LogScale Query Building Blocks - CrowdStrike/logscale-community-content GitHub Wiki
Greetings! This guide is composed of "foundational building blocks" and is meant to act as learning examples for the CrowdStrike Query Language, aka CQL. The official LogScale documentation page can be found here:
| !cidr(LocalAddressIP4, subnet=["224.0.0.0/4", "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "127.0.0.0/8", "169.254.0.0/16", "0.0.0.0/32"])
| !cidr(RemoteAddressIP4, subnet=["224.0.0.0/4", "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "127.0.0.0/8", "169.254.0.0/16", "0.0.0.0/32"])
| regex("(?<ip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3})\:(?<port>\d{2,5})", field=CommandLine)
| ipLocation(field=aip)
| UserIsAdmin match {
1 => UserIsAdmin := "True" ;
0 => UserIsAdmin := "False" ;
}
| replace(field=UserIsAdmin, regex="1", with="True")
| replace(field=UserIsAdmin, regex="0", with="False")
// Ignore RFC1918-ish IP address on the "src_ip" field.
!cidr(src_ip, subnet=["224.0.0.0/4", "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "127.0.0.0/8", "169.254.0.0/16", "0.0.0.0/32"])
// Perform the lookup. The strict option only returns matches.
| ioc:lookup(src_ip, type=ip_address, confidenceThreshold=unverified, strict=true)
// Ensure the domain name has a . somewhere.
DomainName=/\./
// Ignore certain domain types.
| DomainName!=/(\.local?.$|\.arpa?.$|_|\.localmachine$)/i
// Put everything in lowecase.
| DomainName:=lower(DomainName)
// Look for IOCs in DNS. The strict option only returns matches.
| ioc:lookup(field=DomainName, type=domain, confidenceThreshold=unverified, strict=true)
// Ensure it's all lowercase.
url:=lower(url)
// Perform a lookup on the URL. The strict option only returns matches.
| ioc:lookup(field=url, type=url, confidenceThreshold=unverified, strict=true)
This can be done by utilizing case {} statements and comparing the @timestamp field. You'll still need to do a 60-day query since the query will encompass all results. It'll look like this:
// Run this query over the last 60 days.
#event_simpleName = ProcessRollup2
| case {
test(@timestamp < (start()+(30*24*60*60*1000))) | eventSize(as=eventSize31to60);
* | eventSize(as=eventSize0to30);
}
| stats([avg(as=avg31to60, field=eventSize31to60), avg(as=avg0to30, field=eventSize0to30)])
- The first line is a basic filter looking for
ProcessRollup2events. - The next line is a simple case statement. It says "if the
@timestampis older than 30 days ago, save the event size in theeventSize31to60variable. - The second part of the case statement says "everything else gets the event size saved as the
eventSize0to30variable. - The last part grabs the average of both of them and displays them as the output.
The end results looks like this:
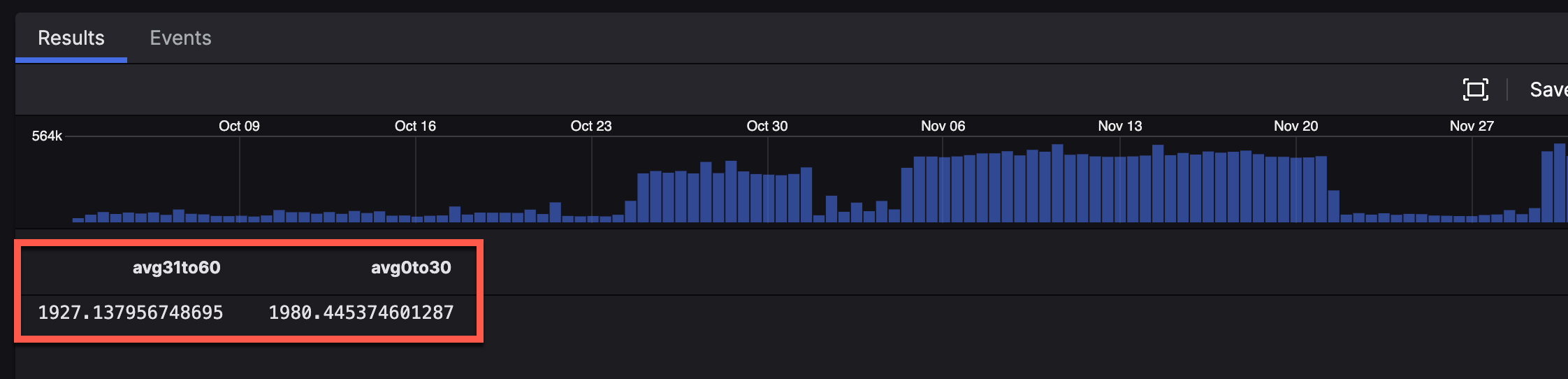
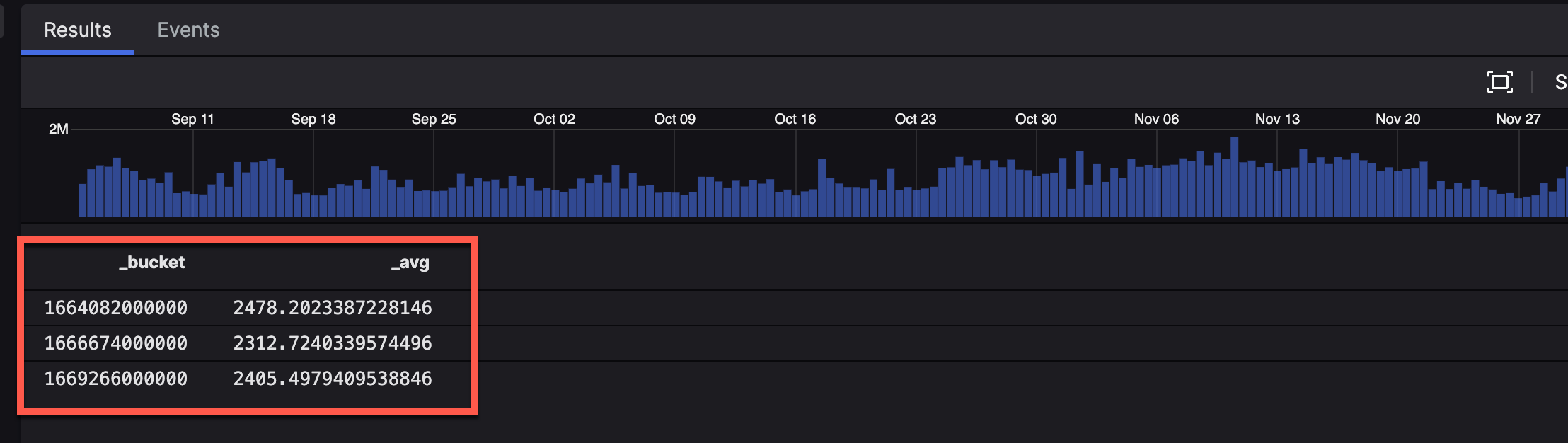
This can also be accomplished via the bucket() function. The bucket size should be divided by the number of values you'd like to compare. For example, if you're looking at 3 30-day windows over 90 days, each bucket should be 30 days. Please note that you might need to lower the search timeframe if you end up with an extra bucket, e.g. change it to 89 days if you specify a 30-day bucket but end up with 4 buckets. The query looks like this:
thisSize := eventSize()
| bucket(span=30d, function=avg(thisSize))
Let's say you have two fields you'd like to average and pass to a timechart() function. However, both functions will create an _avg field. This causes timechart() to generate an error about two events having the same field but different values. The solution is to rename the fields that are generated by the avg() function:
timechart(function=[avg(ConfigStateHash, as=avgConfigStateHash), avg(ConnectTime, as=avgConnectTime)])
This creates two averages, avgConfigStateHash and avgConnectTime, and then passes them into the timechart() function.
