need to know is that by assigning the ABCMeta metaclass, you are giving your class superpower (or at least superclass) abilities.
Next, we see the @abc.abstractmethod and @abc.abstractproperty constructs. These are Python decorators. For now, just know that by marking a method or property as being abstract, you are stating that any subclass of this class must implement that method or supply that property in order to be considered a proper member of the class.
See what happens if you implement subclasses that do or don't supply those properties:
>>> class Wav(MediaLoader):
... pass
...
>>> x = Wav()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't instantiate abstract class Wav with abstract methods ext, play
>>> class Ogg(MediaLoader):
... ext = '.ogg'
... def play(self):
... pass
...
>>> o = Ogg()
Since the Wav class fails to implement the abstract attributes, it is not possible to instantiate that class. The class is still a legal abstract class, but you'd have to subclass it to actually do anything. The Ogg class supplies both attributes, so it instantiates cleanly.
Going back to the MediaLoader ABC, let's dissect that subclasshook method. It is basically saying that any class that supplies concrete implementations of all the abstract attributes of this ABC should be considered a subclass of MediaLoader, even if it doesn't actually inherit from the MediaLoader class.
@classmethod
def __subclasshook__(cls, C):
if cls is MediaLoader:
attrs = set(dir(C))
if set(cls.__abstractmethods__) <= attrs:
return True
return NotImplemented
@classmethod
This decorator marks the method as a class method. It essentially says that the method can be called on a class instead of an instantiated object:
def __subclasshook__(cls, C):
This defines the subclasshook class method. This special method is called by the Python interpreter to answer the question, Is the class C a subclass of this class?
if cls is MediaLoader:
We check to see if the method was called specifically on this class, rather than, say a subclass of this class. This prevents, for example, the Wav class from being thought of as a parent class of the Ogg class:
attrs = set(dir(C))
All this line does is get the set of methods and properties that the class has, including any parent classes in its class hierarchy:
if set(cls.__abstractmethods__) <= attrs:
This line uses set notation to see whether the set of abstract methods in this class have been supplied in the candidate class. Note that it doesn't check to see whether the methods have been implemented, just if they are there. Thus, it's possible for a class to be a subclass and yet still be an abstract class itself.
return True
If all the abstract methods have been supplied, then the candidate class is a subclass of this class and we return True. The method can legally return one of the three values: True, False, or NotImplemented. True and False indicate that the class is or is not definitively a subclass of this class:
return NotImplemented
If any of the conditionals have not been met (that is, the class is not MediaLoader or not all abstract methods have been supplied), then return NotImplemented. This tells the Python machinery to use the default mechanism (does the candidate class explicitly extend this class?) for subclass detection.
In principle, an exception is just an object. The one thing they all have in common is that they inherit from a built-in class called BaseException. These exception objects become special when they are handled inside the program's flow of control. When an exception occurs, everything that was supposed to happen doesn't happen, unless it was supposed to happen when an exception occurred.
For example, any time Python encounters a line in your program that it can't understand, it bails with SyntaxError, which is a type of exception. Here's a common one:
>>> print "hello world"
File "<stdin>", line 1
print "hello world"
^
SyntaxError: invalid syntax
This print statement was a valid command in Python 2 and previous versions, but in Python 3, because print is now a function, we have to enclose the arguments in parenthesis. So, if we type the preceding command into a Python 3 interpreter, we get the SyntaxError.
In addition to SyntaxError, some other common exceptions,are shown in the following example:
>>> x = 5 / 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: int division or modulo by zero
>>> lst = [1,2,3]
>>> print(lst[3])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
>>> lst + 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate list (not "int") to list
>>> lst.add
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'add'
>>> d = {'a': 'hello'}
>>> d['b']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'b'
>>> print(this_is_not_a_var)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'this_is_not_a_var' is not defined
Sometimes these exceptions are indicators of something wrong in our program (in which case we would go to the indicated line number and fix it), but they also occur in legitimate situations. A ZeroDivisionError doesn't always mean we received an invalid input. It could also mean we have received a different input. The user may have entered a zero by mistake, or on purpose, or it may represent a legitimate value, such as an empty bank account or the age of a newborn child.
You may have noticed all the preceding built-in exceptions end with the name Error. In Python, the words error and exception are used almost interchangeably. Errors are sometimes considered more dire than exceptions, but they are dealt with in exactly the same way. Indeed, all the error classes in the preceding example have Exception (which extends BaseException) as their superclass.
class EvenOnly(list):
def append(self, integer):
if not isinstance(integer, int):
raise TypeError("Only integers can be added")
if integer % 2:
raise ValueError("Only even numbers can be added")
super().append(integer)
This class extends the list built-in. Objects in Python, and overrides the append method to check two conditions that ensure the item is an even integer. We first check if the input is an instance of the int type, and then use the modulus operator to ensure it is divisible by two. If either of the two conditions is not met, the raise keyword causes an exception to occur. The raise keyword is simply followed by the object being raised as an exception. In the preceding example, two objects are newly constructed from the built-in classes TypeError and ValueError.
>>> e = EvenOnly()
>>> e.append("a string")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "even_integers.py", line 7, in add
raise TypeError("Only integers can be added")
TypeError: Only integers can be added
>>> e.append(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "even_integers.py", line 9, in add
raise ValueError("Only even numbers can be added")
ValueError: Only even numbers can be added
>>> e.append(2)
Any lines that were supposed to run after the exception is raised are not executed, and unless the exception is dealt with, the program will exit with an error message. Take a look at this simple function:
def no_return():
print("I am about to raise an exception")
raise Exception("This is always raised")
print("This line will never execute")
return "I won't be returned"
If we execute this function, we see that the first print call is executed and then the exception is raised. The second print statement is never executed, and the return statement never executes either:
>>> no_return()
I am about to raise an exception
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "exception_quits.py", line 3, in no_return
raise Exception("This is always raised")
Exception: This is always raised
Furthermore, if we have a function that calls another function that raises an exception, nothing will be executed in the first function after the point where the second function was called. Raising an exception stops all execution right up through the function call stack until it is either handled or forces the interpreter to exit.
def call_exceptor():
print("call_exceptor starts here...")
no_return()
print("an exception was raised...")
print("...so these lines don't run")
When we call this function, we see that the first print statement executes, as well as the first line in the no_return function. But once the exception is raised, nothing else executes:
>>> call_exceptor()
call_exceptor starts here...
I am about to raise an exception
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "method_calls_excepting.py", line 9, in call_exceptor
no_return()
File "method_calls_excepting.py", line 3, in no_return
raise Exception("This is always raised")
Exception: This is always raised
We'll soon see that when the interpreter is not actually taking a shortcut and exiting immediately, we can react to and deal with the exception inside either method. Indeed, exceptions can be handled at any level after they are initially raised.
Look at the exception's output (called a traceback) from bottom to top, and notice how both methods are listed. Inside no_return, the exception is initially raised. Then, just above that, we see that inside call_exceptor, that pesky no_return function was called and the exception bubbled up to the calling method. From there, it went up one more level to the main interpreter, which, not knowing what else to do with it, gave up and printed a traceback.
Now let's look at the tail side of the exception coin. If we encounter an exception situation, how should our code react to or recover from it? We handle exceptions by wrapping any code that might throw one (whether it is exception code itself, or a call to any function or method that may have an exception raised inside it) inside a try...except clause. The most basic syntax looks like this:
try: no_return() except: print("I caught an exception") print("executed after the exception") If we run this simple script using our existing no_return function, which as we know very well, always throws an exception, we get this output:
I am about to raise an exception I caught an exception executed after the exception The no_return function happily informs us that it is about to raise an exception, but we fooled it and caught the exception. Once caught, we were able to clean up after ourselves (in this case, by outputting that we were handling the situation), and continue on our way, with no interference from that offensive function. The remainder of the code in the no_return function still went unexecuted, but the code that called the function was able to recover and continue.
Note the indentation around try and except. The try clause wraps any code that might throw an exception. The except clause is then back on the same indentation level as the try line. Any code to handle the exception is indented after the except clause. Then normal code resumes at the original indentation level.
The problem with the preceding code is that it will catch any type of exception. What if we were writing some code that could raise both a TypeError and a ZeroDivisionError? We might want to catch the ZeroDivisionError, but let the TypeError propagate to the console. Can you guess the syntax?
Here's a rather silly function that does just that:
def funny_division(divider): try: return 100 / divider except ZeroDivisionError: return "Zero is not a good idea!"
print(funny_division(0)) print(funny_division(50.0)) print(funny_division("hello")) The function is tested with print statements that show it behaving as expected:
Zero is not a good idea! 2.0 Traceback (most recent call last): File "catch_specific_exception.py", line 9, in print(funny_division("hello")) File "catch_specific_exception.py", line 3, in funny_division return 100 / anumber TypeError: unsupported operand type(s) for /: 'int' and 'str'. The first line of output shows that if we enter 0, we get properly mocked. If we call with a valid number (note that it's not an integer, but it's still a valid divisor), it operates correctly. Yet if we enter a string (you were wondering how to get a TypeError, weren't you?), it fails with an exception. If we had used an empty except clause that didn't specify a ZeroDivisionError, it would have accused us of dividing by zero when we sent it a string, which is not a proper behavior at all.
We can even catch two or more different exceptions and handle them with the same code. Here's an example that raises three different types of exception. It handles TypeError and ZeroDivisionError with the same exception handler, but it may also raise a ValueError if you supply the number 13:
def funny_division2(anumber): try: if anumber == 13: raise ValueError("13 is an unlucky number") return 100 / anumber except (ZeroDivisionError, TypeError): return "Enter a number other than zero"
for val in (0, "hello", 50.0, 13):
print("Testing {}:".format(val), end=" ")
print(funny_division2(val))
The for loop at the bottom loops over several test inputs and prints the results. If you're wondering about that end argument in the print statement, it just turns the default trailing newline into a space so that it's joined with the output from the next line. Here's a run of the program:
Testing 0: Enter a number other than zero Testing hello: Enter a number other than zero Testing 50.0: 2.0 Testing 13: Traceback (most recent call last): File "catch_multiple_exceptions.py", line 11, in print(funny_division2(val)) File "catch_multiple_exceptions.py", line 4, in funny_division2 raise ValueError("13 is an unlucky number") ValueError: 13 is an unlucky number The number 0 and the string are both caught by the except clause, and a suitable error message is printed. The exception from the number 13 is not caught because it is a ValueError, which was not included in the types of exceptions being handled. This is all well and good, but what if we want to catch different exceptions and do different things with them? Or maybe we want to do something with an exception and then allow it to continue to bubble up to the parent function, as if it had never been caught? We don't need any new syntax to deal with these cases. It's possible to stack except clauses, and only the first match will be executed. For the second question, the raise keyword, with no arguments, will reraise the last exception if we're already inside an exception handler. Observe in the following code:
def funny_division3(anumber): try: if anumber == 13: raise ValueError("13 is an unlucky number") return 100 / anumber except ZeroDivisionError: return "Enter a number other than zero" except TypeError: return "Enter a numerical value" except ValueError: print("No, No, not 13!") raise The last line reraises the ValueError, so after outputting No, No, not 13!, it will raise the exception again; we'll still get the original stack trace on the console.
If we stack exception clauses like we did in the preceding example, only the first matching clause will be run, even if more than one of them fits. How can more than one clause match? Remember that exceptions are objects, and can therefore be subclassed. As we'll see in the next section, most exceptions extend the Exception class (which is itself derived from BaseException). If we catch Exception before we catch TypeError, then only the Exception handler will be executed, because TypeError is an Exception by inheritance.
This can come in handy in cases where we want to handle some exceptions specifically, and then handle all remaining exceptions as a more general case. We can simply catch Exception after catching all the specific exceptions and handle the general case there.
Sometimes, when we catch an exception, we need a reference to the Exception object itself. This most often happens when we define our own exceptions with custom arguments, but can also be relevant with standard exceptions. Most exception classes accept a set of arguments in their constructor, and we might want to access those attributes in the exception handler. If we define our own exception class, we can even call custom methods on it when we catch it. The syntax for capturing an exception as a variable uses the as keyword:
try: raise ValueError("This is an argument") except ValueError as e: print("The exception arguments were", e.args) If we run this simple snippet, it prints out the string argument that we passed into ValueError upon initialization.
We've seen several variations on the syntax for handling exceptions, but we still don't know how to execute code regardless of whether or not an exception has occurred. We also can't specify code that should be executed only if an exception does not occur. Two more keywords, finally and else, can provide the missing pieces. Neither one takes any extra arguments. The following example randomly picks an exception to throw and raises it. Then some not-so-complicated exception handling code is run that illustrates the newly introduced syntax:
import random some_exceptions = [ValueError, TypeError, IndexError, None]
try: choice = random.choice(some_exceptions) print("raising {}".format(choice)) if choice: raise choice("An error") except ValueError: print("Caught a ValueError") except TypeError: print("Caught a TypeError") except Exception as e: print("Caught some other error: %s" % ( e.class.name)) else: print("This code called if there is no exception") finally: print("This cleanup code is always called") If we run this example—which illustrates almost every conceivable exception handling scenario—a few times, we'll get different output each time, depending on which exception random chooses. Here are some example runs:
$ python finally_and_else.py raising None This code called if there is no exception This cleanup code is always called
$ python finally_and_else.py raising <class 'TypeError'> Caught a TypeError This cleanup code is always called
$ python finally_and_else.py raising <class 'IndexError'> Caught some other error: IndexError This cleanup code is always called
$ python finally_and_else.py raising <class 'ValueError'> Caught a ValueError This cleanup code is always called Note how the print statement in the finally clause is executed no matter what happens. This is extremely useful when we need to perform certain tasks after our code has finished running (even if an exception has occurred). Some common examples include:
Cleaning up an open database connection Closing an open file Sending a closing handshake over the network The finally clause is also very important when we execute a return statement from inside a try clause. The finally handle will still be executed before the value is returned.
Also, pay attention to the output when no exception is raised: both the else and the finally clauses are executed. The else clause may seem redundant, as the code that should be executed only when no exception is raised could just be placed after the entire try...except block. The difference is that the else block will still be executed if an exception is caught and handled. We'll see more on this when we discuss using exceptions as flow control later.
Any of the except, else, and finally clauses can be omitted after a try block (although else by itself is invalid). If you include more than one, the except clauses must come first, then the else clause, with the finally clause at the end. The order of the except clauses normally goes from most specific to most generic.
We've already seen several of the most common built-in exceptions, and you'll probably encounter the rest over the course of your regular Python development. As we noticed earlier, most exceptions are subclasses of the Exception class. But this is not true of all exceptions. Exception itself actually inherits from a class called BaseException. In fact, all exceptions must extend the BaseException class or one of its subclasses.
There are two key exceptions, SystemExit and KeyboardInterrupt, that derive directly from BaseException instead of Exception. The SystemExit exception is raised whenever the program exits naturally, typically because we called the sys.exit function somewhere in our code (for example, when the user selected an exit menu item, clicked the "close" button on a window, or entered a command to shut down a server). The exception is designed to allow us to clean up code before the program ultimately exits, so we generally don't need to handle it explicitly (because cleanup code happens inside a finally clause).
If we do handle it, we would normally reraise the exception, since catching it would stop the program from exiting. There are, of course, situations where we might want to stop the program exiting, for example, if there are unsaved changes and we want to prompt the user if they really want to exit. Usually, if we handle SystemExit at all, it's because we want to do something special with it, or are anticipating it directly. We especially don't want it to be accidentally caught in generic clauses that catch all normal exceptions. This is why it derives directly from BaseException.
