3주차 3 - CodingInterviewStudy/CrackingTheCodingInterview GitHub Wiki
- 그래프는 정점과 간선의 집합
G=(V, E) -
그래프의 표현방식(G는 그래프, E는 간선, V는 정점)
- 인접리스트 :
E<V^2로 밀도가 낮을 때, 정점간 연결여부 확인 시O(N) - 인접행렬 :
E≥V^2로 밀도가 높을 때, 정점간 열결여부 확인 시O(1)
- 인접리스트 :
-
깊이/넓이우선탐색 : 인접리스트일 때
O(V+E), 인접행렬일 때O(V^2)
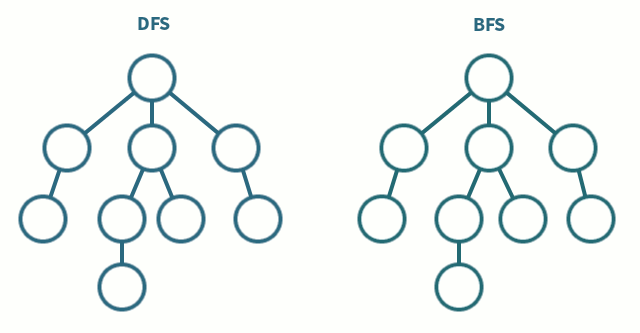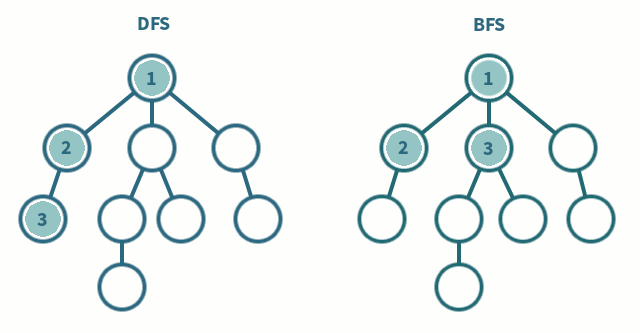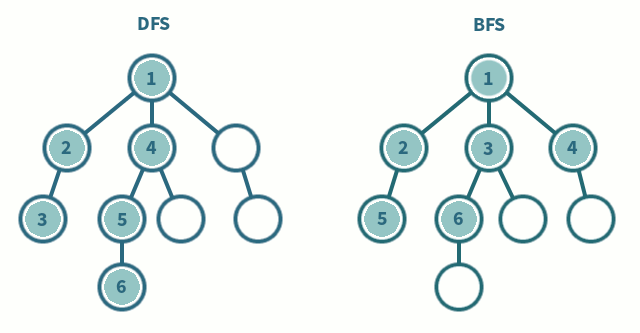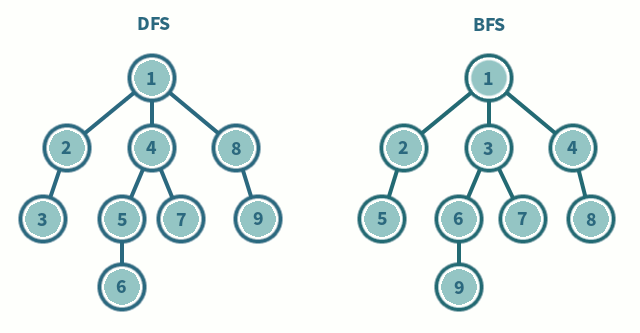
- 그래프의 최단경로 탐색
| 구분 | 시간복잡도 | 특징 |
|---|---|---|
| 깊이/넓이우선탐색 (인접리스트로 구현시) |
O(V+E) |
가중치가 없는 그래프에서 |
| 배열을 활용한 다익스트라 | O(V^2) |
가중치가 있는 그래프에서 |
| 힙/우선순위큐와 다익스트라 | O(ElogV) |
〃 |
| 플로이드-와샬 | O(V^3) |
〃 |
| 벨만-포드 | O(V*E) |
음의 가중치가 있는 그래프에서 (단, 음의 가중치를 갖는 간선이 사이클을 이루지 않을 때) |
- 그래프의 최소신장트리
| 구분 | 시간복잡도 |
|---|---|
| 크루스칼 | O(ElogE) |
| 프림 | O(2ElogE) |
특정 정점에서 시작하여 그래프의 모든 정점으로 가는 최단 경로를 구한다. 간선의 가중치가 양수일 때만 가능.