#event_simpleName=ProcessRollup2
| groupBy([ParentBaseFileName], function=count(as=count), limit=max)
| [sum(count, as=total), sort(field=count, order=ascending, limit=10)]
| percent := 100 * (count / total)
The wildcard() function was added in the 1.102.0 release of LogScale. This function can be used for case-insensitive user inputs.
// The ?variable will create an input box.
// Feed that directly into the wildcard() match.
// Please note the =~ which is the same as "field" parameter.
user.email=~wildcard(?Username, ignoreCase=true)
The above says "check ?Username against user.email and make it case-insensitive".
Note: this is a legacy method. The wildcard() function is much easier.
User inputs can be created by putting a ? in front of the input name, e.g. ?username would create a username input. You'll see these in dashboards, but they can also be used in queries. The inputs are case-sensitive by default. This means that an input of "ADministrator" would not match "administrator", "Administrator, etc. The solution is to use the test() function and compare everything in lowercase. For example:
// The input is "?MyInput" and we want to match it to "UserName".
// First we have to assign the input to a field, otherwise it doesn't work with test().
thisInput:=?MyInput
// Next we compare the two strings in lower-case to see if they're equal.
test(lower(thisInput) == lower(UserName))
Because we're comparing everything in lowercase, an input of "administrator" would match "Administrator", "ADMinistrator", "AdMiNiSTRATOR", etc.
Note: this is a legacy method. The wildcard() function is much easier.
Another example of this is when we have multiple inputs, e.g. ?ComputerName, ?aid, and ?cid. Let's say we only need ?ComputerName to be case-insensitive. It'd look like this:
// Assign a different name for the variable.
| inputComputerName:=?ComputerName
// If it's a "*" then keep it, if it's blank use a "*", otherwise do a case-insensitive match.
| case {
test(?ComputerName == "*")
| ComputerName = ?ComputerName ;
test(?ComputerName == "")
| ComputerName = * ;
test(lower(inputComputerName) == lower(ComputerName)) ;
}
// Check the last two strings, no reason to look at case.
| AgentIdString = ?aid AND CustomerIdString = ?cid
Let's say you want to display the relationship between the ParentBaseFileName, FileName, and RawProcessId. You can use the format() function to display these similar to a process tree. Take the following query as an example:
#event_simpleName = ProcessRollup2 event_platform = Win ParentBaseFileName = "explorer.exe"
| ImageFileName = /(\\Device\\HarddiskVolume\d+)?(?<FilePath>\\.+\\)(?<FileName>.+$)/
| ExecutionChain := format(format="%s\n\t└ %s (%s)", field=[ParentBaseFileName, FileName, RawProcessId])
| select(ExecutionChain)
The format() line will format the output to this:
explorer.exe
└ SecurityHealthSystray.exe (5700)
The documentation lists a few different methods. By far, the easiest way is to use the := shorthand. The field before := will be assigned the value of whatever is after it. This can be other fields, functions, strings, etc. For example, if bytes already has a byte count and you'd like to convert that to megabytes:
megabytes := bytes * 0.000001
If you'd like to have thisBytes created and assigned the value of thatBytes:
thisBytes := thatBytes
If you'd like to find the average string length of @rawstring:
eventLength := length(@rawstring)
| avg(eventLength)
Keep in mind there fields and values are dynamic. They do not exist outside of the query results, and will not be permanently added to the ingested logs.
The format() function is extremely powerful. It allows you to manipulate data using printf formatting. The round() function rounds to the nearest integer and does not include decimals.
This example will round the value of thatSize and save it to the field thisSize with two decimal places.
thisSize := format("%.2f", field = thisSize)
%.1f would be 1 decimal place, %.3f would be 3 decimal places, etc.
The format() function can be used to create dynamic URLs, e.g. a URL that takes a value from the search results as an input. This saves the user from needing to copy and paste into another browser tab. For example:
format("[Link](https://example.com/%s)", field=repo, as=link)
This says "generate a markdown URL that shows up as link in the results, with the %s being replaced by the value of the repo field".
| Status_hex := format(field=Status, "%x")
Let's say you have the following event:
45.513466,-122.75999,2023-01-31 23:59:45.559,"Golden-Crowned Sparrow,Pine Siskin"
You'd like to split this into two events, one for each bird. This can be done using a combination of parseCsv, splitString, and split.