The KeyboardInterrupt exception is common in command-line programs. It is thrown when the user explicitly interrupts program execution with an OS-dependent key combination (normally, Ctrl + C). This is a standard way for the user to deliberately interrupt a running program, and like SystemExit, it should almost always respond by terminating the program. Also, like SystemExit, it should handle any cleanup tasks inside finally blocks.
Here is a class diagram that fully illustrates the exception hierarchy:
The exception hierarchy When we use the except: clause without specifying any type of exception, it will catch all subclasses of BaseException; which is to say, it will catch all exceptions, including the two special ones. Since we almost always want these to get special treatment, it is unwise to use the except: statement without arguments. If you want to catch all exceptions other than SystemExit and KeyboardInterrupt, explicitly catch Exception.
Furthermore, if you do want to catch all exceptions, I suggest using the syntax except BaseException: instead of a raw except:. This helps explicitly tell future readers of your code that you are intentionally handling the special case exceptions.
Often, when we want to raise an exception, we find that none of the built-in exceptions are suitable. Luckily, it's trivial to define new exceptions of our own. The name of the class is usually designed to communicate what went wrong, and we can provide arbitrary arguments in the initializer to include additional information.
All we have to do is inherit from the Exception class. We don't even have to add any content to the class! We can, of course, extend BaseException directly, but then it will not be caught by generic except Exception clauses.
Here's a simple exception we might use in a banking application:
class InvalidWithdrawal(Exception): pass
raise InvalidWithdrawal("You don't have $50 in your account") The last line illustrates how to raise the newly defined exception. We are able to pass an arbitrary number of arguments into the exception. Often a string message is used, but any object that might be useful in a later exception handler can be stored. The Exception.init method is designed to accept any arguments and store them as a tuple in an attribute named args. This makes exceptions easier to define without needing to override init.
Of course, if we do want to customize the initializer, we are free to do so. Here's an exception whose initializer accepts the current balance and the amount the user wanted to withdraw. In addition, it adds a method to calculate how overdrawn the request was:
class InvalidWithdrawal(Exception): def init(self, balance, amount): super().init("account doesn't have ${}".format( amount)) self.amount = amount self.balance = balance
def overage(self):
return self.amount - self.balance
raise InvalidWithdrawal(25, 50) The raise statement at the end illustrates how to construct this exception. As you can see, we can do anything with an exception that we would do with other objects. We could catch an exception and pass it around as a working object, although it is more common to include a reference to the working object as an attribute on an exception and pass that around instead.
Here's how we would handle an InvalidWithdrawal exception if one was raised:
try: raise InvalidWithdrawal(25, 50) except InvalidWithdrawal as e: print("I'm sorry, but your withdrawal is " "more than your balance by " "${}".format(e.overage())) Here we see a valid use of the as keyword. By convention, most Python coders name the exception variable e, although, as usual, you are free to call it ex, exception, or aunt_sally if you prefer.
There are many reasons for defining our own exceptions. It is often useful to add information to the exception or log it in some way. But the utility of custom exceptions truly comes to light when creating a framework, library, or API that is intended for access by other programmers. In that case, be careful to ensure your code is raising exceptions that make sense to the client programmer. They should be easy to handle and clearly describe what went on. The client programmer should easily see how to fix the error (if it reflects a bug in their code) or handle the exception (if it's a situation they need to be made aware of).
Exceptions aren't exceptional. Novice programmers tend to think of exceptions as only useful for exceptional circumstances. However, the definition of exceptional circumstances can be vague and subject to interpretation. Consider the following two functions:
def divide_with_exception(number, divisor): try: print("{} / {} = {}".format( number, divisor, number / divisor * 1.0)) except ZeroDivisionError: print("You can't divide by zero")
def divide_with_if(number, divisor): if divisor == 0: print("You can't divide by zero") else: print("{} / {} = {}".format( number, divisor, number / divisor * 1.0))
These two functions behave identically. If divisor is zero, an error message is printed; otherwise, a message printing the result of division is displayed. We could avoid a ZeroDivisionError ever being thrown by testing for it with an if statement. Similarly, we can avoid an IndexError by explicitly checking whether or not the parameter is within the confines of the list, and a KeyError by checking if the key is in a dictionary.
But we shouldn't do this. For one thing, we might write an if statement that checks whether or not the index is lower than the parameters of the list, but forget to check negative values.
Eventually, we would discover this and have to find all the places where we were checking code. But if we had simply caught the IndexError and handled it, our code would just work.
Python programmers tend to follow a model of Ask forgiveness rather than permission, which is to say, they execute code and then deal with anything that goes wrong. The alternative, to look before you leap, is generally frowned upon. There are a few reasons for this, but the main one is that it shouldn't be necessary to burn CPU cycles looking for an unusual situation that is not going to arise in the normal path through the code. Therefore, it is wise to use exceptions for exceptional circumstances, even if those circumstances are only a little bit exceptional. Taking this argument further, we can actually see that the exception syntax is also effective for flow control. Like an if statement, exceptions can be used for decision making, branching, and message passing.
Imagine an inventory application for a company that sells widgets and gadgets. When a customer makes a purchase, the item can either be available, in which case the item is removed from inventory and the number of items left is returned, or it might be out of stock. Now, being out of stock is a perfectly normal thing to happen in an inventory application. It is certainly not an exceptional circumstance. But what do we return if it's out of stock? A string saying out of stock? A negative number? In both cases, the calling method would have to check whether the return value is a positive integer or something else, to determine if it is out of stock. That seems a bit messy. Instead, we can raise OutOfStockException and use the try statement to direct program flow control. Make sense? In addition, we want to make sure we don't sell the same item to two different customers, or sell an item that isn't in stock yet. One way to facilitate this is to lock each type of item to ensure only one person can update it at a time. The user must lock the item, manipulate the item (purchase, add stock, count items left…), and then unlock the item. Here's an incomplete Inventory example with docstrings that describes what some of the methods should do:
class Inventory: def lock(self, item_type): '''Select the type of item that is going to be manipulated. This method will lock the item so nobody else can manipulate the inventory until it's returned. This prevents selling the same item to two different customers.''' pass
def unlock(self, item_type):
'''Release the given type so that other
customers can access it.'''
pass
def purchase(self, item_type):
'''If the item is not locked, raise an
exception. If the item_type does not exist,
raise an exception. If the item is currently
out of stock, raise an exception. If the item
is available, subtract one item and return
the number of items left.'''
pass
We could hand this object prototype to a developer and have them implement the methods to do exactly as they say while we work on the code that needs to make a purchase. We'll use Python's robust exception handling to consider different branches, depending on how the purchase was made:
item_type = 'widget' inv = Inventory() inv.lock(item_type) try: num_left = inv.purchase(item_type) except InvalidItemType: print("Sorry, we don't sell {}".format(item_type)) except OutOfStock: print("Sorry, that item is out of stock.") else: print("Purchase complete. There are " "{} {}s left".format(num_left, item_type)) finally: inv.unlock(item_type) Pay attention to how all the possible exception handling clauses are used to ensure the correct actions happen at the correct time. Even though OutOfStock is not a terribly exceptional circumstance, we are able to use an exception to handle it suitably. This same code could be written with an if...elif...else structure, but it wouldn't be as easy to read or maintain.
We can also use exceptions to pass messages between different methods. For example, if we wanted to inform the customer as to what date the item is expected to be in stock again, we could ensure our OutOfStock object requires a back_in_stock parameter when it is constructed. Then, when we handle the exception, we can check that value and provide additional information to the customer. The information attached to the object can be easily passed between two different parts of the program. The exception could even provide a method that instructs the inventory object to reorder or backorder an item.
Using exceptions for flow control can make for some handy program designs. The important thing to take from this discussion is that exceptions are not a bad thing that we should try to avoid. Having an exception occur does not mean that you should have prevented this exceptional circumstance from happening. Rather, it is just a powerful way to communicate information between two sections of code that may not be directly calling each other.
An object, however, has both data and behavior. There is no reason to add an extra level of abstraction if it doesn't help organize our code. On the other hand, the "obvious" need is not always self-evident.
We can often start our Python programs by storing data in a few variables. As the program expands, we will later find that we are passing the same set of related variables to a set of functions. This is the time to think about grouping both variables and functions into a class. If we are designing a program to model polygons in two-dimensional space, we might start with each polygon being represented as a list of points. The points would be modeled as two-tuples (x, y) describing where that point is located. This is all data, stored in a set of nested data structures (specifically, a list of tuples):
square = [(1,1), (1,2), (2,2), (2,1)]
Now, if we want to calculate the distance around the perimeter of the polygon, we simply need to sum the distances between the two points. To do this, we also need a function to calculate the distance between two points. Here are two such functions:
import math
def distance(p1, p2):
return math.sqrt((p1[0]-p2[0])**2 + (p1[1]-p2[1])**2)
def perimeter(polygon):
perimeter = 0
points = polygon + [polygon[0]]
for i in range(len(polygon)):
perimeter += distance(points[i], points[i+1])
return perimeter
Now, as object-oriented programmers, we clearly recognize that a polygon class could encapsulate the list of points (data) and the perimeter function (behavior). Further, a point class. Objects in Python, might encapsulate the x and y coordinates and the distance method. The question is: is it valuable to do this?
For the previous code, maybe yes, maybe no. With our recent experience in object-oriented principles, we can write an object-oriented version in record time. Let's compare them
import math
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def distance(self, p2):
return math.sqrt((self.x-p2.x)**2 + (self.y-p2.y)**2)
class Polygon:
def __init__(self):
self.vertices = []
def add_point(self, point):
self.vertices.append((point))
def perimeter(self):
perimeter = 0
points = self.vertices + [self.vertices[0]]
for i in range(len(self.vertices)):
perimeter += points[i].distance(points[i+1])
return perimeter
As we can see from the highlighted sections, there is twice as much code here as there was in our earlier version, although we could argue that the add_point method is not strictly necessary.
Now, to understand the differences a little better, let's compare the two APIs in use. Here's how to calculate the perimeter of a square using the object-oriented code:
>>> square = Polygon()
>>> square.add_point(Point(1,1))
>>> square.add_point(Point(1,2))
>>> square.add_point(Point(2,2))
>>> square.add_point(Point(2,1))
>>> square.perimeter()
4.0
That's fairly succinct and easy to read, you might think, but let's compare it to the function-based code:
The object-oriented code is relatively self-documenting, we just have to look at the list of methods and their parameters to know what the object does and how to use it. By the time we wrote all the documentation for the functional version, it would probably be longer than the object-oriented code.
We can make the object-oriented Polygon API as easy to use as the functional implementation. All we have to do is alter our Polygon class so that it can be constructed with multiple points. Let's give it an initializer that accepts a list of Point objects. In fact, let's allow it to accept tuples too, and we can construct the Point objects ourselves, if needed:
def __init__(self, points=None):
points = points if points else []
self.vertices = []
for point in points:
if isinstance(point, tuple):
point = Point(*point)
self.vertices.append(point)
This initializer goes through the list and ensures that any tuples are converted to points. If the object is not a tuple, we leave it as is, assuming that it is either a Point object already, or an unknown duck-typed object that can act like a Point object.
The distinction is a design decision, but in general, the more complicated a set of data is, the more likely it is to have multiple functions specific to that data, and the more useful it is to use a class with attributes and methods instead.
So why would anyone insist upon the method-based syntax? Their reasoning is that someday we may want to add extra code when a value is set or retrieved. For example, we could decide to cache a value and return the cached value, or we might want to validate that the value is a suitable input.
In code, we could decide to change the set_name() method as follows:
def set_name(self, name):
if not name:
raise Exception("Invalid Name")
self._name = name
Python gives us the property keyword to make methods look like attributes. We can therefore write our code to use direct member access, and if we unexpectedly need to alter the implementation to do some calculation when getting or setting that attribute's value, we can do so without changing the interface. Let's see how it looks:
class Color:
def __init__(self, rgb_value, name):
self.rgb_value = rgb_value
self._name = name
def _set_name(self, name):
if not name:
raise Exception("Invalid Name")
self._name = name
def _get_name(self):
return self._name
name = property(_get_name, _set_name)
We first change the name attribute into a (semi-) private _name attribute. Then we add two more (semi-) private methods to get and set that variable, doing our validation when we set it.
It creates a new attribute on the Color class called name, which now replaces the previous name attribute. It sets this attribute to be a property, which calls the two methods we just created whenever the property is accessed or changed. This new version of the Color class can be used exactly the same way as the previous version, yet it now does validation when we set the name attribute:
>>> c = Color("#0000ff", "bright red")
>>> print(c.name)
bright red
>>> c.name = "red"
>>> print(c.name)
red
>>> c.name = ""
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "setting_name_property.py", line 8, in _set_name
raise Exception("Invalid Name")
Exception: Invalid Name
Bear in mind that even with the name property, the previous code is not 100 percent safe. People can still access the _name attribute directly and set it to an empty string if they want to. But if they access a variable we've explicitly marked with an underscore to suggest it is private, they're the ones that have to deal with the consequences, not us.
Properties in detail Think of the property function as returning an object that proxies any requests to set or access the attribute value through the methods we have specified. The property keyword is like a constructor for such an object, and that object is set as the public facing member for the given attribute.
This property constructor can actually accept two additional arguments, a deletion function and a docstring for the property. The delete function is rarely supplied in practice, but it can be useful for logging that a value has been deleted, or possibly to veto deleting if we have reason to do so. The docstring is just a string describing what the property does, no different from the docstrings. If we do not supply this parameter, the docstring will instead be copied from the docstring for the first argument: the getter method. Here is a silly example that simply states whenever any of the methods are called:
class Silly:
def _get_silly(self):
print("You are getting silly")
return self._silly
def _set_silly(self, value):
print("You are making silly {}".format(value))
self._silly = value
def _del_silly(self):
print("Whoah, you killed silly!")
del self._silly
silly = property(_get_silly, _set_silly,
_del_silly, "This is a silly property")
If we actually use this class, it does indeed print out the correct strings when we ask it to:
>>> s = Silly()
>>> s.silly = "funny"
You are making silly funny
>>> s.silly
You are getting silly
'funny'
>>> del s.silly
Whoah, you killed silly!
Further, if we look at the help file for the Silly class (by issuing help(silly) at the interpreter prompt), it shows us the custom docstring for our silly attribute:
Help on class Silly in module __main__:
class Silly(builtins.object)
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| silly
| This is a silly property
Decorators – another way to create properties
The property function can be used with the decorator syntax to turn a get function into a property:
class Foo:
@property
def foo(self):
return "bar"
This applies the property function as a decorator, and is equivalent to the previous foo = property(foo) syntax. The main difference, from a readability perspective, is that we get to mark the foo function as a property at the top of the method, instead of after it is defined, where it can be easily overlooked. It also means we don't have to create private methods with underscore prefixes just to define a property.
Going one step further, we can specify a setter function for the new property as follows:
class Foo:
@property
def foo(self):
return self._foo
@foo.setter
def foo(self, value):
self._foo = value
This syntax looks pretty odd, although the intent is obvious. First, we decorate the foo method as a getter. Then, we decorate a second method with exactly the same name by applying the setter attribute of the originally decorated foo method! The property function returns an object; this object always comes with its own setter attribute, which can then be applied as a decorator to other functions. Using the same name for the get and set methods is not required, but it does help group the multiple methods that access one property together.