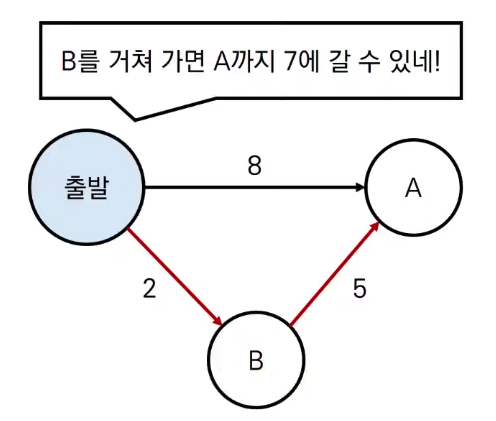
-
알고리즘
- 최단거리 테이블을 초기화해둔다
- 방문하지 않은 정점 중에서 최단 거리가 가장 짧은 정점을 선택
- 해당 정점을 거쳐 다른 정점으로 가는 비용을 계산하여 최단거리 테이블을 갱신
- 모든 정점을 방문할 때까지 반복한다
-
배열과 힙을 사용한 다익스트라
-
일반적으로 방문여부, 최단거리를 배열에 기록하며 푸는 방식은
O(V^2)시간복잡도를 가진다. 왜냐하면 방문하지 않은 정점 중에서 최단거리가 짧은 정점을 찾는 데 선형시간이 걸리기 때문이다.일반적으로 정점이 5000개 이하라면 배열을 활용한 다익스트라로 문제를 해결할 수 있다.
-
힙으로 구현한 우선순위큐는
O(logV)시간복잡도를 가지며, 이 자료구조를 활용해 최단거리가 짧은 정점을 찾는다면O(ElogV)시간복잡도를 가진다.O(ElogE) → O(ElogV^2) → O(2ElogV) → O(ElogV)
-
-
다익스트라 with 배열
- 방문하지 않은 정점 중에서 최단거리 정점을 찾을 때 배열을 활용한다.
그래프를 준비하고 출발 정점을 선택

방문하지 않은 정점 중에서 최단 거리가 가장 짧은 1번 정점을 처리






import java.util.*;
class Node {
private int index;
private int distance;
public Node(int index, int distance) {
this.index = index;
this.distance = distance;
}
public int getIndex() {
return this.index;
}
public int getDistance() {
return this.distance;
}
}
public class Main {
public static final int INF = (int) 1e9; // 무한을 의미하는 값으로 10억을 설정
// 노드의 개수(N), 간선의 개수(M), 시작 노드 번호(Start)
// 노드의 개수는 최대 100,000개라고 가정
public static int n, m, start;
// 각 노드에 연결되어 있는 노드에 대한 정보를 담는 배열
public static ArrayList<ArrayList<Node>> graph = new ArrayList<ArrayList<Node>>();
// 방문한 적이 있는지 체크하는 목적의 배열 만들기
public static boolean[] visited = new boolean[100001];
// 최단 거리 테이블 만들기
public static int[] d = new int[100001];
// 방문하지 않은 노드 중에서, 가장 최단 거리가 짧은 노드의 번호를 반환
public static int getSmallestNode() {
int min_value = INF;
int index = 0; // 가장 최단 거리가 짧은 노드(인덱스)
for (int i = 1; i <= n; i++) {
if (d[i] < min_value && !visited[i]) {
min_value = d[i];
index = i;
}
}
return index;
}
public static void dijkstra(int start) {
// 시작 노드에 대해서 초기화
d[start] = 0;
visited[start] = true;
for (int j = 0; j < graph.get(start).size(); j++) {
d[graph.get(start).get(j).getIndex()] = graph.get(start).get(j).getDistance();
}
// 시작 노드를 제외한 전체 n - 1개의 노드에 대해 반복
for (int i = 0; i < n - 1; i++) {
// 현재 최단 거리가 가장 짧은 노드를 꺼내서, 방문 처리
int now = getSmallestNode();
visited[now] = true;
// 현재 노드와 연결된 다른 노드를 확인
for (int j = 0; j < graph.get(now).size(); j++) {
int cost = d[now] + graph.get(now).get(j).getDistance();
// 현재 노드를 거쳐서 다른 노드로 이동하는 거리가 더 짧은 경우
if (cost < d[graph.get(now).get(j).getIndex()]) {
d[graph.get(now).get(j).getIndex()] = cost;
}
}
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
start = sc.nextInt();
// 그래프 초기화
for (int i = 0; i <= n; i++) {
graph.add(new ArrayList<Node>());
}
// 모든 간선 정보를 입력받기
for (int i = 0; i < m; i++) {
int a = sc.nextInt();
int b = sc.nextInt();
int c = sc.nextInt();
// a번 노드에서 b번 노드로 가는 비용이 c라는 의미
graph.get(a).add(new Node(b, c));
}
// 최단 거리 테이블을 모두 무한으로 초기화
Arrays.fill(d, INF);
// 다익스트라 알고리즘을 수행
dijkstra(start);
// 모든 노드로 가기 위한 최단 거리를 출력
for (int i = 1; i <= n; i++) {
// 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if (d[i] == INF) {
System.out.println("INFINITY");
}
// 도달할 수 있는 경우 거리를 출력
else {
System.out.println(d[i]);
}
}
}
}-
다익스트라 with 힙
- 단계마다 방문하지 않은 정점 중에서 최단거리가 가장 짧은 정점을 선택하기 위해 힙 자료구조를 이용한다.