// First create the event for testing.
createEvents("45.513466,-122.75999,2023-01-31 23:59:45.559,\"Golden-Crowned Sparrow,Pine Siskin\"")
// Next parse it out as a CSV.
| parseCsv(columns=[lat, long, date, birdname])
// Then, using regex, return all the bird names in the birdname field as seperate events
| birdname=/(?<birdname>[^,]+)/g
// Then drop the @rawstring since you no longer need it.
drop(@rawstring)
🐦 🐦
By default, the parseJson() function will turn an array into separate fields. Let's say you have this:
{
"HostnameField":"SE-CPE-RDP",
"Commands": [
"runscript -Raw=```Get-ChildItem .\n```",
"pwd",
"update list",
"update history"
],
"UTCTimestamp":1694553805000
}
You'd end up with the following fields:
Commands[0]
Commands[1]
Commands[2]
Commands[3]
Let's say you want to recombine those into a single field, with each value separated by a \n. Meet the concatArray() function:
// Quick filter that we know will bring back an array.
#streamingApiEvent=Event_RemoteResponseSessionEndEvent
// Recombine the "Commands[]" values as "commandsArray" and separate them all by a new line character.
| concatArray(Commands, as=commandsArray, separator="\n")
// Display the results.
| select([@timestamp, HostnameField, commandsArray])
Example output:

Let's say you need to use groupBy() for aggregation, but also need to include fields such as the aid, aip, event_simpleName, etc. This is where the stats() and collect() functions come into play.
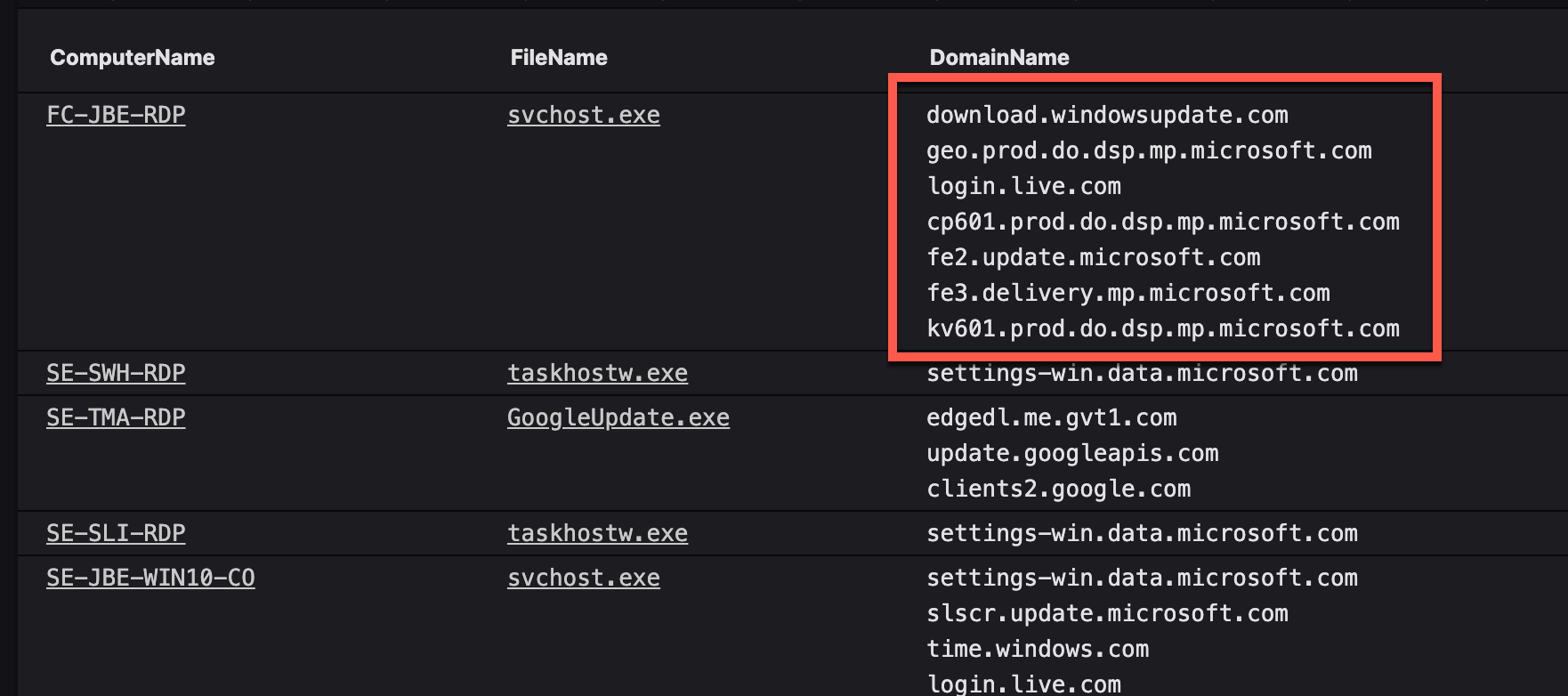
Here's a simple example of adding DomainName to the results of grouping by ComputerName and FileName. This says "group everything by unique pairs of ComputerName and FileName, and then collect all of the DomainName values from each of those unique pairings.
groupBy([ComputerName, FileName], function=collect(DomainName))
The results look like this:
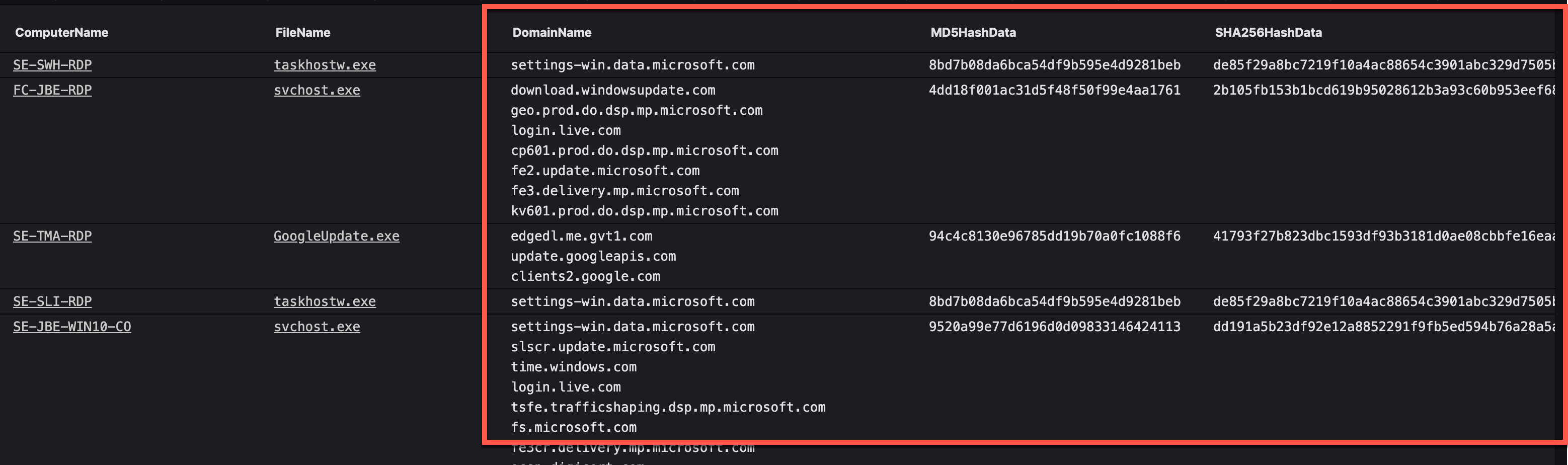
Instead of the example above, you'd like to collect multiple fields instead of just one. The correct way of doing this is by using an array:
groupBy([ComputerName, FileName], function=collect([DomainName, MD5HashData, SHA256HashData]))
Notice the [ ... ]? That says "pass all of these into the function, and display the output". This is the result:
By default, groupBy() without a function= argument includes a count() function. The result is the groupby() results have a _count field that displays the total count for each aggregation. However, once you add a function= to that, the count() is no longer in the results. The solution? Simply add the count() function into an array.