We can also specify a deletion function with @foo.deleter. We cannot specify a docstring using property decorators, so we need to rely on the property copying the docstring from the initial getter method.
Here's our previous Silly class rewritten to use property as a decorator:
class Silly:
@property
def silly(self):
"This is a silly property"
print("You are getting silly")
return self._silly
@silly.setter
def silly(self, value):
print("You are making silly {}".format(value))
self._silly = value
@silly.deleter
def silly(self):
print("Whoah, you killed silly!")
del self._silly
This class operates exactly the same as our earlier version, including the help text. You can use whichever syntax you feel is more readable and elegant.
Deciding when to use properties
With the property built-in clouding the division between behavior and data, it can be confusing to know which one to choose. The example use case we saw earlier is one of the most common uses of properties; we have some data on a class that we later want to add behavior to. There are also other factors to take into account when deciding to use a property.
Technically, in Python, data, properties, and methods are all attributes on a class. The fact that a method is callable does not distinguish it from other types of attributes; indeed, we'll see in Chapter 7, Python Object-oriented Shortcuts, that it is possible to create normal objects that can be called like functions. We'll also discover that functions and methods are themselves normal objects.
The fact that methods are just callable attributes, and properties are just customizable attributes can help us make this decision. Methods should typically represent actions; things that can be done to, or performed by, the object. When you call a method, even with only one argument, it should do something. Method names are generally verbs.
Once confirming that an attribute is not an action, we need to decide between standard data attributes and properties. In general, always use a standard attribute until you need to control access to that property in some way. In either case, your attribute is usually a noun. The only difference between an attribute and a property is that we can invoke custom actions automatically when a property is retrieved, set, or deleted.
from urllib.request import urlopen
class WebPage:
def __init__(self, url):
self.url = url
self._content = None
@property
def content(self):
if not self._content:
print("Retrieving New Page...")
self._content = urlopen(self.url).read()
return self._content
We can test this code to see that the page is only retrieved once:
>>> import time
>>> webpage = WebPage("http://ccphillips.net/")
>>> now = time.time()
>>> content1 = webpage.content
Retrieving New Page...
>>> time.time() - now
22.43316888809204
>>> now = time.time()
>>> content2 = webpage.content
>>> time.time() - now
1.9266459941864014
>>> content2 == content1
True
I was on an awful satellite connection when I originally tested this code and it took 20 seconds the first time I loaded the content. The second time, I got the result in 2 seconds (which is really just the amount of time it took to type the lines into the interpreter).
Custom getters are also useful for attributes that need to be calculated on the fly, based on other object attributes. For example, we might want to calculate the average for a list of integers:
class AverageList(list): @property def average(self): return sum(self) / len(self) This very simple class inherits from list, so we get list-like behavior for free. We just add a property to the class, and presto, our list can have an average:
a = AverageList([1,2,3,4]) a.average 2.5 Of course, we could have made this a method instead, but then we should call it calculate_average(), since methods represent actions. But a property called average is more suitable, both easier to type, and easier to read.
Custom setters are useful for validation, as we've already seen, but they can also be used to proxy a value to another location. For example, we could add a content setter to the WebPage class that automatically logs into our web server and uploads a new page whenever the value is set.
We've been focused on objects and their attributes and methods. Now, we'll take a look at designing higher-level objects: the kinds of objects that manage other objects. The objects that tie everything together.
The difference between these objects and most of the examples we've seen so far is that our examples tend to represent concrete ideas. Management objects are more like office managers; they don't do the actual "visible" work out on the floor, but without them, there would be no communication between departments and nobody would know what they are supposed to do (although, this can be true anyway if the organization is badly managed!). Analogously, the attributes on a management class tend to refer to other objects that do the "visible" work; the behaviors on such a class delegate to those other classes at the right time, and pass messages between them.
As an example, we'll write a program that does a find and replace action for text files stored in a compressed ZIP file. We'll need objects to represent the ZIP file and each individual text file (luckily, we don't have to write these classes, they're available in the Python standard library). The manager object will be responsible for ensuring three steps occur in order:
Unzipping the compressed file. Performing the find and replace action. Zipping up the new files. The class is initialized with the .zip filename and search and replace strings. We create a temporary directory to store the unzipped files in, so that the folder stays clean. The Python 3.4 pathlib library helps out with file and directory manipulation. We'll learn more about that in Chapter 8, Strings and Serialization, but the interface should be pretty clear in the following example:
import sys
import shutil
import zipfile
from pathlib import Path
class ZipReplace:
def __init__(self, filename, search_string, replace_string):
self.filename = filename
self.search_string = search_string
self.replace_string = replace_string
self.temp_directory = Path("unzipped-{}".format(
filename))
Then, we create an overall "manager" method for each of the three steps. This method delegates responsibility to other methods. Obviously, we could do all three steps in one method, or indeed, in one script without ever creating an object. There are several advantages to separating the three steps:
Readability: The code for each step is in a self-contained unit that is easy to read and understand. The method names describe what the method does, and less additional documentation is required to understand what is going on. Extensibility: If a subclass wanted to use compressed TAR files instead of ZIP files, it could override the zip and unzip methods without having to duplicate the find_replace method. Partitioning: An external class could create an instance of this class and call the find_replace method directly on some folder without having to zip the content. The delegation method is the first in the following code; the rest of the methods are included for completeness:
def zip_find_replace(self):
self.unzip_files()
self.find_replace()
self.zip_files()
def unzip_files(self):
self.temp_directory.mkdir()
with zipfile.ZipFile(self.filename) as zip:
zip.extractall(str(self.temp_directory))
def find_replace(self):
for filename in self.temp_directory.iterdir():
with filename.open() as file:
contents = file.read()
contents = contents.replace(
self.search_string, self.replace_string)
with filename.open("w") as file:
file.write(contents)
def zip_files(self):
with zipfile.ZipFile(self.filename, 'w') as file:
for filename in self.temp_directory.iterdir():
file.write(str(filename), filename.name)
shutil.rmtree(str(self.temp_directory))
if __name__ == "__main__":
ZipReplace(*sys.argv[1:4]).zip_find_replace()
For brevity, the code for zipping and unzipping files is sparsely documented. Our current focus is on object-oriented design; if you are interested in the inner details of the zipfile module, refer to the documentation in the standard library, either online or by typing import zipfile ; help(zipfile) into your interactive interpreter. Note that this example only searches the top-level files in a ZIP file; if there are any folders in the unzipped content, they will not be scanned, nor will any files inside those folders.
The last two lines in the example allow us to run the program from the command line by passing the zip filename, search string, and replace string as arguments:
python zipsearch.py hello.zip hello hi Of course, this object does not have to be created from the command line; it could be imported from another module (to perform batch ZIP file processing) or accessed as part of a GUI interface or even a higher-level management object that knows where to get ZIP files (for example, to retrieve them from an FTP server or back them up to an external disk).
As programs become more and more complex, the objects being modeled become less and less like physical objects. Properties are other abstract objects and methods are actions that change the state of those abstract objects. But at the heart of every object, no matter how complex, is a set of concrete properties and well-defined behaviors.
Removing duplicate code Often the code in management style classes such as ZipReplace is quite generic and can be applied in a variety of ways. It is possible to use either composition or inheritance to help keep this code in one place, thus eliminating duplicate code. Before we look at any examples of this, let's discuss a tiny bit of theory. Specifically, why is duplicate code a bad thing?
There are several reasons, but they all boil down to readability and maintainability. When we're writing a new piece of code that is similar to an earlier piece, the easiest thing to do is copy the old code and change whatever needs to be changed (variable names, logic, comments) to make it work in the new location. Alternatively, if we're writing new code that seems similar, but not identical to code elsewhere in the project, it is often easier to write fresh code with similar behavior, rather than figure out how to extract the overlapping functionality.
But as soon as someone has to read and understand the code and they come across duplicate blocks, they are faced with a dilemma. Code that might have made sense suddenly has to be understood. How is one section different from the other? How are they the same? Under what conditions is one section called? When do we call the other? You might argue that you're the only one reading your code, but if you don't touch that code for eight months it will be as incomprehensible to you as it is to a fresh coder. When we're trying to read two similar pieces of code, we have to understand why they're different, as well as how they're different. This wastes the reader's time; code should always be written to be readable first.
Reading such duplicate code can be tiresome, but code maintenance is even more tormenting. As the preceding story suggests, keeping two similar pieces of code up to date can be a nightmare. We have to remember to update both sections whenever we update one of them, and we have to remember how the multiple sections differ so we can modify our changes when we are editing each of them. If we forget to update both sections, we will end up with extremely annoying bugs that usually manifest themselves as, "but I fixed that already, why is it still happening?"
The result is that people who are reading or maintaining our code have to spend astronomical amounts of time understanding and testing it compared to if we had written the code in a nonrepetitive manner in the first place. It's even more frustrating when we are the ones doing the maintenance; we find ourselves saying, "why didn't I do this right the first time?" The time we save by copy-pasting existing code is lost the very first time we have to maintain it. Code is both read and modified many more times and much more often than it is written. Comprehensible code should always be paramount.
This is why programmers, especially Python programmers (who tend to value elegant code more than average), follow what is known as the Don't Repeat Yourself (DRY) principle. DRY code is maintainable code. My advice to beginning programmers is to never use the copy and paste feature of their editor. To intermediate programmers, I suggest they think thrice before they hit Ctrl + C.
But what should we do instead of code duplication? The simplest solution is often to move the code into a function that accepts parameters to account for whatever parts are different. This isn't a terribly object-oriented solution, but it is frequently optimal.
For example, if we have two pieces of code that unzip a ZIP file into two different directories, we can easily write a function that accepts a parameter for the directory to which it should be unzipped instead. This may make the function itself slightly more difficult to read, but a good function name and docstring can easily make up for that, and any code that invokes the function will be easier to read.
That's certainly enough theory! The moral of the story is: always make the effort to refactor your code to be easier to read instead of writing bad code that is only easier to write.
In practice Let's explore two ways we can reuse existing code. After writing our code to replace strings in a ZIP file full of text files, we are later contracted to scale all the images in a ZIP file to 640 x 480. Looks like we could use a very similar paradigm to what we used in ZipReplace. The first impulse might be to save a copy of that file and change the find_replace method to scale_image or something similar.
But, that's uncool. What if someday we want to change the unzip and zip methods to also open TAR files? Or maybe we want to use a guaranteed unique directory name for temporary files. In either case, we'd have to change it in two different places!
We'll start by demonstrating an inheritance-based solution to this problem. First we'll modify our original ZipReplace class into a superclass for processing generic ZIP files:
import os
import shutil
import zipfile
from pathlib import Path
class ZipProcessor:
def __init__(self, zipname):
self.zipname = zipname
self.temp_directory = Path("unzipped-{}".format(
zipname[:-4]))
def process_zip(self):
self.unzip_files()
self.process_files()
self.zip_files()
def unzip_files(self):
self.temp_directory.mkdir()
with zipfile.ZipFile(self.zipname) as zip:
zip.extractall(str(self.temp_directory))
def zip_files(self):
with zipfile.ZipFile(self.zipname, 'w') as file:
for filename in self.temp_directory.iterdir():
file.write(str(filename), filename.name)
shutil.rmtree(str(self.temp_directory))
We changed the filename property to zipname to avoid confusion with the filename local variables inside the various methods. This helps make the code more readable even though it isn't actually a change in design.
We also dropped the two parameters to init (search_string and replace_string) that were specific to ZipReplace. Then we renamed the zip_find_replace method to process_zip and made it call an (as yet undefined) process_files method instead of find_replace; these name changes help demonstrate the more generalized nature of our new class. Notice that we have removed the find_replace method altogether; that code is specific to ZipReplace and has no business here.
This new ZipProcessor class doesn't actually define a process_files method; so if we ran it directly, it would raise an exception. Because it isn't meant to run directly, we removed the main call at the bottom of the original script.
Now, before we move on to our image processing app, let's fix up our original zipsearch class to make use of this parent class:
from zip_processor import ZipProcessor
import sys
import os
class ZipReplace(ZipProcessor):
def __init__(self, filename, search_string,
replace_string):
super().__init__(filename)
self.search_string = search_string
self.replace_string = replace_string
def process_files(self):
'''perform a search and replace on all files in the
temporary directory'''
for filename in self.temp_directory.iterdir():
with filename.open() as file:
contents = file.read()
contents = contents.replace(
self.search_string, self.replace_string)
with filename.open("w") as file:
file.write(contents)
if __name__ == "__main__":
ZipReplace(*sys.argv[1:4]).process_zip()
This code is a bit shorter than the original version, since it inherits its ZIP processing abilities from the parent class. We first import the base class we just wrote and make ZipReplace extend that class. Then we use super() to initialize the parent class. The find_replace method is still here, but we renamed it to process_files so the parent class can call it from its management interface. Because this name isn't as descriptive as the old one, we added a docstring to describe what it is doing.
Now, that was quite a bit of work, considering that all we have now is a program that is functionally not different from the one we started with! But having done that work, it is now much easier for us to write other classes that operate on files in a ZIP archive, such as the (hypothetically requested) photo scaler. Further, if we ever want to improve or bug fix the zip functionality, we can do it for all classes by changing only the one ZipProcessor base class. Maintenance will be much more effective.
See how simple it is now to create a photo scaling class that takes advantage of the ZipProcessor functionality. (Note: this class requires the third-party pillow library to get the PIL module. You can install it with pip install pillow.)
from zip_processor import ZipProcessor import sys from PIL import Image
class ScaleZip(ZipProcessor):
def process_files(self):
'''Scale each image in the directory to 640x480'''
for filename in self.temp_directory.iterdir():
im = Image.open(str(filename))
scaled = im.resize((640, 480))
scaled.save(str(filename))
if name == "main": ScaleZip(*sys.argv[1:4]).process_zip() Look how simple this class is! All that work we did earlier paid off. All we do is open each file (assuming that it is an image; it will unceremoniously crash if a file cannot be opened), scale it, and save it back. The ZipProcessor class takes care of the zipping and unzipping without any extra work on our part.
Let's start with the most basic Python built-in, one that we've seen many times already, the one that we've extended in every class we have created: the object. Technically, we can instantiate an object without writing a subclass:
>>> o = object()
>>> o.x = 5
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'object' object has no attribute 'x'
Unfortunately, as you can see, it's not possible to set any attributes on an object that was instantiated directly. This isn't because the Python developers wanted to force us to write our own classes, or anything so sinister. They did this to save memory; a lot of memory. When Python allows an object to have arbitrary attributes, it takes a certain amount of system memory to keep track of what attributes each object has, for storing both the attribute name and its value. Even if no attributes are stored, memory is allocated for potential new attributes. Given the dozens, hundreds, or thousands of objects (every class extends object) in a typical Python program; this small amount of memory would quickly become a large amount of memory. So, Python disables arbitrary properties on object, and several other built-ins, by default
It is, however, trivial to create an empty object class of our own; we saw it in our earliest example:
class MyObject:
pass
And, as we've already seen, it's possible to set attributes on such classes:
>>> m = MyObject()
>>> m.x = "hello"
>>> m.x
'hello'
If we wanted to group properties together, we could store them in an empty object like this. But we are usually better off using other built-ins designed for storing data. It has been stressed throughout this book that classes and objects should only be used when you want to specify both data and behaviors. The main reason to write an empty class is to quickly block something out, knowing we'll come back later to add behavior. It is much easier to adapt behaviors to a class than it is to replace a data structure with an object and change all references to it. Therefore, it is important to decide from the outset if the data is just data, or if it is an object in disguise. Once that design decision is made, the rest of the design naturally falls into place.