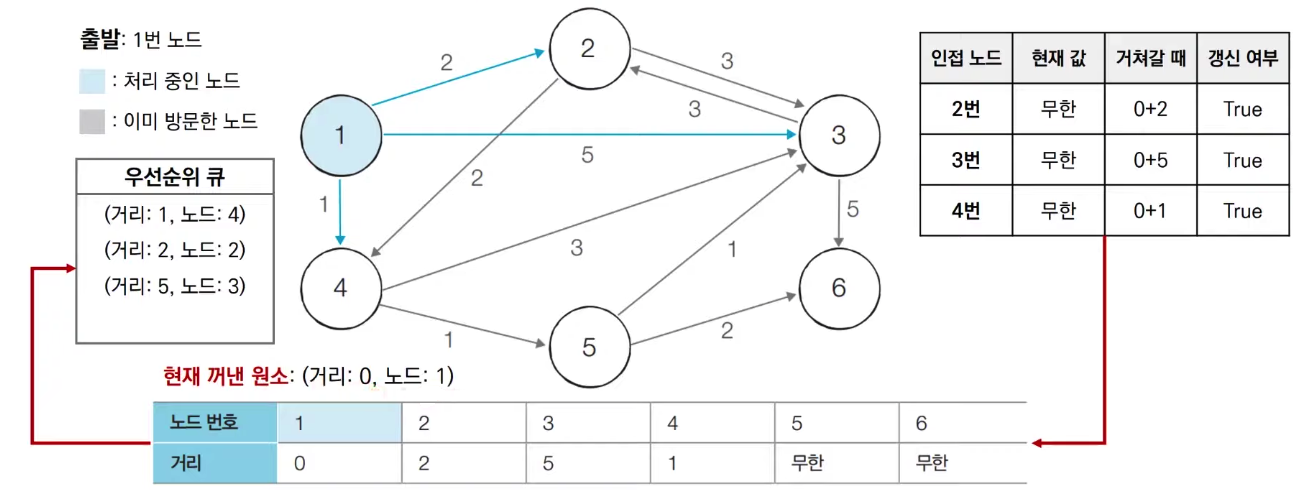


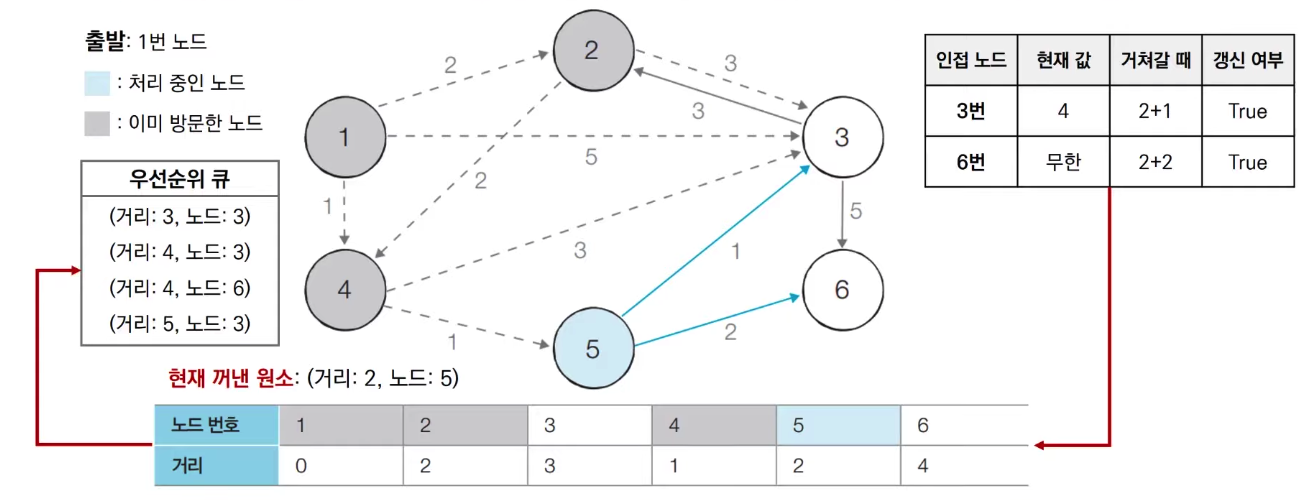




import java.util.*;
class Node implements Comparable<Node> {
private int index;
private int distance;
public Node(int index, int distance) {
this.index = index;
this.distance = distance;
}
public int getIndex() {
return this.index;
}
public int getDistance() {
return this.distance;
}
// 거리(비용)가 짧은 것이 높은 우선순위를 가지도록 설정
@Override
public int compareTo(Node other) {
if (this.distance < other.distance) {
return -1;
}
return 1;
}
}
public class Main {
public static final int INF = (int) 1e9; // 무한을 의미하는 값으로 10억을 설정
// 노드의 개수(N), 간선의 개수(M), 시작 노드 번호(Start)
// 노드의 개수는 최대 100,000개라고 가정
public static int n, m, start;
// 각 노드에 연결되어 있는 노드에 대한 정보를 담는 배열
public static ArrayList<ArrayList<Node>> graph = new ArrayList<ArrayList<Node>>();
// 최단 거리 테이블 만들기
public static int[] d = new int[100001];
public static void dijkstra(int start) {
PriorityQueue<Node> pq = new PriorityQueue<>();
// 시작 노드로 가기 위한 최단 경로는 0으로 설정하여, 큐에 삽입
pq.offer(new Node(start, 0));
d[start] = 0;
while(!pq.isEmpty()) { // 큐가 비어있지 않다면
// 가장 최단 거리가 짧은 노드에 대한 정보 꺼내기
Node node = pq.poll();
int dist = node.getDistance(); // 현재 노드까지의 비용
int now = node.getIndex(); // 현재 노드
// 현재 노드가 이미 처리된 적이 있는 노드라면 무시
if (d[now] < dist) continue;
// 현재 노드와 연결된 다른 인접한 노드들을 확인
for (int i = 0; i < graph.get(now).size(); i++) {
int cost = d[now] + graph.get(now).get(i).getDistance();
// 현재 노드를 거쳐서, 다른 노드로 이동하는 거리가 더 짧은 경우
if (cost < d[graph.get(now).get(i).getIndex()]) {