groupBy(ComputerName, function=[collect(DomainName), count()])
The results now include count() and look like this:
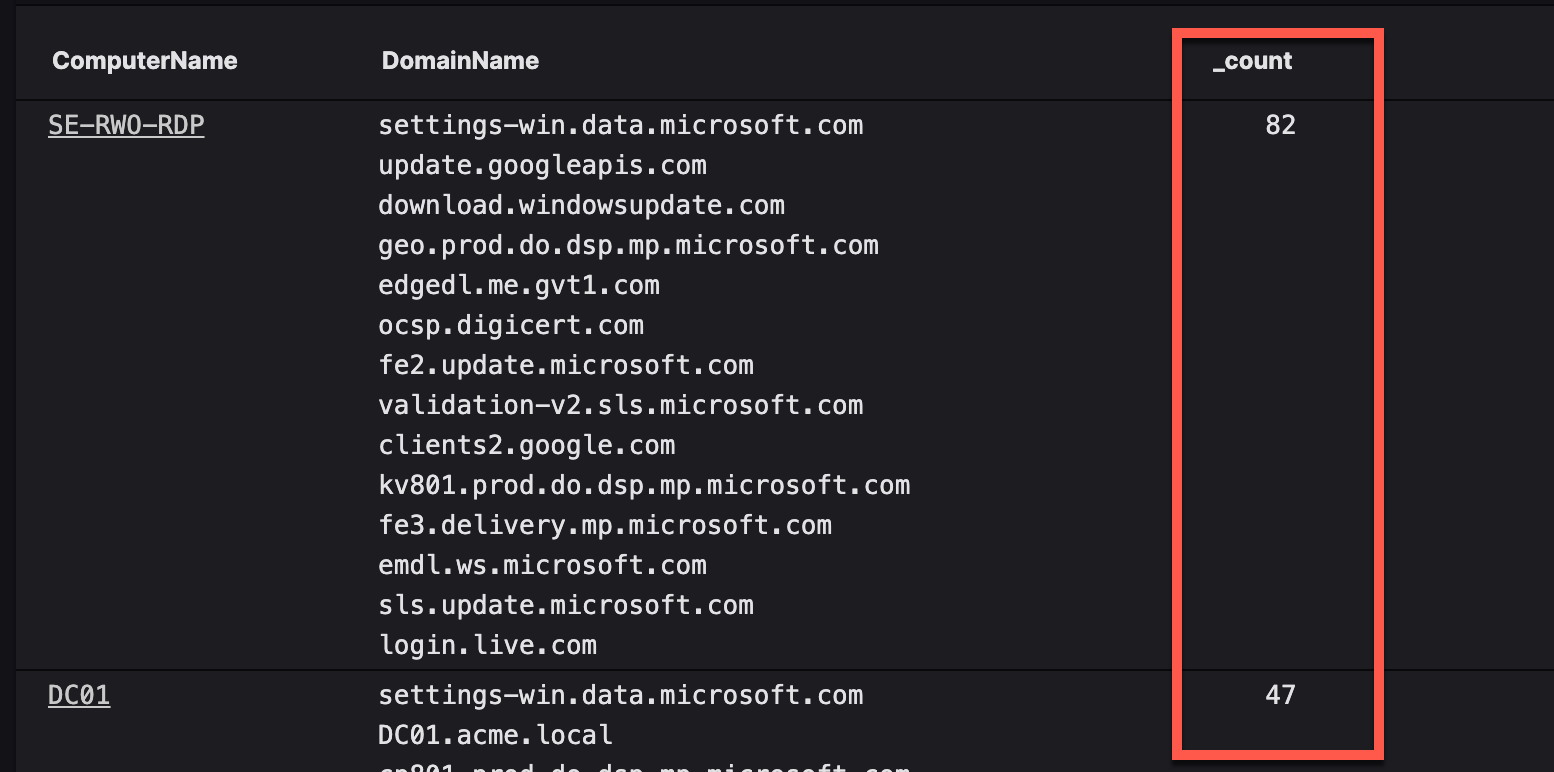
The groupBy() function removes the @timestamp field by default. This generally doesn't matter unless you're trying to use something like timechart() which requires @timestamp to work correctly.
groupBy(ComputerName, function=selectLast(@timestamp))
| timechart(ComputerName)
If you need to include other fields along with the timestamp, you can pass them all in an array:
groupBy(ComputerName, function=[collect([UserName, DomainName]), selectLast(@timestamp)])
| timechart(ComputerName)
Let's say you're doing a groupBy() for a particular event, but you'd like to see the time of the first and last occurrence in the results. You'd do this:
groupBy(UserName, function=[max(@timestamp, as=lastSeen), min(@timestamp, as=firstSeen)])
| firstSeen:=formatTime(field=firstSeen, format="%Y/%m/%d %H:%M:%S")
| lastSeen:=formatTime(field=lastSeen, format="%Y/%m/%d %H:%M:%S")
Keep in mind that @timestamp is epoch, which means you can basically search for the "smallest" which is the oldest, or the "largest" which is the most recent. That query says "group the results by UserName, find the smallest/oldest timestamp, find the largest/newest timestamp, and then reformat the epoch times into something readable."