Tuples are objects that can store a specific number of other objects in order. They are immutable, so we can't add, remove, or replace objects on the fly. This may seem like a massive restriction, but the truth is, if you need to modify a tuple, you're using the wrong data type (usually a list would be more suitable). The primary benefit of tuples' immutability is that we can use them as keys in dictionaries, and in other locations where an object requires a hash value.
Tuples are used to store data; behavior cannot be stored in a tuple. If we require behavior to manipulate a tuple, we have to pass the tuple into a function (or method on another object) that performs the action.
Tuples should generally store values that are somehow different from each other. For example, we would not put three stock symbols in a tuple, but we might create a tuple of stock symbol, current price, high, and low for the day. The primary purpose of a tuple is to aggregate different pieces of data together into one container. Thus, a tuple can be the easiest tool to replace the "object with no data" idiom.
We can create a tuple by separating the values with a comma. Usually, tuples are wrapped in parentheses to make them easy to read and to separate them from other parts of an expression, but this is not always mandatory. The following two assignments are identical (they record a stock, the current price, the high, and the low for a rather profitable company):
>>> stock = "FB", 75.00, 75.03, 74.90
>>> stock2 = ("FB", 75.00, 75.03, 74.90)
If we're grouping a tuple inside of some other object, such as a function call, list comprehension, or generator, the parentheses are required. Otherwise, it would be impossible for the interpreter to know whether it is a tuple or the next function parameter. For example, the following function accepts a tuple and a date, and returns a tuple of the date and the middle value between the stock's high and low value:
import datetime
def middle(stock, date):
symbol, current, high, low = stock
return (((high + low) / 2), date)
mid_value, date = middle(("FB", 75.00, 75.03, 74.90),
datetime.date(2014, 10, 31))
The tuple is created directly inside the function call by separating the values with commas and enclosing the entire tuple in parenthesis. This tuple is then followed by a comma to separate it from the second argument.
This example also illustrates tuple unpacking. The first line inside the function unpacks the stock parameter into four different variables. The tuple has to be exactly the same length as the number of variables, or it will raise an exception. We can also see an example of tuple unpacking on the last line, where the tuple returned inside the function is unpacked into two values, mid_value and date. Granted, this is a strange thing to do, since we supplied the date to the function in the first place, but it gave us a chance to see unpacking at work.
Unpacking is a very useful feature in Python. We can group variables together to make storing and passing them around simpler, but the moment we need to access all of them, we can unpack them into separate variables. Of course, sometimes we only need access to one of the variables in the tuple. We can use the same syntax that we use for other sequence types (lists and strings, for example) to access an individual value:
>>> stock = "FB", 75.00, 75.03, 74.90
>>> high = stock[2]
>>> high
75.03
We can even use slice notation to extract larger pieces of tuples:
>>> stock[1:3]
(75.00, 75.03)
These examples, while illustrating how flexible tuples can be, also demonstrate one of their major disadvantages: readability. How does someone reading this code know what is in the second position of a specific tuple? They can guess, from the name of the variable we assigned it to, that it is high of some sort, but if we had just accessed the tuple value in a calculation without assigning it, there would be no such indication. They would have to paw through the code to find where the tuple was declared before they could discover what it does.
Accessing tuple members directly is fine in some circumstances, but don't make a habit of it. Such so-called "magic numbers" (numbers that seem to come out of thin air with no apparent meaning within the code) are the source of many coding errors and lead to hours of frustrated debugging. Try to use tuples only when you know that all the values are going to be useful at once and it's normally going to be unpacked when it is accessed. If you have to access a member directly or using a slice and the purpose of that value is not immediately obvious, at least include a comment explaining where it came from.
Named tuples
So, what do we do when we want to group values together, but know we're frequently going to need to access them individually? Well, we could use an empty object, as discussed in the previous section (but that is rarely useful unless we anticipate adding behavior later), or we could use a dictionary (most useful if we don't know exactly how many or which specific data will be stored), as we'll cover in the next section.
If, however, we do not need to add behavior to the object, and we know in advance what attributes we need to store, we can use a named tuple. Named tuples are tuples with attitude. They are a great way to group read-only data together.
Constructing a named tuple takes a bit more work than a normal tuple. First, we have to import namedtuple, as it is not in the namespace by default. Then, we describe the named tuple by giving it a name and outlining its attributes. This returns a class-like object that we can instantiate with the required values as many times as we want:
from collections import namedtuple
Stock = namedtuple("Stock", "symbol current high low")
stock = Stock("FB", 75.00, high=75.03, low=74.90)
The namedtuple constructor accepts two arguments. The first is an identifier for the named tuple. The second is a string of space-separated attributes that the named tuple can have. The first attribute should be listed, followed by a space (or comma if you prefer), then the second attribute, then another space, and so on. The result is an object that can be called just like a normal class to instantiate other objects. The constructor must have exactly the right number of arguments that can be passed in as arguments or keyword arguments. As with normal objects, we can create as many instances of this "class" as we like, with different values for each.
The resulting namedtuple can then be packed, unpacked, and otherwise treated like a normal tuple, but we can also access individual attributes on it as if it were an object:
>>> stock.high
75.03
>>> symbol, current, high, low = stock
>>> current
75.00
Named tuples are perfect for many "data only" representations, but they are not ideal for all situations. Like tuples and strings, named tuples are immutable, so we cannot modify an attribute once it has been set. For example, the current value of my company's stock has gone down since we started this discussion, but we can't set the new value:
>>> stock.current = 74.98
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute
If we need to be able to change stored data, a dictionary may be what we need instead.
Dictionaries are incredibly useful containers that allow us to map objects directly to other objects. An empty object with attributes to it is a sort of dictionary; the names of the properties map to the property values. This is actually closer to the truth than it sounds; internally, objects normally represent attributes as a dictionary, where the values are properties or methods on the objects (see the dict attribute if you don't believe me). Even the attributes on a module are stored, internally, in a dictionary.
Dictionaries are extremely efficient at looking up a value, given a specific key object that maps to that value. They should always be used when you want to find one object based on some other object. The object that is being stored is called the value; the object that is being used as an index is called the key. We've already seen dictionary syntax in some of our previous examples.
Dictionaries can be created either using the dict() constructor or using the {} syntax shortcut. In practice, the latter format is almost always used. We can prepopulate a dictionary by separating the keys from the values using a colon, and separating the key value pairs using a comma.
For example, in a stock application, we would most often want to look up prices by the stock symbol. We can create a dictionary that uses stock symbols as keys, and tuples of current, high, and low as values like this:
stocks = {"GOOG": (613.30, 625.86, 610.50),
"MSFT": (30.25, 30.70, 30.19)}
As we've seen in previous examples, we can then look up values in the dictionary by requesting a key inside square brackets. If the key is not in the dictionary, it will raise an exception:
>>> stocks["GOOG"]
(613.3, 625.86, 610.5)
>>> stocks["RIM"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'RIM'
We can, of course, catch the KeyError and handle it. But we have other options. Remember, dictionaries are objects, even if their primary purpose is to hold other objects. As such, they have several behaviors associated with them. One of the most useful of these methods is the get method; it accepts a key as the first parameter and an optional default value if the key doesn't exist:
>>> print(stocks.get("RIM"))
None
>>> stocks.get("RIM", "NOT FOUND")
'NOT FOUND'
For even more control, we can use the setdefault method. If the key is in the dictionary, this method behaves just like get; it returns the value for that key. Otherwise, if the key is not in the dictionary, it will not only return the default value we supply in the method call (just like get does), it will also set the key to that same value. Another way to think of it is that setdefault sets a value in the dictionary only if that value has not previously been set. Then it returns the value in the dictionary, either the one that was already there, or the newly provided default value.
>>> stocks.setdefault("GOOG", "INVALID")
(613.3, 625.86, 610.5)
>>> stocks.setdefault("BBRY", (10.50, 10.62, 10.39))
(10.50, 10.62, 10.39)
>>> stocks["BBRY"]
(10.50, 10.62, 10.39)
The GOOG stock was already in the dictionary, so when we tried to setdefault it to an invalid value, it just returned the value already in the dictionary. BBRY was not in the dictionary, so setdefault returned the default value and set the new value in the dictionary for us. We then check that the new stock is, indeed, in the dictionary.
Three other very useful dictionary methods are keys(), values(), and items(). The first two return an iterator over all the keys and all the values in the dictionary. We can use these like lists or in for loops if we want to process all the keys or values. The items() method is probably the most useful; it returns an iterator over tuples of (key, value) pairs for every item in the dictionary. This works great with tuple unpacking in a for loop to loop over associated keys and values. This example does just that to print each stock in the dictionary with its current value:
>>> for stock, values in stocks.items():
... print("{} last value is {}".format(stock, values[0]))
...
GOOG last value is 613.3
BBRY last value is 10.50
MSFT last value is 30.25
Each key/value tuple is unpacked into two variables named stock and values (we could use any variable names we wanted, but these both seem appropriate) and then printed in a formatted string.
Notice that the stocks do not show up in the same order in which they were inserted. Dictionaries, due to the efficient algorithm (known as hashing) that is used to make key lookup so fast, are inherently unsorted.
So, there are numerous ways to retrieve data from a dictionary once it has been instantiated; we can use square brackets as index syntax, the get method, the setdefault method, or iterate over the items method, among others.
Finally, as you likely already know, we can set a value in a dictionary using the same indexing syntax we use to retrieve a value:
>>> stocks["GOOG"] = (597.63, 610.00, 596.28)
>>> stocks['GOOG']
(597.63, 610.0, 596.28)
Google's price is lower today, so I've updated the tuple value in the dictionary. We can use this index syntax to set a value for any key, regardless of whether the key is in the dictionary. If it is in the dictionary, the old value will be replaced with the new one; otherwise, a new key/value pair will be created.
We've been using strings as dictionary keys, so far, but we aren't limited to string keys. It is common to use strings as keys, especially when we're storing data in a dictionary to gather it together (instead of using an object with named properties). But we can also use tuples, numbers, or even objects we've defined ourselves as dictionary keys. We can even use different types of keys in a single dictionary:
random_keys = {}
random_keys["astring"] = "somestring"
random_keys[5] = "aninteger"
random_keys[25.2] = "floats work too"
random_keys[("abc", 123)] = "so do tuples"
class AnObject:
def __init__(self, avalue):
self.avalue = avalue
my_object = AnObject(14)
random_keys[my_object] = "We can even store objects"
my_object.avalue = 12
try:
random_keys[[1,2,3]] = "we can't store lists though"
except:
print("unable to store list\n")
for key, value in random_keys.items():
print("{} has value {}".format(key, value))
This code shows several different types of keys we can supply to a dictionary. It also shows one type of object that cannot be used. We've already used lists extensively, and we'll be seeing many more details of them in the next section. Because lists can change at any time (by adding or removing items, for example), they cannot hash to a specific value.
Objects that are hashable basically have a defined algorithm that converts the object into a unique integer value for rapid lookup. This hash is what is actually used to look up values in a dictionary. For example, strings map to integers based on the characters in the string, while tuples combine hashes of the items inside the tuple. Any two objects that are somehow considered equal (like strings with the same characters or tuples with the same values) should have the same hash value, and the hash value for an object should never ever change. Lists, however, can have their contents changed, which would change their hash value (two lists should only be equal if their contents are the same). Because of this, they can't be used as dictionary keys. For the same reason, dictionaries cannot be used as keys into other dictionaries.
In contrast, there are no limits on the types of objects that can be used as dictionary values. We can use a string key that maps to a list value, for example, or we can have a nested dictionary as a value in another dictionary.
Dictionary use cases
Dictionaries are extremely versatile and have numerous uses. There are two major ways that dictionaries can be used. The first is dictionaries where all the keys represent different instances of similar objects; for example, our stock dictionary. This is an indexing system. We use the stock symbol as an index to the values. The values could even have been complicated self-defined objects that made buy and sell decisions or set a stop-loss, rather than our simple tuples.
The second design is dictionaries where each key represents some aspect of a single structure; in this case, we'd probably use a separate dictionary for each object, and they'd all have similar (though often not identical) sets of keys. This latter situation can often also be solved with named tuples. These should typically be used when we know exactly what attributes the data must store, and we know that all pieces of the data must be supplied at once (when the item is constructed). But if we need to create or change dictionary keys over time or we don't know exactly what the keys might be, a dictionary is more suitable.
Using defaultdict
We've seen how to use setdefault to set a default value if a key doesn't exist, but this can get a bit monotonous if we need to set a default value every time we look up a value. For example, if we're writing code that counts the number of times a letter occurs in a given sentence, we could do this:
def letter_frequency(sentence):
frequencies = {}
for letter in sentence:
frequency = frequencies.setdefault(letter, 0)
frequencies[letter] = frequency + 1
return frequencies
Every time we access the dictionary, we need to check that it has a value already, and if not, set it to zero. When something like this needs to be done every time an empty key is requested, we can use a different version of the dictionary, called defaultdict:
from collections import defaultdict
def letter_frequency(sentence):
frequencies = defaultdict(int)
for letter in sentence:
frequencies[letter] += 1
return frequencies
This code looks like it couldn't possibly work. The defaultdict accepts a function in its constructor. Whenever a key is accessed that is not already in the dictionary, it calls that function, with no parameters, to create a default value.
In this case, the function it calls is int, which is the constructor for an integer object. Normally, integers are created simply by typing an integer number into our code, and if we do create one using the int constructor, we pass it the item we want to create (for example, to convert a string of digits into an integer). But if we call int without any arguments, it returns, conveniently, the number zero. In this code, if the letter doesn't exist in the defaultdict, the number zero is returned when we access it. Then we add one to this number to indicate we've found an instance of that letter, and the next time we find one, that number will be returned and we can increment the value again.
The defaultdict is useful for creating dictionaries of containers. If we want to create a dictionary of stock prices for the past 30 days, we could use a stock symbol as the key and store the prices in list; the first time we access the stock price, we would want it to create an empty list. Simply pass list into the defaultdict, and it will be called every time an empty key is accessed. We can do similar things with sets or even empty dictionaries if we want to associate one with a key.
Of course, we can also write our own functions and pass them into the defaultdict. Suppose we want to create a defaultdict where each new element contains a tuple of the number of items inserted into the dictionary at that time and an empty list to hold other things. Nobody knows why we would want to create such an object, but let's have a look:
from collections import defaultdict
num_items = 0
def tuple_counter():
global num_items
num_items += 1
return (num_items, [])
d = defaultdict(tuple_counter)
When we run this code, we can access empty keys and insert into the list all in one statement:
>>> d = defaultdict(tuple_counter)
>>> d['a'][1].append("hello")
>>> d['b'][1].append('world')
>>> d
defaultdict(<function tuple_counter at 0x82f2c6c>,
{'a': (1, ['hello']), 'b': (2, ['world'])})
When we print dict at the end, we see that the counter really was working.