d[graph.get(now).get(i).getIndex()] = cost;
pq.offer(new Node(graph.get(now).get(i).getIndex(), cost));
}
}
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
start = sc.nextInt();
// 그래프 초기화
for (int i = 0; i <= n; i++) {
graph.add(new ArrayList<Node>());
}
// 모든 간선 정보를 입력받기
for (int i = 0; i < m; i++) {
int a = sc.nextInt();
int b = sc.nextInt();
int c = sc.nextInt();
// a번 노드에서 b번 노드로 가는 비용이 c라는 의미
graph.get(a).add(new Node(b, c));
}
// 최단 거리 테이블을 모두 무한으로 초기화
Arrays.fill(d, INF);
// 다익스트라 알고리즘을 수행
dijkstra(start);
// 모든 노드로 가기 위한 최단 거리를 출력
for (int i = 1; i <= n; i++) {
// 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if (d[i] == INF) {
System.out.println("INFINITY");
}
// 도달할 수 있는 경우 거리를 출력
else {
System.out.println(d[i]);
}
}
}
}모든 정점에서 모든 정점까지의 최단 경로를 구한다.
-
알고리즘
- 점화식은
Dab = min(Dab, Dak + Dkb)로 다익스트라와 유사하게 거쳐가는 정점을 기준으로 알고리즘을 수행한다. - 다만, 매 단계마다 방문하지 않은 노드 중 최단거리를 갖는 노드를 찾을 필요는 없다. 최단 거리 정보는 2차원 테이블에 저장한다.
- 정점마다
O(N^2)연산을 수행하므로, 총 시간복잡도는O(N^3)이다.
- 점화식은

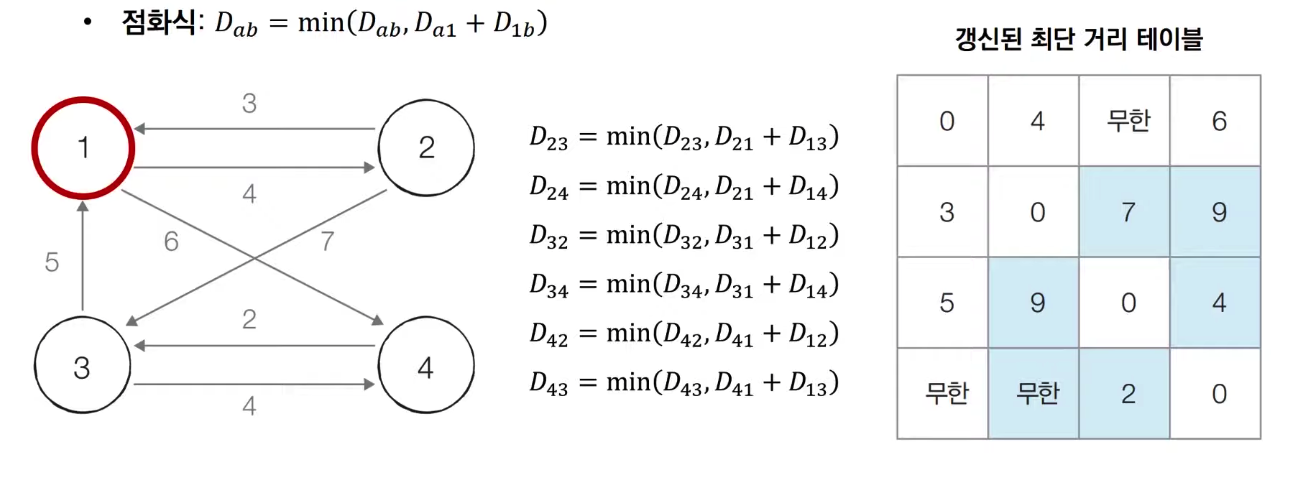



- 구현코드
import java.util.*;
public class Main {
public static final int INF = (int) 1e9; // 무한을 의미하는 값으로 10억을 설정
// 노드의 개수(N), 간선의 개수(M)
// 노드의 개수는 최대 500개라고 가정
public static int n, m;
// 2차원 배열(그래프 표현)를 만들기
public static int[][] graph = new int[501][501];
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
// 최단 거리 테이블을 모두 무한으로 초기화
for (int i = 0; i < 501; i++) {
Arrays.fill(graph[i], INF);
}
// 자기 자신에서 자기 자신으로 가는 비용은 0으로 초기화
for (int a = 1; a <= n; a++) {
for (int b = 1; b <= n; b++) {