LogScale is able to deal with most time zone situations. Two major items to keep in mind:
- Everything internal to LogScale is based around UTC.
- Logs in the UI are displayed relative to the local time zone reported by the browser, i.e. UTC is converted to the user's local time.
Further details on how LogScale leverages different time-related fields:
-
@rawstringgenerally includes some type of timestamp, e.g. a syslog header. -
@timestampis the time field used for everything by default. This is in UTC.- If the parser can grab the time out of
@rawstring, then it's converted to UTC and stored as@timestamp. This leverages the time zone specified in the logs. - If the time zone is not specified in the log, e.g. it's local time but does not include a time zone, then by default it's assumed it be UTC. This can cause events with a broken timestamp to appear "in the future", e.g. GMT-5 without a time zone would be logged 5 hours ahead.
- If the parser can grab the time out of
-
@ingesttimestampis the time in UTC that the event was ingested by LogScale. - If a timestamp can't be found, then
@timestampis set as the@ingesttimestamp. -
@timestamp.nanosis the nanoseconds that are sometimes included in certain timestamps. -
@timezoneis the assumed time zone that was parsed from the logs.
The timestamp is handled by the parser assigned to the ingest token. These are primarily findTimestamp() and parseTimestamp(). The findTimestamp() function is generally the "easy" function but assumes the event has a correct timestamp. The parseTimestamp() function allows you to be extremely specific about the time format and time zone. For example, let's say you have logs that were being sent over in Eastern time but didn't include a time zone:
parseTimestamp("MMM [ ]d HH:mm:ss", field=@timestamp, timezone="America/NewYork")
This says "parse the @timestamp field in that particular format, and assume it's in the America/NewYork time zone". Plenty of examples are included in the default parsers.
| PasswordLastSet := PasswordLastSet*1000
| PasswordLastSet := formatTime("%Y-%m-%d %H:%M:%S", field=PasswordLastSet, locale=en_US, timezone=Z)
Not all FDR events include a ComputerName or UserName field by default. In those cases, we can add the fields at query time. Version 1.1.1 of the FDR package includes a scheduled search that creates a CSV lookup file every 3 hours. You can find this file by clicking on the Files link at the top of the LogScale page. You should see fdr_aidmaster.csv in the file list, assuming the scheduled search is running as expected.
The CSV is used to look up the ComputerName from the aid via the match() function. You would simply add this to your query:
| match(file="fdr_aidmaster.csv", field=aid, include=ComputerName, ignoreCase=true, strict=false)
A more robust version can be saved as a search, and the saved search referenced in subsequent queries as a user function:
// First look for ones missing a ComputerName.
| case {
// Identify any events that have an aid but not a ComputerName.
// Neither of these overwrite the value if it already exists.
aid=* AND ComputerName!=*
// Grab the ComputerName from the aidmaster file.
| match(file="fdr_aidmaster.csv", field=aid, include=ComputerName, ignoreCase=true, strict=true);
// Assign the value NotMatched to anything else.
* | default(field=ComputerName, value=NotMatched);
}
If that were saved as AddComputerName, then it could be called in a query by using $"AddComputerName"().
The UserName field can be added via a join() query. This will also show the last known user on the aid in question. Keep that in mind if there are multiple users over an extended timeframe, i.e. it will only be reporting the last user.
| join({#event_simpleName=UserLogon}, field=aid, include=UserName, mode=left)
A more robust version of this is included in the package linked above. It can also be called as a function, and is included in several of the example queries.
// Grab the UserName. This excludes any of the generic Windows usernames.
default(field=UserName, value="NotMatched")
| join({#event_simpleName=UserLogon | UserName!=/(\$$|^DWM-|LOCAL\sSERVICE|^UMFD-|^$)/}, field=aid, include=UserName, mode=left)
LogScale allows you to dynamically create fields using named capture groups. For example, let's say you want to create the field netFlag from certain events, but still pass the results through that don't match. The solution is to add the strict=false flag to the regex() function. This means "extract if it matches, but still pass the data through even if it doesn't match" in the query.
#event_simpleName=ProcessRollup2 event_platform=Win
| ImageFileName=/\\(whoami|net1?|systeminfo|ping|nltest)\.exe/i
| regex("net1?\s+(?<netFlag>\S+)\s+", field=CommandLine, flags=i, strict=false)
Let's say you have a field that contains a markdown URL as the value. You want that displayed as a clickable URL in the groupBy() output. The solution is to remove the field from collect() and place it into a selectLast() instead. Otherwise, you end up collecting multiple URLs into the same field.