Counter
You'd think that you couldn't get much simpler than defaultdict(int), but the "I want to count specific instances in an iterable" use case is common enough that the Python developers created a specific class for it. The previous code that counts characters in a string can easily be calculated in a single line:
from collections import Counter
def letter_frequency(sentence):
return Counter(sentence)
The Counter object behaves like a beefed up dictionary where the keys are the items being counted and the values are the number of such items. One of the most useful functions is the most_common() method. It returns a list of (key, count) tuples ordered by the count. You can optionally pass an integer argument into most_common() to request only the top most common elements. For example, you could write a simple polling application as follows:
from collections import Counter
responses = [
"vanilla",
"chocolate",
"vanilla",
"vanilla",
"caramel",
"strawberry",
"vanilla"
]
print(
"The children voted for {} ice cream".format(
Counter(responses).most_common(1)[0][0]
)
)
Presumably, you'd get the responses from a database or by using a complicated vision algorithm to count the kids who raised their hands. Here, we hardcode it so that we can test the most_common method. It returns a list that has only one element (because we requested one element in the parameter). This element stores the name of the top choice at position zero, hence the double [0][0] at the end of the call. I think they look like a surprised face, don't you? Your computer is probably amazed it can count data so easily. It's ancestor, Hollerith's Tabulating Machine for the 1890 US census, must be so jealous!
Lists are the least object-oriented of Python's data structures. While lists are, themselves, objects, there is a lot of syntax in Python to make using them as painless as possible. Unlike many other object-oriented languages, lists in Python are simply available. We don't need to import them and rarely need to call methods on them. We can loop over a list without explicitly requesting an iterator object, and we can construct a list (as with a dictionary) with custom syntax. Further, list comprehensions and generator expressions turn them into a veritable Swiss-army knife of computing functionality.
We won't go into too much detail of the syntax; you've seen it in introductory tutorials across the Web and in previous examples in this book. You can't code Python very long without learning how to use lists! Instead, we'll be covering when lists should be used, and their nature as objects. If you don't know how to create or append to a list, how to retrieve items from a list, or what "slice notation" is, I direct you to the official Python tutorial, post-haste. It can be found online at http://docs.python.org/3/tutorial/.
In Python, lists should normally be used when we want to store several instances of the "same" type of object; lists of strings or lists of numbers; most often, lists of objects we've defined ourselves. Lists should always be used when we want to store items in some kind of order. Often, this is the order in which they were inserted, but they can also be sorted by some criteria.
As we saw in the case study from the previous chapter, lists are also very useful when we need to modify the contents: insert to or delete from an arbitrary location of the list, or update a value within the list.
Like dictionaries, Python lists use an extremely efficient and well-tuned internal data structure so we can worry about what we're storing, rather than how we're storing it. Many object-oriented languages provide different data structures for queues, stacks, linked lists, and array-based lists. Python does provide special instances of some of these classes, if optimizing access to huge sets of data is required. Normally, however, the list data structure can serve all these purposes at once, and the coder has complete control over how they access it.
Don't use lists for collecting different attributes of individual items. We do not want, for example, a list of the properties a particular shape has. Tuples, named tuples, dictionaries, and objects would all be more suitable for this purpose. In some languages, they might create a list in which each alternate item is a different type; for example, they might write ['a', 1, 'b', 3] for our letter frequency list. They'd have to use a strange loop that accesses two elements in the list at once or a modulus operator to determine which position was being accessed.
Don't do this in Python. We can group related items together using a dictionary, as we did in the previous section (if sort order doesn't matter), or using a list of tuples. Here's a rather convoluted example that demonstrates how we could do the frequency example using a list. It is much more complicated than the dictionary examples, and illustrates the effect choosing the right (or wrong) data structure can have on the readability of our code:
import string
CHARACTERS = list(string.ascii_letters) + [" "]
def letter_frequency(sentence):
frequencies = [(c, 0) for c in CHARACTERS]
for letter in sentence:
index = CHARACTERS.index(letter)
frequencies[index] = (letter,frequencies[index][1]+1)
return frequencies
This code starts with a list of possible characters. The string.ascii_letters attribute provides a string of all the letters, lowercase and uppercase, in order. We convert this to a list, and then use list concatenation (the plus operator causes two lists to be merged into one) to add one more character, the space. These are the available characters in our frequency list (the code would break if we tried to add a letter that wasn't in the list, but an exception handler could solve this).
The first line inside the function uses a list comprehension to turn the CHARACTERS list into a list of tuples. List comprehensions are an important, non-object-oriented tool in Python; we'll be covering them in detail in the next chapter.
Then we loop over each of the characters in the sentence. We first look up the index of the character in the CHARACTERS list, which we know has the same index in our frequencies list, since we just created the second list from the first. We then update that index in the frequencies list by creating a new tuple, discarding the original one. Aside from the garbage collection and memory waste concerns, this is rather difficult to read!
Like dictionaries, lists are objects too, and they have several methods that can be invoked upon them. Here are some common ones:
The append(element) method adds an element to the end of the list
The insert(index, element) method inserts an item at a specific position
The count(element) method tells us how many times an element appears in the list
The index()method tells us the index of an item in the list, raising an exception if it can't find it
The find()method does the same thing, but returns -1 instead of raising an exception for missing items
The reverse() method does exactly what it says—turns the list around
The sort() method has some rather intricate object-oriented behaviors, which we'll cover now
Sorting lists
Without any parameters, sort will generally do the expected thing. If it's a list of strings, it will place them in alphabetical order. This operation is case sensitive, so all capital letters will be sorted before lowercase letters, that is Z comes before a. If it is a list of numbers, they will be sorted in numerical order. If a list of tuples is provided, the list is sorted by the first element in each tuple. If a mixture containing unsortable items is supplied, the sort will raise a TypeError exception.
If we want to place objects we define ourselves into a list and make those objects sortable, we have to do a bit more work. The special method lt, which stands for "less than", should be defined on the class to make instances of that class comparable. The sort method on list will access this method on each object to determine where it goes in the list. This method should return True if our class is somehow less than the passed parameter, and False otherwise. Here's a rather silly class that can be sorted based on either a string or a number:
class WeirdSortee:
def __init__(self, string, number, sort_num):
self.string = string
self.number = number
self.sort_num = sort_num
def __lt__(self, object):
if self.sort_num:
return self.number < object.number
return self.string < object.string
def __repr__(self):
return"{}:{}".format(self.string, self.number)
The repr method makes it easy to see the two values when we print a list. The lt method's implementation compares the object to another instance of the same class (or any duck typed object that has string, number, and sort_num attributes; it will fail if those attributes are missing). The following output illustrates this class in action, when it comes to sorting:
>>> a = WeirdSortee('a', 4, True)
>>> b = WeirdSortee('b', 3, True)
>>> c = WeirdSortee('c', 2, True)
>>> d = WeirdSortee('d', 1, True)
>>> l = [a,b,c,d]
>>> l
[a:4, b:3, c:2, d:1]
>>> l.sort()
>>> l
[d:1, c:2, b:3, a:4]
>>> for i in l:
... i.sort_num = False
...
>>> l.sort()
>>> l
[a:4, b:3, c:2, d:1]
The first time we call sort, it sorts by numbers because sort_num is True on all the objects being compared. The second time, it sorts by letters. The lt method is the only one we need to implement to enable sorting. Technically, however, if it is implemented, the class should normally also implement the similar gt, eq, ne, ge, and le methods so that all of the <, >, ==, !=, >=, and <= operators also work properly. You can get this for free by implementing lt and eq, and then applying the @total_ordering class decorator to supply the rest:
from functools import total_ordering
@total_ordering
class WeirdSortee:
def __init__(self, string, number, sort_num):
self.string = string
self.number = number
self.sort_num = sort_num
def __lt__(self, object):
if self.sort_num:
return self.number < object.number
return self.string < object.string
def __repr__(self):
return"{}:{}".format(self.string, self.number)
def __eq__(self, object):
return all((
self.string == object.string,
self.number == object.number,
self.sort_num == object.number
))
This is useful if we want to be able to use operators on our objects. However, if all we want to do is customize our sort orders, even this is overkill. For such a use case, the sort method can take an optional key argument. This argument is a function that can translate each object in a list into an object that can somehow be compared. For example, we can use str.lower as the key argument to perform a case-insensitive sort on a list of strings:
>>> l = ["hello", "HELP", "Helo"]
>>> l.sort()
>>> l
['HELP', 'Helo', 'hello']
>>> l.sort(key=str.lower)
>>> l
['hello', 'Helo', 'HELP']
Remember, even though lower is a method on string objects, it is also a function that can accept a single argument, self. In other words, str.lower(item) is equivalent to item.lower(). When we pass this function as a key, it performs the comparison on lowercase values instead of doing the default case-sensitive comparison.
There are a few sort key operations that are so common that the Python team has supplied them so you don't have to write them yourself. For example, it is often common to sort a list of tuples by something other than the first item in the list. The operator.itemgetter method can be used as a key to do this:
>>> from operator import itemgetter
>>> l = [('h', 4), ('n', 6), ('o', 5), ('p', 1), ('t', 3), ('y', 2)]
>>> l.sort(key=itemgetter(1))
>>> l
[('p', 1), ('y', 2), ('t', 3), ('h', 4), ('o', 5), ('n', 6)]
The itemgetter function is the most commonly used one (it works if the objects are dictionaries, too), but you will sometimes find use for attrgetter and methodcaller, which return attributes on an object and the results of method calls on objects for the same purpose. See the operator module documentation for more information.
Lists are extremely versatile tools that suit most container object applications. But they are not useful when we want to ensure objects in the list are unique. For example, a song library may contain many songs by the same artist. If we want to sort through the library and create a list of all the artists, we would have to check the list to see if we've added the artist already, before we add them again.
This is where sets come in. Sets come from mathematics, where they represent an unordered group of (usually) unique numbers. We can add a number to a set five times, but it will show up in the set only once.
In Python, sets can hold any hashable object, not just numbers. Hashable objects are the same objects that can be used as keys in dictionaries; so again, lists and dictionaries are out. Like mathematical sets, they can store only one copy of each object. So if we're trying to create a list of song artists, we can create a set of string names and simply add them to the set. This example starts with a list of (song, artist) tuples and creates a set of the artists:
song_library = [("Phantom Of The Opera", "Sarah Brightman"),
("Knocking On Heaven's Door", "Guns N' Roses"),
("Captain Nemo", "Sarah Brightman"),
("Patterns In The Ivy", "Opeth"),
("November Rain", "Guns N' Roses"),
("Beautiful", "Sarah Brightman"),
("Mal's Song", "Vixy and Tony")]
artists = set()
for song, artist in song_library:
artists.add(artist)
print(artists)
There is no built-in syntax for an empty set as there is for lists and dictionaries; we create a set using the set() constructor. However, we can use the curly braces (borrowed from dictionary syntax) to create a set, so long as the set contains values. If we use colons to separate pairs of values, it's a dictionary, as in {'key': 'value', 'key2': 'value2'}. If we just separate values with commas, it's a set, as in {'value', 'value2'}. Items can be added individually to the set using its add method. If we run this script, we see that the set works as advertised:
{'Sarah Brightman', "Guns N' Roses", 'Vixy and Tony', 'Opeth'}
If you're paying attention to the output, you'll notice that the items are not printed in the order they were added to the sets. Sets, like dictionaries, are unordered. They both use an underlying hash-based data structure for efficiency. Because they are unordered, sets cannot have items looked up by index. The primary purpose of a set is to divide the world into two groups: "things that are in the set", and, "things that are not in the set". It is easy to check whether an item is in the set or to loop over the items in a set, but if we want to sort or order them, we'll have to convert the set to a list. This output shows all three of these activities:
>>> "Opeth" in artists
True
>>> for artist in artists:
... print("{} plays good music".format(artist))
...
Sarah Brightman plays good music
Guns N' Roses plays good music
Vixy and Tony play good music
Opeth plays good music
>>> alphabetical = list(artists)
>>> alphabetical.sort()
>>> alphabetical
["Guns N' Roses", 'Opeth', 'Sarah Brightman', 'Vixy and Tony']
While the primary feature of a set is uniqueness, that is not its primary purpose. Sets are most useful when two or more of them are used in combination. Most of the methods on the set type operate on other sets, allowing us to efficiently combine or compare the items in two or more sets. These methods have strange names, since they use the same terminology used in mathematics. We'll start with three methods that return the same result, regardless of which is the calling set and which is the called set.
The union method is the most common and easiest to understand. It takes a second set as a parameter and returns a new set that contains all elements that are in either of the two sets; if an element is in both original sets, it will, of course, only show up once in the new set. Union is like a logical or operation, indeed, the | operator can be used on two sets to perform the union operation, if you don't like calling methods.
Conversely, the intersection method accepts a second set and returns a new set that contains only those elements that are in both sets. It is like a logical and operation, and can also be referenced using the & operator.
Finally, the symmetric_difference method tells us what's left; it is the set of objects that are in one set or the other, but not both. The following example illustrates these methods by comparing some artists from my song library to those in my sister's:
my_artists = {"Sarah Brightman", "Guns N' Roses",
"Opeth", "Vixy and Tony"}
auburns_artists = {"Nickelback", "Guns N' Roses",
"Savage Garden"}
print("All: {}".format(my_artists.union(auburns_artists)))
print("Both: {}".format(auburns_artists.intersection(my_artists)))
print("Either but not both: {}".format(
my_artists.symmetric_difference(auburns_artists)))
If we run this code, we see that these three methods do what the print statements suggest they will do:
All: {'Sarah Brightman', "Guns N' Roses", 'Vixy and Tony',
'Savage Garden', 'Opeth', 'Nickelback'}
Both: {"Guns N' Roses"}
Either but not both: {'Savage Garden', 'Opeth', 'Nickelback',
'Sarah Brightman', 'Vixy and Tony'}
These methods all return the same result, regardless of which set calls the other. We can say my_artists.union(auburns_artists) or auburns_artists.union(my_artists) and get the same result. There are also methods that return different results depending on who is the caller and who is the argument.
These methods include issubset and issuperset, which are the inverse of each other. Both return a bool. The issubset method returns True, if all of the items in the calling set are also in the set passed as an argument. The issuperset method returns True if all of the items in the argument are also in the calling set. Thus s.issubset(t) and t.issuperset(s) are identical. They will both return True if t contains all the elements in s.
Finally, the difference method returns all the elements that are in the calling set, but not in the set passed as an argument; this is like half a symmetric_difference. The difference method can also be represented by the - operator. The following code illustrates these methods in action:
my_artists = {"Sarah Brightman", "Guns N' Roses",
"Opeth", "Vixy and Tony"}
bands = {"Guns N' Roses", "Opeth"}
print("my_artists is to bands:")
print("issuperset: {}".format(my_artists.issuperset(bands)))
print("issubset: {}".format(my_artists.issubset(bands)))
print("difference: {}".format(my_artists.difference(bands)))
print("*"*20)
print("bands is to my_artists:")
print("issuperset: {}".format(bands.issuperset(my_artists)))
print("issubset: {}".format(bands.issubset(my_artists)))
print("difference: {}".format(bands.difference(my_artists)))
This code simply prints out the response of each method when called from one set on the other. Running it gives us the following output:
my_artists is to bands:
issuperset: True
issubset: False
difference: {'Sarah Brightman', 'Vixy and Tony'}
********************
bands is to my_artists:
issuperset: False
issubset: True
difference: set()
The difference method, in the second case, returns an empty set, since there are no items in bands that are not in my_artists.
