TutorialClassicOrVirtualWhat - ConstantB/ontop-spatial GitHub Wiki
So far we have talked about OBDA models and practiced querying these models on-the-fly using Quest in Virtual OBDA mode, . However, this is not the only way to query OBDA models, or the only way to use Quest. We distinguish two core ways to deal with OBDA, what we call classic OBDA and virtual OBDA, now we will elaborate on both of these topics.

Virtual OBDA is the holy grail of data access and data integration with ontologies. In this architecture, data sources and data are sacred, the sources cannot be manipulated, the data cannot be replicated or preprocessed and can only be accessed at query-time. Updates in the data in the source should be reflected immediately in the OBDA system. Changes in the structure of the source are also simple to handle, they only require updates to the mappings of the OBDA model. Space is use optimally, there is no duplication or redundancy, and the OBDA layer works on top of the real sources. All these features make the virtual OBDA an extremely dynamic and flexible architecture.
At the same time, this architecture is very strict and severely restrict the space that the reasoner has for optimizing the query answering process. The system cannot easily cache information, and it must be very careful not to exceed the capacity of the source.
Systems that allow for a virtual OBDA architecture often resource to query rewriting techniques to provide the answers to queries, delegating the execution of these the data source.
Quest supports the virtual OBDA architecture by means of query rewritings, and it delegates all the query execution process to the data source. In virtual OBDA mode, Quest never brings data from the source and sends one single query to the data source. It is a pure virtual OBDA reasoner.
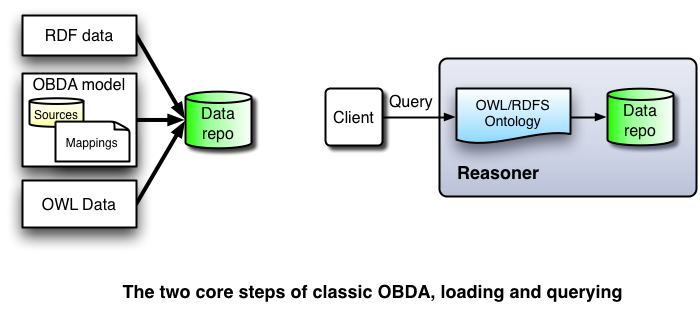
Classic OBDA is the architecture that most of us semantic web developers/users are used to. There is an ontology with data and schema information, and we give it to a reasoner for query answering. The data might have come from a datasource by means of some mappings, or code that extracted it, however, the original source is forgotten. The key aspect of this architecture is that the reasoner is disconnected from the source, the reasoner takes the data from the source and stores this data in a way that is most suitable for the services provided.
Most of us have work or developed in classic OBDA mode. We extract the data, we dump it into an OWL or RDF file, and we load it in our reasoner. If we need to update the data, we do another dump.
This architecture is obviously less dynamic. Updates in the data sources take time to be propagated to the OBDA application. However, it is perfectly acceptable in many use cases, for example, when nightly updates are sufficient, or in data analysis applications.
At the same time, the classic OBDA architecture gives a lot of space for the reasoner engines to perform optimizations and to implement many different reasoning techniques, e.g., query rewriting, forward-chaining, etc.
Quest also supports the classic OBDA context. To provide query answering services it still relies on query rewriting, however, very optimized query rewriting that guarantees very fast query execution cost with no need to do any kind of chasing or forward-chaining on the data.