| groupBy([aid, ParentProcessId], function=[collect([ComputerName, UserName, ParentProcessId, ParentBaseFileName, FileName, CommandLine], limit=10000), count(FileName, as="FileNameCount"), count(CommandLine, as="CommandLineCount"), selectLast("Process Explorer")], limit=max)
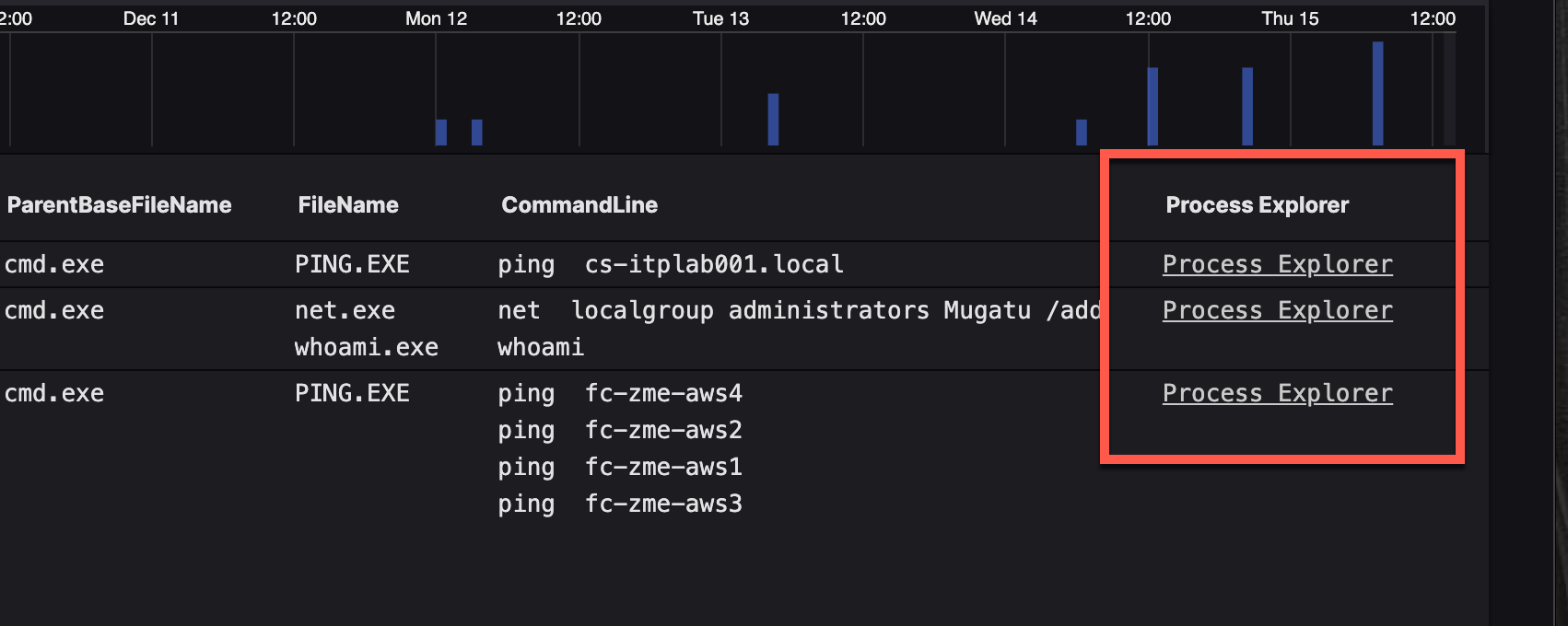
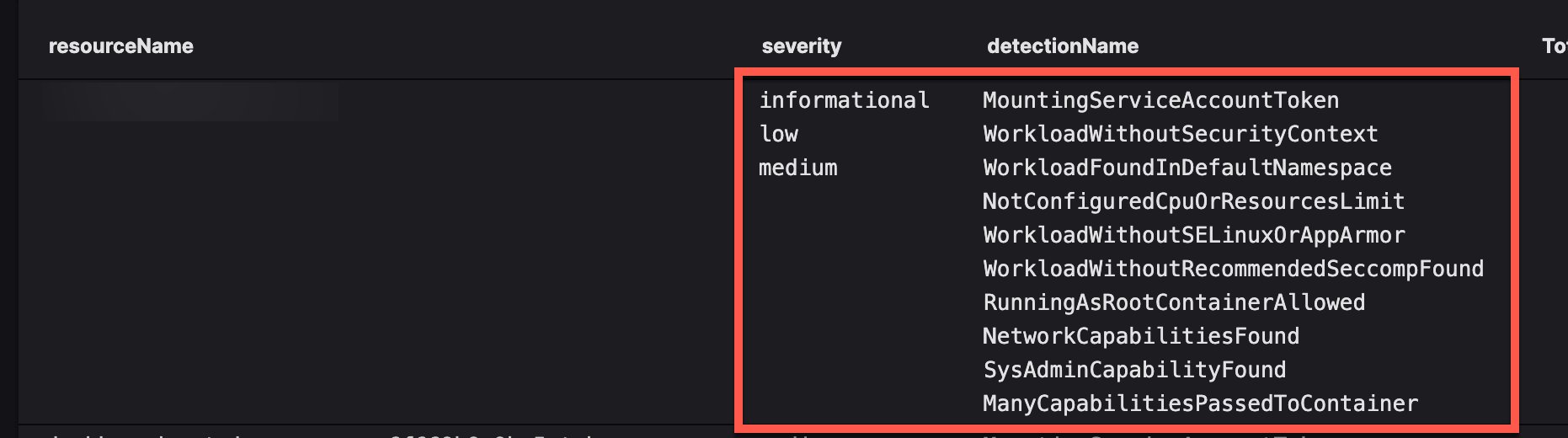
It's common to use collect() as a function with groupBy() to grab other values. However, you'll occasionally hit a situation where one doesn't line up with the other, e.g. there are only two severity values but a dozen detectName values. For example:
#kind=Primary
| eventType=K8SDetectionEvent
| groupBy(resourceName, function=[collect(["Detection Type", clusterName], limit=10000), count(as="Total Events")], limit=max)
This results in output similar to this:
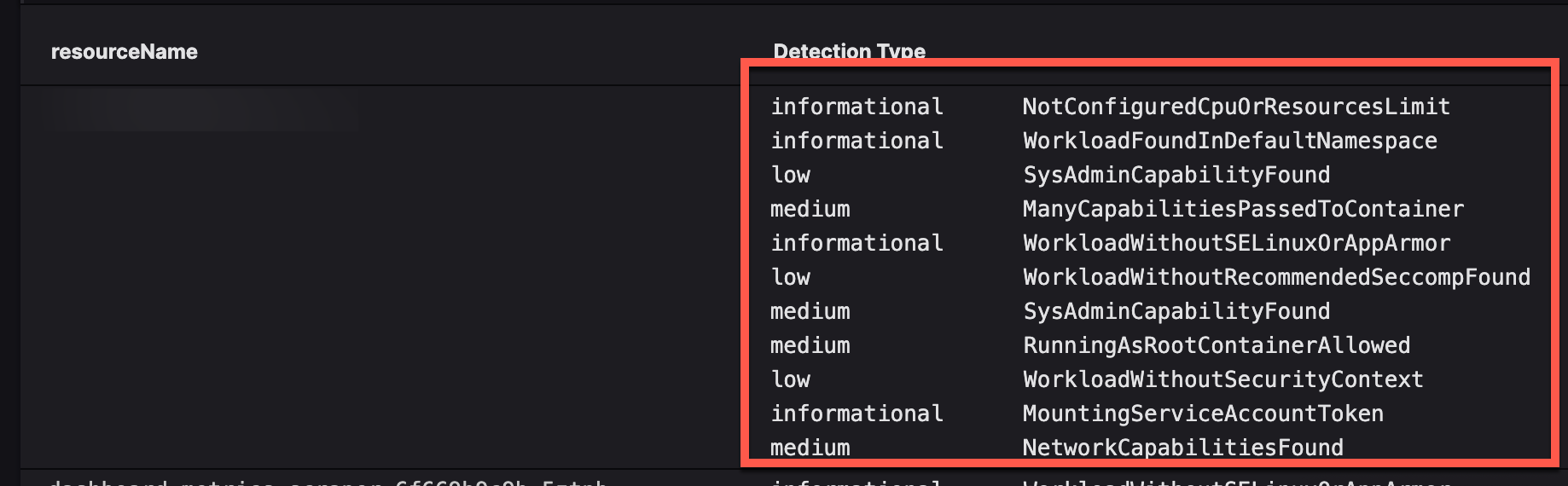
Instead, you'd like the severity aligned with the detectionName in the query results. This is where format() can be used to add "left-aligned right-padded" columns that combine the two values:
#kind=Primary
| eventType=K8SDetectionEvent
// The first value is the severity padded to 18 spaces, followed by the detectionName.