The union, intersection, and difference methods can all take multiple sets as arguments; they will return, as we might expect, the set that is created when the operation is called on all the parameters.
So the methods on sets clearly suggest that sets are meant to operate on other sets, and that they are not just containers. If we have data coming in from two different sources and need to quickly combine them in some way, to determine where the data overlaps or is different, we can use set operations to efficiently compare them. Or if we have data incoming that may contain duplicates of data that has already been processed, we can use sets to compare the two and process only the new data.
Finally, it is valuable to know that sets are much more efficient than lists when checking for membership using the in keyword. If you use the syntax value in container on a set or a list, it will return True if one of the elements in container is equal to value and False otherwise. However, in a list, it will look at every object in the container until it finds the value, whereas in a set, it simply hashes the value and checks for membership. This means that a set will find the value in the same amount of time no matter how big the container is, but a list will take longer and longer to search for a value as the list contains more and more values.
We discussed briefly in Chapter 3, When Objects Are Alike, how built-in data types can be extended using inheritance. Now, we'll go into more detail as to when we would want to do that.
When we have a built-in container object that we want to add functionality to, we have two options. We can either create a new object, which holds that container as an attribute (composition), or we can subclass the built-in object and add or adapt methods on it to do what we want (inheritance).
Composition is usually the best alternative if all we want to do is use the container to store some objects using that container's features. That way, it's easy to pass that data structure into other methods and they will know how to interact with it. But we need to use inheritance if we want to change the way the container actually works. For example, if we want to ensure every item in a list is a string with exactly five characters, we need to extend list and override the append() method to raise an exception for invalid input. We'd also minimally have to override setitem(self, index, value), a special method on lists that is called whenever we use the x[index] = "value" syntax, and the extend() method.
Yes, lists are objects. All that special non-object-oriented looking syntax we've been looking at for accessing lists or dictionary keys, looping over containers, and similar tasks is actually "syntactic sugar" that maps to an object-oriented paradigm underneath. We might ask the Python designers why they did this. Isn't object-oriented programming always better? That question is easy to answer. In the following hypothetical examples, which is easier to read, as a programmer? Which requires less typing?
c = a + b c = a.add(b)
l[0] = 5 l.setitem(0, 5) d[key] = value d.setitem(key, value)
for x in alist: #do something with x it = alist.iterator() while it.has_next(): x = it.next() #do something with x The highlighted sections show what object-oriented code might look like (in practice, these methods actually exist as special double-underscore methods on associated objects). Python programmers agree that the non-object-oriented syntax is easier both to read and to write. Yet all of the preceding Python syntaxes map to object-oriented methods underneath the hood. These methods have special names (with double-underscores before and after) to remind us that there is a better syntax out there. However, it gives us the means to override these behaviors. For example, we can make a special integer that always returns 0 when we add two of them together:
class SillyInt(int): def add(self, num): return 0 This is an extremely bizarre thing to do, granted, but it perfectly illustrates these object-oriented principles in action:
a = SillyInt(1) b = SillyInt(2) a + b 0 The awesome thing about the add method is that we can add it to any class we write, and if we use the + operator on instances of that class, it will be called. This is how string, tuple, and list concatenation works, for example.
This is true of all the special methods. If we want to use x in myobj syntax for a custom-defined object, we can implement contains. If we want to use myobj[i] = value syntax, we supply a setitem method and if we want to use something = myobj[i], we implement getitem.
There are 33 of these special methods on the list class. We can use the dir function to see all of them:
dir(list)
['add', 'class', 'contains', 'delattr','delitem', 'doc', 'eq', 'format', 'ge', 'getattribute', 'getitem', 'gt', 'hash', 'iadd', 'imul', 'init', 'iter', 'le', 'len', 'lt', 'mul', 'ne', 'new', 'reduce', 'reduce_ex', 'repr', 'reversed', 'rmul', 'setattr', 'setitem', 'sizeof', 'str', 'subclasshook', 'append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort' Further, if we desire additional information on how any of these methods works, we can use the help function:
help(list.add) Help on wrapper_descriptor:
add(self, value, /) Return self+value. The plus operator on lists concatenates two lists. We don't have room to discuss all of the available special functions in this book, but you are now able to explore all this functionality with dir and help. The official online Python reference (https://docs.python.org/3/) has plenty of useful information as well. Focus, especially, on the abstract base classes discussed in the collections module.
So, to get back to the earlier point about when we would want to use composition versus inheritance: if we need to somehow change any of the methods on the class—including the special methods—we definitely need to use inheritance. If we used composition, we could write methods that do the validation or alterations and ask the caller to use those methods, but there is nothing stopping them from accessing the property directly. They could insert an item into our list that does not have five characters, and that might confuse other methods in the list.
Often, the need to extend a built-in data type is an indication that we're using the wrong sort of data type. It is not always the case, but if we are looking to extend a built-in, we should carefully consider whether or not a different data structure would be more suitable.
For example, consider what it takes to create a dictionary that remembers the order in which keys were inserted. One way to do this is to keep an ordered list of keys that is stored in a specially derived subclass of dict. Then we can override the methods keys, values, iter, and items to return everything in order. Of course, we'll also have to override setitem and setdefault to keep our list up to date. There are likely to be a few other methods in the output of dir(dict) that need overriding to keep the list and dictionary consistent (clear and delitem come to mind, to track when items are removed), but we won't worry about them for this example.
So we'll be extending dict and adding a list of ordered keys. Trivial enough, but where do we create the actual list? We could include it in the init method, which would work just fine, but we have no guarantees that any subclass will call that initializer. Remember the new method we discussed in Chapter 2, Objects in Python? I said it was generally only useful in very special cases. This is one of those special cases. We know new will be called exactly once, and we can create a list on the new instance that will always be available to our class. With that in mind, here is our entire sorted dictionary:
from collections import KeysView, ItemsView, ValuesView class DictSorted(dict): def new(*args, **kwargs): new_dict = dict.new(*args, **kwargs) new_dict.ordered_keys = [] return new_dict
def __setitem__(self, key, value):
'''self[key] = value syntax'''
if key not in self.ordered_keys:
self.ordered_keys.append(key)
super().__setitem__(key, value)
def setdefault(self, key, value):
if key not in self.ordered_keys:
self.ordered_keys.append(key)
return super().setdefault(key, value)
def keys(self):
return KeysView(self)
def values(self):
return ValuesView(self)
def items(self):
return ItemsView(self)
def __iter__(self):
'''for x in self syntax'''
return self.ordered_keys.__iter__()
The new method creates a new dictionary and then puts an empty list on that object. We don't override init, as the default implementation works (actually, this is only true if we initialize an empty DictSorted object, which is standard behavior. If we want to support other variations of the dict constructor, which accept dictionaries or lists of tuples, we'd need to fix init to also update our ordered_keys list). The two methods for setting items are very similar; they both update the list of keys, but only if the item hasn't been added before. We don't want duplicates in the list, but we can't use a set here; it's unordered!
The keys, items, and values methods all return views onto the dictionary. The collections library provides three read-only View objects onto the dictionary; they use the iter method to loop over the keys, and then use getitem (which we didn't need to override) to retrieve the values. So, we only need to define our custom iter method to make these three views work. You would think the superclass would create these views properly using polymorphism, but if we don't override these three methods, they don't return properly ordered views.
Finally, the iter method is the really special one; it ensures that if we loop over the dictionary's keys (using for...in syntax), it will return the values in the correct order. It does this by returning the iter of the ordered_keys list, which returns the same iterator object that would be used if we used for...in on the list instead. Since ordered_keys is a list of all available keys (due to the way we overrode other methods), this is the correct iterator object for the dictionary as well.
Let's look at a few of these methods in action, compared to a normal dictionary:
>>> ds = DictSorted()
>>> d = {}
>>> ds['a'] = 1
>>> ds['b'] = 2
>>> ds.setdefault('c', 3)
3
>>> d['a'] = 1
>>> d['b'] = 2
>>> d.setdefault('c', 3)
3
>>> for k,v in ds.items():
... print(k,v)
...
a 1
b 2
c 3
>>> for k,v in d.items():
... print(k,v)
...
a 1
c 3
b 2
Ah, our dictionary is sorted and the normal dictionary is not. Hurray!
Queues are peculiar data structures because, like sets, their functionality can be handled entirely using lists. However, while lists are extremely versatile general-purpose tools, they are occasionally not the most efficient data structure for container operations. If your program is using a small dataset (up to hundreds or even thousands of elements on today's processors), then lists will probably cover all your use cases. However, if you need to scale your data into the millions, you may need a more efficient container for your particular use case. Python therefore provides three types of queue data structures, depending on what kind of access you are looking for. All three utilize the same API, but differ in both behavior and data structure.
Before we start our queues, however, consider the trusty list data structure. Python lists are the most advantageous data structure for many use cases:
They support efficient random access to any element in the list
They have strict ordering of elements
They support the append operation efficiently
They tend to be slow, however, if you are inserting elements anywhere but the end of the list (especially so if it's the beginning of the list). As we discussed in the section on sets, they are also slow for checking if an element exists in the list, and by extension, searching. Storing data in a sorted order or reordering the data can also be inefficient.
Let's look at the three types of containers provided by the Python queue module.
FIFO queues
FIFO stands for First In First Out and represents the most commonly understood definition of the word "queue". Imagine a line of people standing in line at a bank or cash register. The first person to enter the line gets served first, the second person in line gets served second, and if a new person desires service, they join the end of the line and wait their turn.
The Python Queue class is just like that. It is typically used as a sort of communication medium when one or more objects is producing data and one or more other objects is consuming the data in some way, probably at a different rate. Think of a messaging application that is receiving messages from the network, but can only display one message at a time to the user. The other messages can be buffered in a queue in the order they are received. FIFO queues are utilized a lot in such concurrent applications. (We'll talk more about concurrency in Chapter 12, Testing Object-oriented Programs.)
The Queue class is a good choice when you don't need to access any data inside the data structure except the next object to be consumed. Using a list for this would be less efficient because under the hood, inserting data at (or removing from) the beginning of a list can require shifting every other element in the list.
Queues have a very simple API. A Queue can have "infinite" (until the computer runs out of memory) capacity, but it is more commonly bounded to some maximum size. The primary methods are put() and get(), which add an element to the back of the line, as it were, and retrieve them from the front, in order. Both of these methods accept optional arguments to govern what happens if the operation cannot successfully complete because the queue is either empty (can't get) or full (can't put). The default behavior is to block or idly wait until the Queue object has data or room available to complete the operation. You can have it raise exceptions instead by passing the block=False parameter. Or you can have it wait a defined amount of time before raising an exception by passing a timeout parameter.
The class also has methods to check whether the Queue is full() or empty() and there are a few additional methods to deal with concurrent access that we won't discuss here. Here is a interactive session demonstrating these principles:
>>> from queue import Queue
>>> lineup = Queue(maxsize=3)
>>> lineup.get(block=False)
Traceback (most recent call last):
File "<ipython-input-5-a1c8d8492c59>", line 1, in <module>
lineup.get(block=False)
File "/usr/lib64/python3.3/queue.py", line 164, in get
raise Empty
queue.Empty
>>> lineup.put("one")
>>> lineup.put("two")
>>> lineup.put("three")
>>> lineup.put("four", timeout=1)
Traceback (most recent call last):
File "<ipython-input-9-4b9db399883d>", line 1, in <module>
lineup.put("four", timeout=1)
File "/usr/lib64/python3.3/queue.py", line 144, in put
raise Full
queue.Full
>>> lineup.full()
True
>>> lineup.get()
'one'
>>> lineup.get()
'two'
>>> lineup.get()
'three'
>>> lineup.empty()
True
Underneath the hood, Python implements queues on top of the collections.deque data structure. Deques are advanced data structures that permits efficient access to both ends of the collection. It provides a more flexible interface than is exposed by Queue. I refer you to the Python documentation if you'd like to experiment more with it.
LIFO queues
LIFO (Last In First Out) queues are more frequently called stacks. Think of a stack of papers where you can only access the top-most paper. You can put another paper on top of the stack, making it the new top-most paper, or you can take the top-most paper away to reveal the one beneath it.
Traditionally, the operations on stacks are named push and pop, but the Python queue module uses the exact same API as for FIFO queues: put() and get(). However, in a LIFO queue, these methods operate on the "top" of the stack instead of at the front and back of a line. This is an excellent example of polymorphism. If you look at the Queue source code in the Python standard library, you'll actually see that there is a superclass with subclasses for FIFO and LIFO queues that implement the few operations (operating on the top of a stack instead of front and back of a deque instance) that are critically different between the two.
Here's an example of the LIFO queue in action:
>>> from queue import LifoQueue
>>> stack = LifoQueue(maxsize=3)
>>> stack.put("one")
>>> stack.put("two")
>>> stack.put("three")
>>> stack.put("four", block=False)
Traceback (most recent call last):
File "<ipython-input-21-5473b359e5a8>", line 1, in <module>
stack.put("four", block=False)
File "/usr/lib64/python3.3/queue.py", line 133, in put
raise Full
queue.Full
>>> stack.get()
'three'
>>> stack.get()
'two'
>>> stack.get()
'one'
>>> stack.empty()
True
>>> stack.get(timeout=1)
Traceback (most recent call last):
File "<ipython-input-26-28e084a84a10>", line 1, in <module>
stack.get(timeout=1)
File "/usr/lib64/python3.3/queue.py", line 175, in get
raise Empty
queue.Empty
You might wonder why you couldn't just use the append() and pop() methods on a standard list. Quite frankly, that's probably what I would do. I rarely have occasion to use the LifoQueue class in production code. Working with the end of a list is an efficient operation; so efficient, in fact, that the LifoQueue uses a standard list under the hood!
There are a couple of reasons that you might want to use LifoQueue instead of a list. The most important one is that LifoQueue supports clean concurrent access from multiple threads. If you need stack-like behavior in a concurrent setting, you should leave the list at home. Second, LifoQueue enforces the stack interface. You can't unwittingly insert a value to the wrong position in a LifoQueue, for example (although, as an exercise, you can work out how to do this completely wittingly).
Priority queues The priority queue enforces a very different style of ordering from the previous queue implementations. Once again, they follow the exact same get() and put() API, but instead of relying on the order that items arrive to determine when they should be returned, the most "important" item is returned. By convention, the most important, or highest priority item is the one that sorts lowest using the less than operator.
A common convention is to store tuples in the priority queue, where the first element in the tuple is the priority for that element, and the second element is the data. Another common paradigm is to implement the lt method, as we discussed earlier in this chapter. It is perfectly acceptable to have multiple elements with the same priority in the queue, although there are no guarantees on which one will be returned first.
A priority queue might be used, for example, by a search engine to ensure it refreshes the content of the most popular web pages before crawling sites that are less likely to be searched for. A product recommendation tool might use one to display information about the most highly ranked products while still loading data for the lower ranks.
Note that a priority queue will always return the most important element currently in the queue. The get() method will block (by default) if the queue is empty, but it will not block and wait for a higher priority element to be added if there is already something in the queue. The queue knows nothing about elements that have not been added yet (or even about elements that have been previously extracted), and only makes decisions based on the current contents of the queue.