if (a == b) graph[a][b] = 0;
}
}
// 각 간선에 대한 정보를 입력 받아, 그 값으로 초기화
for (int i = 0; i < m; i++) {
// A에서 B로 가는 비용은 C라고 설정
int a = sc.nextInt();
int b = sc.nextInt();
int c = sc.nextInt();
graph[a][b] = c;
}
// 점화식에 따라 플로이드 워셜 알고리즘을 수행
for (int k = 1; k <= n; k++) {
for (int a = 1; a <= n; a++) {
for (int b = 1; b <= n; b++) {
graph[a][b] = Math.min(graph[a][b], graph[a][k] + graph[k][b]);
}
}
}
// 수행된 결과를 출력
for (int a = 1; a <= n; a++) {
for (int b = 1; b <= n; b++) {
// 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if (graph[a][b] == INF) {
System.out.print("INFINITY ");
}
// 도달할 수 있는 경우 거리를 출력
else {
System.out.print(graph[a][b] + " ");
}
}
System.out.println();
}
}이것이 코딩 테스트다 7. 최단 경로 알고리즘 (tistory.com)
특정 정점에서 시작하여 모든 정점에 대한 최단 경로를 구한다. 간선의 가중치가 음수, 양수일 때 모두 가능. 다만, 음수 가중치가 사이클을 이룬 경우에는 작동하지 않는다. 시간복잡도는 O(V*E)이다. 간선의 수가 정점의 제곱에 근사하므로 O(V^2)으로 표현할 수 있다. [벨만-포드 알고리즘 · ratsgo's blog](https://ratsgo.github.io/data structure&algorithm/2017/11/27/bellmanford/)
-
신장트리란 그래프의 정점을 모두 지나는 트리이다.
-
'트리' 형태이므로 사이클이 발생하지 않아야 한다.
-
'최소 신장트리'란 신장트리 중 가중치의 합이 가장 작은 트리로서, 그래프의 연결성을 유지하는 가장 '저렴한' 그래프를 찾는 문제이다.

-
알고리즘 : 간선 가중치로 오름차순 정렬하여 가장 낮은 것부터 선택하여 확장
-
그래프의 간선 리스트를 구성
-
간선의 가중치를 기준으로 오름차순 정렬
O(ElogE) -
가중치가 가장 작은 간선부터 추가
O(1) * E -
단, 사이클이 발생하는 간선은 추가하지 않음
-
-
구현코드
- 트리에 간선을 추가하고 깊이우선탐색하며 역방향 간선이 있는지 확인, 각 간선마다 깊이우선탐색을 하기 때문에, 간선의 수와 깊이우선탐색의 시간복잡도를 곱해
O(V+E) * E = O(E^2)이 된다. - 간선을 추가해서 사이클이 생기려면, 간선의 양 끝점은 같은 집합에 속해 있어야 한다. 두 정점이 주어졌을 때 이들이 같은 집합에 속하는지 확인할 수 있고, 그렇지 않을 때 두 집합을 합치는 연산을 빠르게 지원할 수 있다면 시간복잡도를 개선할 수 있다.