| "Detection Type":=format("%-18s %s", field=[severity, detectionName])
| groupBy(resourceName, function=[collect(["Detection Type", clusterName], limit=10000), count(as="Total Events")], limit=max)
| sort("Total Events", limit=10000)
The format() line says "pad the first value until it's 18 characters wide". You now end up with this:
| default(field=GrandParentBaseFileName, value="Unknown")
| format(format="%s > %s > %s", field=[GrandParentBaseFileName, ParentBaseFileName, FileName], as="processLineage")
#event_simpleName=UserLogon LogonType=10 RemoteAddressIP4=*
| !cidr(RemoteAddressIP4, subnet=["224.0.0.0/4", "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "127.0.0.0/8", "169.254.0.0/16", "0.0.0.0/32"])
| ipLocation(aip)
| worldMap(ip=aip, magnitude=count(aid))
The join() function is generally used when you have two query results that you'd like to combine, and both results share some common value. There is also a selfJoin() and selfJoinFilter() function for certain situations, both described in the official documentation. Please note the field names can be different: it's the value of those fields that should be identical. Background on the example:
- We want to combine
ProcessRollup2andNetworkListenIP4to find processes that have created a listener on a port. -
ProcessRollup2contains the process information. The field we're using in the results isTargetProcessIdto designate the ID of the process. -
NetworkListenIP4contains the listener information. Instead ofTargetProcessId, it usesContextProcessId. This also designates the ID of the process. - Both
TargetProcessIdandContextProcessIdshare a common value, e.g. 123456 would represent the same process.
And the join() to combine them:
#event_simpleName=ProcessRollup2
| join({#event_simpleName=NetworkListenIP4 LocalPort<1024 LocalPort!=0}, field=TargetProcessId, key=ContextProcessId, include=[LocalAddressIP4, LocalPort])
What does that query actually mean?
- The first query should be the larger of the two. In this case,
#event_simpleName=ProcessRollup2is the larger query. - The query within
join()should be the smaller of the two queries, and is known as the subquery. It's the query within the{ ... }after thejoin()function. The query is simple enough:#event_simpleName=NetworkListenIP4 LocalPort<1024 LocalPort!=0. - The
field=andkey=are the two fields that share a common value. -
field=is tied to the larger query, i.e.#event_simpleName=ProcessRollup2. This is the fieldTargetProcessIdinProcessRollup2events. -
key=is tied to the smaller query, i.e.#event_simpleName=NetworkListenIP4 LocalPort<1024 LocalPort!=0. This is the fieldContextProcessIdinNetworkListenIP4events. - The
include=[ ... ]is a list of fields that should be pulled from the smaller query into the results.
And a visualization of everything that was just described:

Another example:
- We want to find the
UserNamefrom aUserSidin aProcessRollup2event. - The
ProcessRollup2events only have aUserSid. - The
UserIdentityevents have aUserNameand aUserSid. - The common field between them is
UserSid.
Easy! We just join them together:
// Get the PR2 events.
#event_simpleName=ProcessRollup2
// Only grab the ones with a UserCid.
| UserSid=*
// Join the two together based on the UserSid.
| join({#event_simpleName=UserIdentity}, field=UserSid, include=[UserName], limit=100000)
Let's say you've got detection events, and you'd like them (1) grouped by the field DetectName, (2) put into buckets representing a single day, and (3) display this as a stacked bar chart over 30 days. There are two ways of doing this. Well, there are actually a bunch of different way, but these two are probably the easiest.
This is probably the easier of the two methods. Let's take the following query:
// Filters for these specific event types. Detection events have specific fields.
#event_simpleName!=* OR #streamingApiEvent=Event_DetectionSummaryEvent
| EventType=Event_ExternalApiEvent
| ExternalApiType=Event_DetectionSummaryEvent
// Create a timechart based. Each "bucket" is one day, with a limit of 20 unique DetectName values.
| timechart(series=DetectName, span=1d, limit=20)
But we wanted a stacked bar chart :). Click on the "paintbrush" icon on the right side. Scroll down to "Interpolation" and change the "Type" to "Step after". Done!

This is slightly more involved than the method above, but gives similar results.
// Filters for these specific event types. Detection events have specific fields.
#event_simpleName!=* OR #streamingApiEvent=Event_DetectionSummaryEvent
| EventType=Event_ExternalApiEvent
| ExternalApiType=Event_DetectionSummaryEvent
// Take the @timestamp for each event, convert it into YYYY-MM-DD format, and save it as "dateBucket".
| dateBucket:=formatTime("%Y-%m-%d", field=@timestamp)
// Put the results into the bucket for the day, also grouping by "DetectName".
| groupBy([dateBucket, DetectName], limit=max)
Select "Bar Chart" for the visualization and "Stacked" for the "Type".