This interactive session shows a priority queue in action, using tuples as weights to determine what order items are processed in:
>>> heap.put((3, "three"))
>>> heap.put((4, "four"))
>>> heap.put((1, "one") )
>>> heap.put((2, "two"))
>>> heap.put((5, "five"), block=False)
Traceback (most recent call last):
File "<ipython-input-23-d4209db364ed>", line 1, in <module>
heap.put((5, "five"), block=False)
File "/usr/lib64/python3.3/queue.py", line 133, in put
raise Full
Full
>>> while not heap.empty():
print(heap.get())
(1, 'one')
(2, 'two')
(3, 'three')
(4, 'four')
Priority queues are almost universally implemented using the heap data structure. Python's implementation utilizes the heapq module to effectively store a heap inside a normal list. I direct you to an algorithm and data-structure's textbook for more information on heaps, not to mention many other fascinating structures we haven't covered here. No matter what the data structure, you can use object-oriented principles to wrap relevant algorithms (behaviors), such as those supplied in the heapq module, around the data they are structuring in the computer's memory, just as the queue module has done on our behalf in the standard library.
There are numerous functions in Python that perform a task or calculate a result on certain types of objects without being methods on the underlying class. They usually abstract common calculations that apply to multiple types of classes. This is duck typing at its best; these functions accept objects that have certain attributes or methods, and are able to perform generic operations using those methods. Many, but not all, of these are special double underscore methods. We've used many of the built-in functions already, but let's quickly go through the important ones and pick up a few neat tricks along the way.
The len() function
The simplest example is the len() function, which counts the number of items in some kind of container object, such as a dictionary or list. You've seen it before:
>>> len([1,2,3,4])
4
Why don't these objects have a length property instead of having to call a function on them? Technically, they do. Most objects that len() will apply to have a method called len() that returns the same value. So len(myobj) seems to call myobj.len().
Why should we use the len() function instead of the len method? Obviously len is a special double-underscore method, suggesting that we shouldn't call it directly. There must be an explanation for this. The Python developers don't make such design decisions lightly.
The main reason is efficiency. When we call len on an object, the object has to look the method up in its namespace, and, if the special getattribute method (which is called every time an attribute or method on an object is accessed) is defined on that object, it has to be called as well. Further, getattribute for that particular method may have been written to do something nasty, like refusing to give us access to special methods such as len! The len() function doesn't encounter any of this. It actually calls the len function on the underlying class, so len(myobj) maps to MyObj.len(myobj).
Another reason is maintainability. In the future, the Python developers may want to change len() so that it can calculate the length of objects that don't have len, for example, by counting the number of items returned in an iterator. They'll only have to change one function instead of countless len methods across the board.
There is one other extremely important and often overlooked reason for len() being an external function: backwards compatibility. This is often cited in articles as "for historical reasons", which is a mildly dismissive phrase that an author will use to say something is the way it is because a mistake was made long ago and we're stuck with it. Strictly speaking, len() isn't a mistake, it's a design decision, but that decision was made in a less object-oriented time. It has stood the test of time and has some benefits, so do get used to it.
Reversed
The reversed() function takes any sequence as input, and returns a copy of that sequence in reverse order. It is normally used in for loops when we want to loop over items from back to front.
Similar to len, reversed calls the reversed() function on the class for the parameter. If that method does not exist, reversed builds the reversed sequence itself using calls to len and getitem, which are used to define a sequence. We only need to override reversed if we want to somehow customize or optimize the process:
normal_list=[1,2,3,4,5]
class CustomSequence():
def __len__(self):
return 5
def __getitem__(self, index):
return "x{0}".format(index)
class FunkyBackwards():
def __reversed__(self):
return "BACKWARDS!"
for seq in normal_list, CustomSequence(), FunkyBackwards():
print("\n{}: ".format(seq.__class__.__name__), end="")
for item in reversed(seq):
print(item, end=", ")
The for loops at the end print the reversed versions of a normal list, and instances of the two custom sequences. The output shows that reversed works on all three of them, but has very different results when we define reversed ourselves:
list: 5, 4, 3, 2, 1,
CustomSequence: x4, x3, x2, x1, x0,
FunkyBackwards: B, A, C, K, W, A, R, D, S, !,
When we reverse CustomSequence, the getitem method is called for each item, which just inserts an x before the index. For FunkyBackwards, the reversed method returns a string, each character of which is output individually in the for loop.
Enumerate
Sometimes, when we're looping over a container in a for loop, we want access to the index (the current position in the list) of the current item being processed. The for loop doesn't provide us with indexes, but the enumerate function gives us something better: it creates a sequence of tuples, where the first object in each tuple is the index and the second is the original item.
This is useful if we need to use index numbers directly. Consider some simple code that outputs each of the lines in a file with line numbers:
import sys
filename = sys.argv[1]
with open(filename) as file:
for index, line in enumerate(file):
print("{0}: {1}".format(index+1, line), end='')
Running this code using it's own filename as the input file shows how it works:
1: import sys
2: filename = sys.argv[1]
3:
4: with open(filename) as file:
5: for index, line in enumerate(file):
6: print("{0}: {1}".format(index+1, line), end='')
The enumerate function returns a sequence of tuples, our for loop splits each tuple into two values, and the print statement formats them together. It adds one to the index for each line number, since enumerate, like all sequences, is zero-based.
We've only touched on a few of the more important Python built-in functions. As you can see, many of them call into object-oriented concepts, while others subscribe to purely functional or procedural paradigms. There are numerous others in the standard library; some of the more interesting ones include:
all and any, which accept an iterable object and return True if all, or any, of the items evaluate to true (such as a nonempty string or list, a nonzero number, an object that is not None, or the literal True). eval, exec, and compile, which execute string as code inside the interpreter. Be careful with these ones; they are not safe, so don't execute code an unknown user has supplied to you (in general, assume all unknown users are malicious, foolish, or both).
hasattr, getattr, setattr, and delattr, which allow attributes on an object to be manipulated by their string names. zip, which takes two or more sequences and returns a new sequence of tuples, where each tuple contains a single value from each sequence.
And many more! See the interpreter help documentation for each of the functions listed in dir(builtins).
File I/O
Our examples so far that touch the filesystem have operated entirely on text files without much thought to what is going on under the hood. Operating systems, however, actually represent files as a sequence of bytes, not text. We'll do a deep dive into the relationship between bytes and text in Chapter 8, Strings and Serialization. For now, be aware that reading textual data from a file is a fairly involved process. Python, especially Python 3, takes care of most of this work for us behind the scenes. Aren't we lucky?
The concept of files has been around since long before anyone coined the term object-oriented programming. However, Python has wrapped the interface that operating systems provide in a sweet abstraction that allows us to work with file (or file-like, vis-á-vis duck typing) objects.
The open() built-in function is used to open a file and return a file object. For reading text from a file, we only need to pass the name of the file into the function. The file will be opened for reading, and the bytes will be converted to text using the platform default encoding.
Of course, we don't always want to read files; often we want to write data to them! To open a file for writing, we need to pass a mode argument as the second positional argument, with a value of "w":
contents = "Some file contents"
file = open("filename", "w")
file.write(contents)
file.close()
We could also supply the value "a" as a mode argument, to append to the end of the file, rather than completely overwriting existing file contents.
These files with built-in wrappers for converting bytes to text are great, but it'd be awfully inconvenient if the file we wanted to open was an image, executable, or other binary file, wouldn't it?
To open a binary file, we modify the mode string to append 'b'. So, 'wb' would open a file for writing bytes, while 'rb' allows us to read them. They will behave like text files, but without the automatic encoding of text to bytes. When we read such a file, it will return bytes objects instead of str, and when we write to it, it will fail if we try to pass a text object.
Once a file is opened for reading, we can call the read, readline, or readlines methods to get the contents of the file. The read method returns the entire contents of the file as a str or bytes object, depending on whether there is 'b' in the mode. Be careful not to use this method without arguments on huge files. You don't want to find out what happens if you try to load that much data into memory!
It is also possible to read a fixed number of bytes from a file; we pass an integer argument to the read method describing how many bytes we want to read. The next call to read will load the next sequence of bytes, and so on. We can do this inside a while loop to read the entire file in manageable chunks.
The readline method returns a single line from the file (where each line ends in a newline, a carriage return, or both, depending on the operating system on which the file was created). We can call it repeatedly to get additional lines. The plural readlines method returns a list of all the lines in the file. Like the read method, it's not safe to use on very large files. These two methods even work when the file is open in bytes mode, but it only makes sense if we are parsing text-like data that has newlines at reasonable positions. An image or audio file, for example, will not have newline characters in it (unless the newline byte happened to represent a certain pixel or sound), so applying readline wouldn't make sense.
For readability, and to avoid reading a large file into memory at once, it is often better to use a for loop directly on a file object. For text files, it will read each line, one at a time, and we can process it inside the loop body. For binary files, it's better to read fixed-sized chunks of data using the read() method, passing a parameter for the maximum number of bytes to read.
Writing to a file is just as easy; the write method on file objects writes a string (or bytes, for binary data) object to the file. It can be called repeatedly to write multiple strings, one after the other. The writelines method accepts a sequence of strings and writes each of the iterated values to the file. The writelines method does not append a new line after each item in the sequence. It is basically a poorly named convenience function to write the contents of a sequence of strings without having to explicitly iterate over it using a for loop.
Lastly, and I do mean lastly, we come to the close method. This method should be called when we are finished reading or writing the file, to ensure any buffered writes are written to the disk, that the file has been properly cleaned up, and that all resources associated with the file are released back to the operating system. Technically, this will happen automatically when the script exits, but it's better to be explicit and clean up after ourselves, especially in long-running processes.
Placing it in context The need to close files when we are finished with them can make our code quite ugly. Because an exception may occur at any time during file I/O, we ought to wrap all calls to a file in a try...finally clause. The file should be closed in the finally clause, regardless of whether I/O was successful. This isn't very Pythonic. Of course, there is a more elegant way to do it.
If we run dir on a file-like object, we see that it has two special methods named enter and exit. These methods turn the file object into what is known as a context manager. Basically, if we use a special syntax called the with statement, these methods will be called before and after nested code is executed. On file objects, the exit method ensures the file is closed, even if an exception is raised. We no longer have to explicitly manage the closing of the file. Here is what the with statement looks like in practice:
with open('filename') as file:
for line in file:
print(line, end='')
The open call returns a file object, which has enter and exit methods. The returned object is assigned to the variable named file by the as clause. We know the file will be closed when the code returns to the outer indentation level, and that this will happen even if an exception is raised.
The with statement is used in several places in the standard library where startup or cleanup code needs to be executed. For example, the urlopen call returns an object that can be used in a with statement to clean up the socket when we're done. Locks in the threading module can automatically release the lock when the statement has been executed.
Most interestingly, because the with statement can apply to any object that has the appropriate special methods, we can use it in our own frameworks. For example, remember that strings are immutable, but sometimes you need to build a string from multiple parts. For efficiency, this is usually done by storing the component strings in a list and joining them at the end. Let's create a simple context manager that allows us to construct a sequence of characters and automatically convert it to a string upon exit:
class StringJoiner(list):
def __enter__(self):
return self
def __exit__(self, type, value, tb):
self.result = "".join(self)
This code adds the two special methods required of a context manager to the list class it inherits from. The enter method performs any required setup code (in this case, there isn't any) and then returns the object that will be assigned to the variable after as in the with statement. Often, as we've done here, this is just the context manager object itself. The exit method accepts three arguments. In a normal situation, these are all given a value of None. However, if an exception occurs inside the with block, they will be set to values related to the type, value, and traceback for the exception. This allows the exit method to do any cleanup code that may be required, even if an exception occurred. In our example, we take the irresponsible path and create a result string by joining the characters in the string, regardless of whether an exception was thrown.
While this is one of the simplest context managers we could write, and its usefulness is dubious, it does work with a with statement. Have a look at it in action:
import random, string
with StringJoiner() as joiner:
for i in range(15):
joiner.append(random.choice(string.ascii_letters))
print(joiner.result)
This code constructs a string of 15 random characters. It appends these to a StringJoiner using the append method it inherited from list. When the with statement goes out of scope (back to the outer indentation level), the exit method is called, and the result attribute becomes available on the joiner object. We print this value to see a random string.
One prominent feature of many object-oriented programming languages is a tool called method overloading. Method overloading simply refers to having multiple methods with the same name that accept different sets of arguments. In statically typed languages, this is useful if we want to have a method that accepts either an integer or a string, for example. In non-object-oriented languages, we might need two functions, called add_s and add_i, to accommodate such situations. In statically typed object-oriented languages, we'd need two methods, both called add, one that accepts strings, and one that accepts integers.
In Python, we only need one method, which accepts any type of object. It may have to do some testing on the object type (for example, if it is a string, convert it to an integer), but only one method is required.
However, method overloading is also useful when we want a method with the same name to accept different numbers or sets of arguments. For example, an e-mail message method might come in two versions, one of which accepts an argument for the "from" e-mail address. The other method might look up a default "from" e-mail address instead. Python doesn't permit multiple methods with the same name, but it does provide a different, equally flexible, interface.
We've seen some of the possible ways to send arguments to methods and functions in previous examples, but now we'll cover all the details. The simplest function accepts no arguments. We probably don't need an example, but here's one for completeness:
def no_args():
pass
Here's how it's called:
no_args()
A function that does accept arguments will provide the names of those arguments in a comma-separated list. Only the name of each argument needs to be supplied.
When calling the function, these positional arguments must be specified in order, and none can be missed or skipped. This is the most common way we've specified arguments in our previous examples:
def mandatory_args(x, y, z):
pass
To call it:
mandatory_args("a string", a_variable, 5) Any type of object can be passed as an argument: an object, a container, a primitive, even functions and classes. The preceding call shows a hardcoded string, an unknown variable, and an integer passed into the function.
Default arguments If we want to make an argument optional, rather than creating a second method with a different set of arguments, we can specify a default value in a single method, using an equals sign. If the calling code does not supply this argument, it will be assigned a default value. However, the calling code can still choose to override the default by passing in a different value. Often, a default value of None, or an empty string or list is suitable.
Here's a function definition with default arguments:
def default_arguments(x, y, z, a="Some String", b=False):
pass
The first three arguments are still mandatory and must be passed by the calling code. The last two parameters have default arguments supplied.
There are several ways we can call this function. We can supply all arguments in order as though all the arguments were positional arguments:
default_arguments("a string", variable, 8, "", True)
Alternatively, we can supply just the mandatory arguments in order, leaving the keyword arguments to be assigned their default values:
default_arguments("a longer string", some_variable, 14)
We can also use the equals sign syntax when calling a function to provide values in a different order, or to skip default values that we aren't interested in. For example, we can skip the first keyword arguments and supply the second one:
default_arguments("a string", variable, 14, b=True)
Surprisingly, we can even use the equals sign syntax to mix up the order of positional arguments, so long as all of them are supplied:
>>> default_arguments(y=1,z=2,x=3,a="hi")
3 1 2 hi False
With so many options, it may seem hard to pick one, but if you think of the positional arguments as an ordered list, and keyword arguments as sort of like a dictionary, you'll find that the correct layout tends to fall into place. If you need to require the caller to specify an argument, make it mandatory; if you have a sensible default, then make it a keyword argument. Choosing how to call the method normally takes care of itself, depending on which values need to be supplied, and which can be left at their defaults.
One thing to take note of with keyword arguments is that anything we provide as a default argument is evaluated when the function is first interpreted, not when it is called. This means we can't have dynamically generated default values. For example, the following code won't behave quite as expected:
number = 5
def funky_function(number=number):
print(number)
number=6
funky_function(8)
funky_function()
print(number)
If we run this code, it outputs the number 8 first, but then it outputs the number 5 for the call with no arguments. We had set the variable to the number 6, as evidenced by the last line of output, but when the function is called, the number 5 is printed; the default value was calculated when the function was defined, not when it was called.