#include <iostream> #include <utility> typedef pair<int, int> ii; vector<pair<int, ii> > EdgeList; //<가중치, 간선정보> int main() { //1. 그래프의 간선 리스트를 구성한다 /* EdgeList에 간선을 추가한다. */ //2. 간선을 가중치 오름차순으로 정렬한다 sort(EdgeList.begin(), EdgeList.end()); UnionFind UF(V); //각 정점을 상호 배타적인 집합으로 선언 int mst_cost = 0; for(int i = 0; i < E; ++i) { //3-4. 사이클이 생성되지 않도록 가중치가 가장 낮은것부터 선택한다 if(!UF.isSameSet(EdgeList[i].second.first, EdgeList[i].second.second)){ mst_cost += EdgeList[i].first; UF.unionSet(EdgeList[i].second.first, EdgeList[i].second.second); } } printf("Sum of edge's load included MST is %d\n", mst_cost); }
- 트리에 간선을 추가하고 깊이우선탐색하며 역방향 간선이 있는지 확인, 각 간선마다 깊이우선탐색을 하기 때문에, 간선의 수와 깊이우선탐색의 시간복잡도를 곱해
-
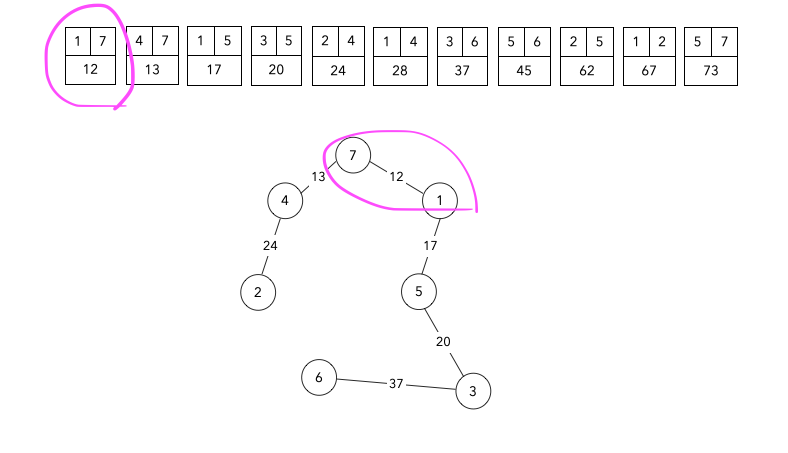
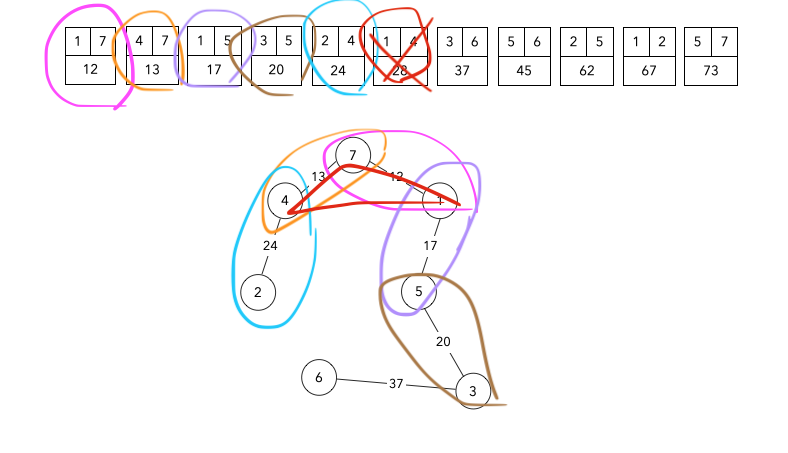
Union-Find
-
problem
-
solve
-
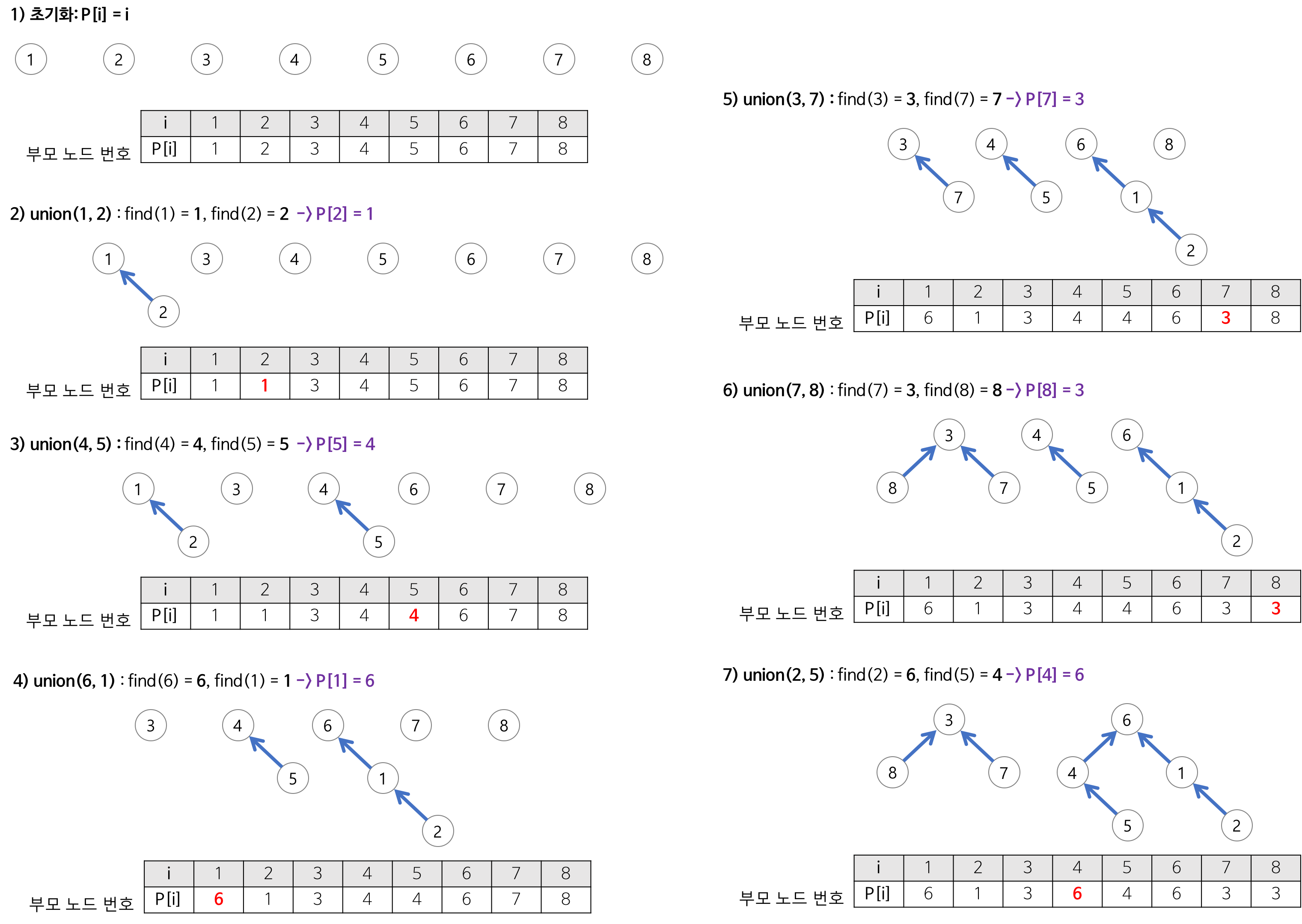
구현코드
- 정점개수 크기의 배열을 선언
- 정점이 이어질 때마다 부모 또는 루트노드번호를 그룹아이디로 지정
- 두 정점의 그룹아이디가 같으면 사이클이 발생하는 것
#include <iostream> #include <vector> #include <algorithm> using namespace std; bool sortMethod(const vector<int>& v1, const vector<int>& v2) { return v1[2] < v2[2]; } inline bool allVisited(vector<int> &v) { for (int i = 1; i < v.size(); i++) { if (v[i]==0 || v[i] != v[i - 1]) return false; } return true; } int solution(int n, vector<vector<int>> cost) { sort(cost.begin(), cost.end(), sortMethod); vector<int> visit(n); int pos = 0, answer = 0, gId = 1; while (!allVisited(visit) && pos < cost.size()) { if (visit[cost[pos][0]] || visit[cost[pos][1]]) { //avoid cycle if (visit[cost[pos][0]] == visit[cost[pos][1]]) { //cout << pos << "는 거른다." << endl; pos++; continue; } //union group int t = visit[cost[pos][0]] > visit[cost[pos][1]] ? visit[cost[pos][0]] : visit[cost[pos][1]]; if (visit[cost[pos][0]] == 0) visit[cost[pos][0]] = t; else if (visit[cost[pos][1]] == 0) visit[cost[pos][1]] = t; else { vector<int> temp(n); temp.assign(visit.begin(), visit.end()); for (int i = 0; i < visit.size(); i++) { if (visit[i] == visit[cost[pos][0]] || visit[i] == visit[cost[pos][1]]) temp[i] = t; } visit.assign(temp.begin(), temp.end()); } } else { //set group visit[cost[pos][0]] = gId; visit[cost[pos][1]] = gId; gId++; } answer += cost[pos][2]; //cout << pos << "는 포함한다." << endl; pos++; } cout << answer << endl;; return answer; }
-