Set the time window for this search to 30 days (the search will find the oldest available event, and then format timing message based on timeframe of when that last event seen)
// Recommend setting the time window for this search to 30 days
// selectLast() will keep the field value of the most recent event with that field.
| selectLast([@ingesttimestamp])
| lasteventseentime := @ingesttimestamp
// Get current time
| currenttime := now()
// Compare current time with last time an event seen
| timediff := (currenttime - lasteventseentime)
| timeinmins := timediff/60000 | timeinmins := format(format="%d", field=timeinmins)
| timeinhours := timediff/3600000 | timeinhours := format(format="%d", field=timeinhours)
| timeindays := timediff/86400000 | timeindays := format(format="%d", field=timeindays)
// Case logic to vary output based on how much time has passed
| case {
timeinmins > 30 | timeinmins < 61 | format("No new data in the last %s minutes", field=["timeinminutes"], as=Alert.Name) ;
timeinmins > 60 | timeinhours < 24 | format("No new data in the last %s hours", field=["timeinhours"], as=Alert.Name) ;
timeinhours > 24 | format("No new data in the last %s days", field=["timeindays"], as=Alert.Name) ;
}
If you set your time interval to 24 hours, this will provide a list of log types we saw at least once in the last 24 hours but not in the last 5 minutes. The field #type can be any field that you want to monitor such as host.
| delta := now()
| delta := (delta - @ingesttimestamp) / 60000 // 6000 is ms in a minute
| delta := format(format="%.1f", field=delta)
| groupBy(field=#type, function={selectLast(delta)}, limit=max)
| delta > 5
| delta := now()
| delta := (delta - @ingesttimestamp) / 60000
| delta > 5 // More than 5 minutes ago
| delta := format(format="%.1f", field=delta) // round to 1 decimal
// Filter on authentication events
#event_simpleName=/^(UserLogon|UserLogonFailed2)$/
// Add wildcard filters to reduce the scope if needed.
| wildcard(field=aip, pattern=?AgentIP, ignoreCase=true)
| wildcard(field=aid, pattern=?aid, ignoreCase=true)
| wildcard(field=UserName, pattern=?UserName, ignoreCase=true)
// Add in Computer Name to results. This is not needed in FLTR or FSR.
//| $crowdstrike/fltr-core:zComputerName()
// Add another wildcard filters to reduce the scope if needed.
//| wildcard(field=ComputerName, pattern=?ComputerName, ignoreCase=true)
// Filter out usernames that we don't want to alert on.
| UserName!=/(\$$|^DWM-|LOCAL\sSERVICE|^UMFD-|^$|-|SYSTEM)/
// Make UserNames all lowercase.
| lower(UserName, as=UserName)
// Make working with events easier and setting auth status
| case {
#event_simpleName=UserLogonFailed2
| authStatus:="F" ;
#event_simpleName=UserLogon
| authStatus:="S" ;
}
// Run a series that makes sure everything is in order and starts with a failure and ends with a success within timeframe.
// Change your timeframes here within maxpause and maxduration.
| groupBy([UserName, aip], function=series(authStatus, separator="", endmatch={authStatus=S}, maxpause=15min, maxduration=15min, memlimit=1024), limit=max)
| authStatus=/F*S/i
| failedLoginCount:=length("authStatus")-1
// Set your failed login count threshold here.
| failedLoginCount>=5
// Set the min and max duration for equal or less than above.
// Modify min duration to use the test function similar to max duration if you wish to set anything via human readable vs millisecond format.
| _duration>0
| test(_duration<duration(15min))
// Format time duration to make readable.
| firstAuthSuccess:=@timestamp+_duration
| formatTime(format="%c", as=firstAuthFailure)
| formatTime(field=firstAuthSuccess, format="%c", as=firstAuthSuccess)
| formatDuration(_duration)
| table([UserName, aip, _duration, firstAuthFailure, firstAuthSuccess, failedLoginCount], limit=1000, sortby=failedLoginCount)
Set the time window for this search to 123 days (the search allots for running on the 31st of the current month, and during the extended 3 month ranges including Jan31 and Aug31)
// --------------------------------------------
// NOTICE:
// For this function to work properly, you must search for an ADDITIONAL 33days in your query.
// The additional time is to account for running at any given day within a month, including Jan31 and Aug31.
// Place this function AFTER your primary filter, but before your final groupings.
// You may have to rename Month with a line of `Month := time:month(Month)` after any final sorting.
// See bottom of function for an example.
// --------------------------------------------
// Get the current month time
| currentMonth := now()
//Format so it is exactly 00:00:00 at start of month
| currentMonth := formatTime("%Y-%m-01 00:00:00", field=currentMonth)
// Grab the start of the month of the actual event
| Month := formatTime("%Y-%m-01 00:00:00", field=@timestamp)
// Re-parse the new fields so LogScale knows they are timestamps and not text
| parseTimestamp(field=currentMonth,format="yyyy-MM-dd HH:mm:ss",timezone="Z",as="currentMonth")
| parseTimestamp(field=Month,format="yyyy-MM-dd HH:mm:ss",timezone="Z",as="Month")
// Discard the current month and keep only the previous X months
| diff := currentMonth - Month
| test(currentMonth != Month)
// You can change this value to be your requested timeframe + 1
| test(diff < duration(4mon))
// --------------------------------------------
// You can use this section if you need to adjust timeframes within the month.
// The example below would show you the trend of the first 15 days of each month.
// The first line grabs the timeframe between the timestamp and the first of the month.
// The second line measures the timeframe difference and ensures it is less than 16days (from 00:00:00 of the month).
// This allows the inclusion of up to 25:59:59.999 for the 15th.
// --------------------------------------------
// | MonthDayDiff := @timestamp - Month
// | test(MonthDayDiff < duration(16d))
// --------------------------------------------
//
// Sample example of how to group and rename so prettifies Month Name in visuals
//
// |groupBy([Month,SeverityName],function=count(SeverityName))
// |sort( [Month,SeverityName],order=asc)
// |Month := time:monthName(field=Month)
#event_simpleName=UserLogon
// Filter out Basic UserName that we don't want to alert on.
| UserName!=/(\$$|^DWM-|LOCAL\sSERVICE|^UMFD-|^$|-)/
// Find the 10min sessions by user and collect the IP addresses
| groupBy(UserName, function=[series([aip], separator="\n", maxpause=10min, maxduration=10min, memlimit=1024)], limit=max)
// Filter out single events.
| _duration > 0
| "LastAuth" := @timestamp + _duration
| formatTime(format="%c", as="FirstAuth")
| formatTime(field="LastAuth", format="%c", as="LastAuth")
// Make duration human readable
| formatDuration("_duration")
| splitstring(aip, by="\n", as=aip_split)
| groupby([UserName, FirstAuth, LastAuth, _duration], function=[ {split("aip_split") | collect("aip_split") }], limit=max)
| aip_split=/\n/