This is tricky with empty containers such as lists, sets, and dictionaries. For example, it is common to ask calling code to supply a list that our function is going to manipulate, but the list is optional. We'd like to make an empty list as a default argument. We can't do this; it will create only one list, when the code is first constructed:
>>> def hello(b=[]):
... b.append('a')
... print(b)
...
>>> hello()
['a']
>>> hello()
['a', 'a']
Whoops, that's not quite what we expected! The usual way to get around this is to make the default value None, and then use the idiom iargument = argument if argument else [] inside the method. Pay close attention!
Variable argument lists Default values alone do not allow us all the flexible benefits of method overloading. The thing that makes Python really slick is the ability to write methods that accept an arbitrary number of positional or keyword arguments without explicitly naming them. We can also pass arbitrary lists and dictionaries into such functions.
For example, a function to accept a link or list of links and download the web pages could use such variadic arguments, or varargs. Instead of accepting a single value that is expected to be a list of links, we can accept an arbitrary number of arguments, where each argument is a different link. We do this by specifying the * operator in the function definition:
def get_pages(*links):
for link in links:
#download the link with urllib
print(link)
The *links parameter says "I'll accept any number of arguments and put them all in a list named links". If we supply only one argument, it'll be a list with one element; if we supply no arguments, it'll be an empty list. Thus, all these function calls are valid:
get_pages()
get_pages('http://www.archlinux.org')
get_pages('http://www.archlinux.org',
'http://ccphillips.net/')
We can also accept arbitrary keyword arguments. These arrive into the function as a dictionary. They are specified with two asterisks (as in **kwargs) in the function declaration. This tool is commonly used in configuration setups. The following class allows us to specify a set of options with default values:
class Options:
default_options = {
'port': 21,
'host': 'localhost',
'username': None,
'password': None,
'debug': False,
}
def __init__(self, **kwargs):
self.options = dict(Options.default_options)
self.options.update(kwargs)
def __getitem__(self, key):
return self.options[key]
All the interesting stuff in this class happens in the init method. We have a dictionary of default options and values at the class level. The first thing the init method does is make a copy of this dictionary. We do that instead of modifying the dictionary directly in case we instantiate two separate sets of options. (Remember, class-level variables are shared between instances of the class.) Then, init uses the update method on the new dictionary to change any non-default values to those supplied as keyword arguments. The getitem method simply allows us to use the new class using indexing syntax. Here's a session demonstrating the class in action:
>>> options = Options(username="dusty", password="drowssap",
debug=True)
>>> options['debug']
True
>>> options['port']
21
>>> options['username']
'dusty'
We're able to access our options instance using dictionary indexing syntax, and the dictionary includes both default values and the ones we set using keyword arguments.
The keyword argument syntax can be dangerous, as it may break the "explicit is better than implicit" rule. In the preceding example, it's possible to pass arbitrary keyword arguments to the Options initializer to represent options that don't exist in the default dictionary. This may not be a bad thing, depending on the purpose of the class, but it makes it hard for someone using the class to discover what valid options are available. It also makes it easy to enter a confusing typo ("Debug" instead of "debug", for example) that adds two options where only one should have existed.
Keyword arguments are also very useful when we need to accept arbitrary arguments to pass to a second function, but we don't know what those arguments will be. We saw this in action in Chapter 3, When Objects Are Alike, when we were building support for multiple inheritance. We can, of course, combine the variable argument and variable keyword argument syntax in one function call, and we can use normal positional and default arguments as well. The following example is somewhat contrived, but demonstrates the four types in action:
import shutil
import os.path
def augmented_move(target_folder, *filenames,
verbose=False, **specific):
'''Move all filenames into the target_folder, allowing
specific treatment of certain files.'''
def print_verbose(message, filename):
'''print the message only if verbose is enabled'''
if verbose:
print(message.format(filename))
for filename in filenames:
target_path = os.path.join(target_folder, filename)
if filename in specific:
if specific[filename] == 'ignore':
print_verbose("Ignoring {0}", filename)
elif specific[filename] == 'copy':
print_verbose("Copying {0}", filename)
shutil.copyfile(filename, target_path)
else:
print_verbose("Moving {0}", filename)
shutil.move(filename, target_path)
This example will process an arbitrary list of files. The first argument is a target folder, and the default behavior is to move all remaining non-keyword argument files into that folder. Then there is a keyword-only argument, verbose, which tells us whether to print information on each file processed. Finally, we can supply a dictionary containing actions to perform on specific filenames; the default behavior is to move the file, but if a valid string action has been specified in the keyword arguments, it can be ignored or copied instead. Notice the ordering of the parameters in the function; first the positional argument is specified, then the *filenames list, then any specific keyword-only arguments, and finally, a **specific dictionary to hold remaining keyword arguments.
We create an inner helper function, print_verbose, which will print messages only if the verbose key has been set. This function keeps code readable by encapsulating this functionality into a single location.
In common cases, assuming the files in question exist, this function could be called as:
>>> augmented_move("move_here", "one", "two")
This command would move the files one and two into the move_here directory, assuming they exist (there's no error checking or exception handling in the function, so it would fail spectacularly if the files or target directory didn't exist). The move would occur without any output, since verbose is False by default.
If we want to see the output, we can call it with:
>>> augmented_move("move_here", "three", verbose=True)
Moving three
This moves one file named three, and tells us what it's doing. Notice that it is impossible to specify verbose as a positional argument in this example; we must pass a keyword argument. Otherwise, Python would think it was another filename in the *filenames list.
If we want to copy or ignore some of the files in the list, instead of moving them, we can pass additional keyword arguments:
>>> augmented_move("move_here", "four", "five", "six",
four="copy", five="ignore")
This will move the sixth file and copy the fourth, but won't display any output, since we didn't specify verbose. Of course, we can do that too, and keyword arguments can be supplied in any order:
>>> augmented_move("move_here", "seven", "eight", "nine",
seven="copy", verbose=True, eight="ignore")
Copying seven
Ignoring eight
Moving nine
Unpacking arguments
There's one more nifty trick involving variable arguments and keyword arguments. We've used it in some of our previous examples, but it's never too late for an explanation. Given a list or dictionary of values, we can pass those values into a function as if they were normal positional or keyword arguments. Have a look at this code:
def show_args(arg1, arg2, arg3="THREE"):
print(arg1, arg2, arg3)
some_args = range(3)
more_args = {
"arg1": "ONE",
"arg2": "TWO"}
print("Unpacking a sequence:", end=" ")
show_args(*some_args)
print("Unpacking a dict:", end=" ")
show_args(**more_args)
Here's what it looks like when we run it:
Unpacking a sequence: 0 1 2
Unpacking a dict: ONE TWO THREE
The function accepts three arguments, one of which has a default value. But when we have a list of three arguments, we can use the * operator inside a function call to unpack it into the three arguments. If we have a dictionary of arguments, we can use the ** syntax to unpack it as a collection of keyword arguments.
This is most often useful when mapping information that has been collected from user input or from an outside source (for example, an Internet page or a text file) to a function or method call.
Remember our earlier example that used headers and lines in a text file to create a list of dictionaries with contact information? Instead of just adding the dictionaries to a list, we could use keyword unpacking to pass the arguments to the init method on a specially built Contact object that accepts the same set of arguments. See if you can adapt the example to make this work.
Programming languages that overemphasize object-oriented principles tend to frown on functions that are not methods. In such languages, you're expected to create an object to sort of wrap the single method involved. There are numerous situations where we'd like to pass around a small object that is simply called to perform an action. This is most frequently done in event-driven programming, such as graphical toolkits or asynchronous servers; we'll see some design patterns that use it in Chapter 10, Python Design Patterns I and Chapter 11, Python Design Patterns II.
In Python, we don't need to wrap such methods in an object, because functions already are objects! We can set attributes on functions (though this isn't a common activity), and we can pass them around to be called at a later date. They even have a few special properties that can be accessed directly. Here's yet another contrived example:
def my_function():
print("The Function Was Called")
my_function.description = "A silly function"
def second_function():
print("The second was called")
second_function.description = "A sillier function."
def another_function(function):
print("The description:", end=" ")
print(function.description)
print("The name:", end=" ")
print(function.__name__)
print("The class:", end=" ")
print(function.__class__)
print("Now I'll call the function passed in")
function()
another_function(my_function)
another_function(second_function)
If we run this code, we can see that we were able to pass two different functions into our third function, and get different output for each one:
The description: A silly function
The name: my_function
The class: <class 'function'>
Now I'll call the function passed in
The Function Was Called
The description: A sillier function.
The name: second_function
The class: <class 'function'>
Now I'll call the function passed in
The second was called
We set an attribute on the function, named description (not very good descriptions, admittedly). We were also able to see the function's name attribute, and to access its class, demonstrating that the function really is an object with attributes. Then we called the function by using the callable syntax (the parentheses).
The fact that functions are top-level objects is most often used to pass them around to be executed at a later date, for example, when a certain condition has been satisfied. Let's build an event-driven timer that does just this:
import datetime
import time
class TimedEvent:
def __init__(self, endtime, callback):
self.endtime = endtime
self.callback = callback
def ready(self):
return self.endtime <= datetime.datetime.now()
class Timer:
def __init__(self):
self.events = []
def call_after(self, delay, callback):
end_time = datetime.datetime.now() + \
datetime.timedelta(seconds=delay)
self.events.append(TimedEvent(end_time, callback))
def run(self):
while True:
ready_events = (e for e in self.events if e.ready())
for event in ready_events:
event.callback(self)
self.events.remove(event)
time.sleep(0.5)
In production, this code should definitely have extra documentation using docstrings! The call_after method should at least mention that the delay parameter is in seconds, and that the callback function should accept one argument: the timer doing the calling.
We have two classes here. The TimedEvent class is not really meant to be accessed by other classes; all it does is store endtime and callback. We could even use a tuple or namedtuple here, but as it is convenient to give the object a behavior that tells us whether or not the event is ready to run, we use a class instead.
The Timer class simply stores a list of upcoming events. It has a call_after method to add a new event. This method accepts a delay parameter representing the number of seconds to wait before executing the callback, and the callback function itself: a function to be executed at the correct time. This callback function should accept one argument.
The run method is very simple; it uses a generator expression to filter out any events whose time has come, and executes them in order. The timer loop then continues indefinitely, so it has to be interrupted with a keyboard interrupt (Ctrl + C or Ctrl + Break). We sleep for half a second after each iteration so as to not grind the system to a halt.
The important things to note here are the lines that touch callback functions. The function is passed around like any other object and the timer never knows or cares what the original name of the function is or where it was defined. When it's time to call the function, the timer simply applies the parenthesis syntax to the stored variable.
Here's a set of callbacks that test the timer:
from timer import Timer
import datetime
def format_time(message, *args):
now = datetime.datetime.now().strftime("%I:%M:%S")
print(message.format(*args, now=now))
def one(timer):
format_time("{now}: Called One")
def two(timer):
format_time("{now}: Called Two")
def three(timer):
format_time("{now}: Called Three")
class Repeater:
def __init__(self):
self.count = 0
def repeater(self, timer):
format_time("{now}: repeat {0}", self.count)
self.count += 1
timer.call_after(5, self.repeater)
timer = Timer()
timer.call_after(1, one)
timer.call_after(2, one)
timer.call_after(2, two)
timer.call_after(4, two)
timer.call_after(3, three)
timer.call_after(6, three)
repeater = Repeater()
timer.call_after(5, repeater.repeater)
format_time("{now}: Starting")
timer.run()
This example allows us to see how multiple callbacks interact with the timer. The first function is the format_time function. It uses the string format method to add the current time to the message, and illustrates variable arguments in action. The format_time method will accept any number of positional arguments, using variable argument syntax, which are then forwarded as positional arguments to the string's format method. After this, we create three simple callback methods that simply output the current time and a short message telling us which callback has been fired.
The Repeater class demonstrates that methods can be used as callbacks too, since they are really just functions. It also shows why the timer argument to the callback functions is useful: we can add a new timed event to the timer from inside a presently running callback. We then create a timer and add several events to it that are called after different amounts of time. Finally, we start the timer running; the output shows that events are run in the expected order:
02:53:35: Starting
02:53:36: Called One
02:53:37: Called One
02:53:37: Called Two
02:53:38: Called Three
02:53:39: Called Two
02:53:40: repeat 0
02:53:41: Called Three
02:53:45: repeat 1
02:53:50: repeat 2
02:53:55: repeat 3
02:54:00: repeat 4
Python 3.4 introduces a generic event-loop architecture similar to this. We'll be discussing it later in Chapter 13, Concurrency.
Using functions as attributes One of the interesting effects of functions being objects is that they can be set as callable attributes on other objects. It is possible to add or change a function to an instantiated object:
class A:
def print(self):
print("my class is A")
def fake_print():
print("my class is not A")
a = A()
a.print()
a.print = fake_print
a.print()
This code creates a very simple class with a print method that doesn't tell us anything we didn't know. Then we create a new function that tells us something we don't believe.
When we call print on an instance of the A class, it behaves as expected. If we then set the print method to point at a new function, it tells us something different:
my class is A
my class is not A
It is also possible to replace methods on classes instead of objects, although in that case we have to add the self argument to the parameter list. This will change the method for all instances of that object, even ones that have already been instantiated. Obviously, replacing methods like this can be both dangerous and confusing to maintain. Somebody reading the code will see that a method has been called and look up that method on the original class. But the method on the original class is not the one that was called. Figuring out what really happened can become a tricky, frustrating debugging session.
It does have its uses though. Often, replacing or adding methods at run time (called monkey-patching) is used in automated testing. If testing a client-server application, we may not want to actually connect to the server while testing the client; this may result in accidental transfers of funds or embarrassing test e-mails being sent to real people. Instead, we can set up our test code to replace some of the key methods on the object that sends requests to the server, so it only records that the methods have been called.
Monkey-patching can also be used to fix bugs or add features in third-party code that we are interacting with, and does not behave quite the way we need it to. It should, however, be applied sparingly; it's almost always a "messy hack". Sometimes, though, it is the only way to adapt an existing library to suit our needs.
Callable objects Just as functions are objects that can have attributes set on them, it is possible to create an object that can be called as though it were a function.
Any object can be made callable by simply giving it a call method that accepts the required arguments. Let's make our Repeater class, from the timer example, a little easier to use by making it a callable:
class Repeater:
def __init__(self):
self.count = 0
def __call__(self, timer):
format_time("{now}: repeat {0}", self.count)
self.count += 1
timer.call_after(5, self)
timer = Timer()
timer.call_after(5, Repeater())
format_time("{now}: Starting")
timer.run()
This example isn't much different from the earlier class; all we did was change the name of the repeater function to call and pass the object itself as a callable. Note that when we make the call_after call, we pass the argument Repeater(). Those two parentheses are creating a new instance of the class; they are not explicitly calling the class. This happens later, inside the timer. If we want to execute the call method on a newly instantiated object, we'd use a rather odd syntax: Repeater()(). The first set of parentheses constructs the object; the second set executes the call method. If we find ourselves doing this, we may not be using the correct abstraction. Only implement the call function on an object if the object is meant to be treated like a function.