알고리즘 Union-Find 알고리즘 - Heee's Development Blog (gmlwjd9405.github.io)
-
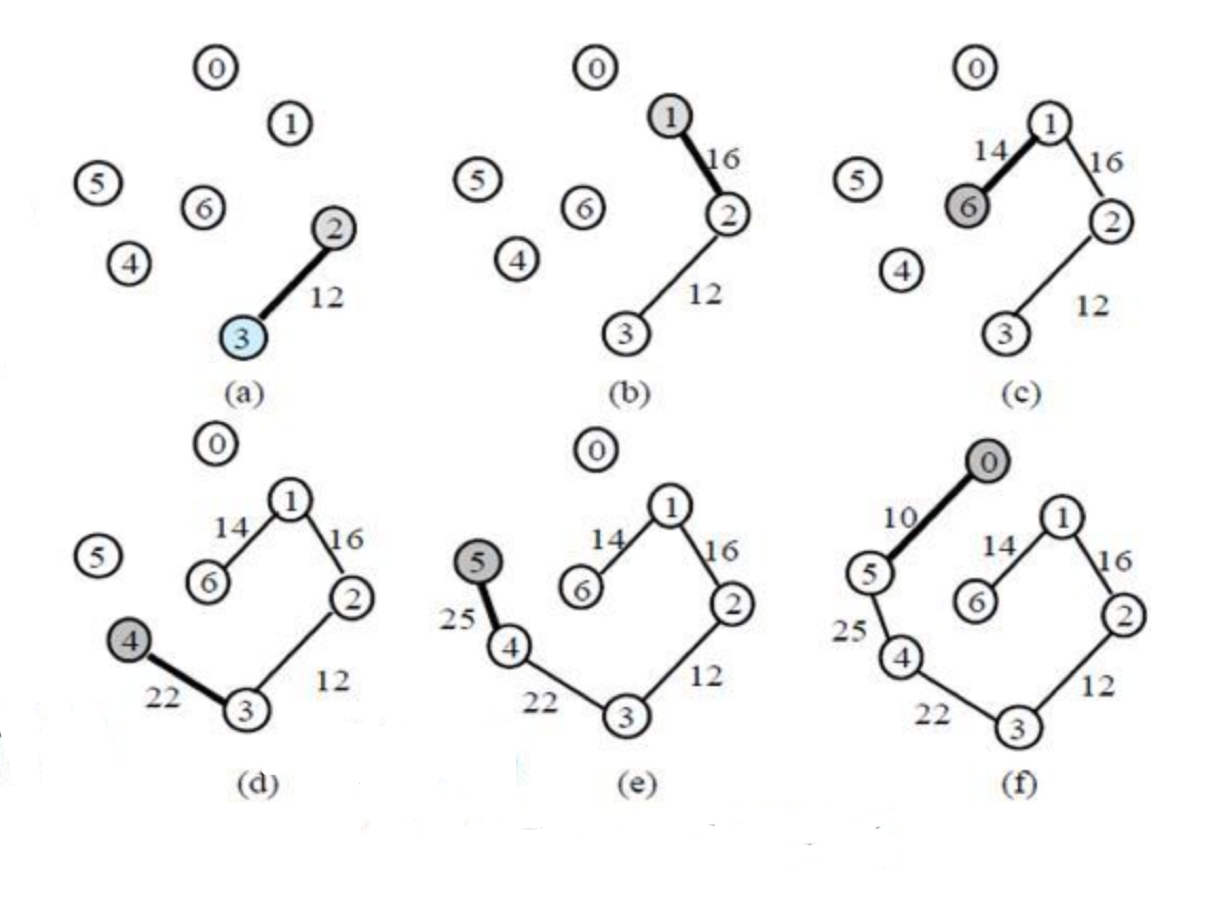
알고리즘 : 시작정점을 기준으로 가중치가 가장 낮은 간선을 선택하여 확장
-
우선순위큐에 간선과 그 가중치를 삽입(가중치 오름차순으로 정렬)
O(ElogE)우선순위큐는 힙으로 구현했을 때 삽입/삭제에 O(logN) 시간복잡도를 가지며, 힙은 배열을 이용해 완전이진트리로 구현할 수 있다.
겐지충 프로그래머 :: 자료구조 - 우선순위 큐(Heap, Priority Queue) (tistory.com)
-
임의의 간선을 선택
-
선택한 간선으로부터 가장 낮은 가중치를 갖는 정점을 선택
O(ElogE) -
모든 정점을 선택할 때까지 반복
-
-
구현코드
#include <iostream> #include <utility> typedef pair<int, int> ii; typedef vector<int> vi; vi taken; priority_queue<ii> pq; void process(int vtx) { taken[vtx] = 1; for (int i = 0; i < (int) AdjList[vtx].size(); ++i) { ii v = AdjList[vtx][i]; if (!taken[v.first]) pq.push(ii(-v.second, -v.first)); //pq는 기본적으로 최대힙이므로 오름차순 정렬을 위해 //부호 역전 } } int main() { //해당 정점이 MST구성에 사용 되었는지 여부를 저장 taken.assign(V, 0); //시작점을 설정하고 시작점과 인접한 정점, 가중치 쌍을 pq에 삽입 process(0); int mst_cost = 0; while (!pq.empty()) { //pq에서 가중치가 가장 작고 번호가 빠른 ii front = pq.top(); pq.pop(); int w = -front.first, u = -front.second; if (!taken[u]) { mst_cost += w; process(u); } } printf("MST value: %d\n", mst_cost); }

최소 스패닝 트리(MST, Minimum Spanning Tree) (tistory.com)
-
알고리즘 시간복잡도 계산 및 실제문제 :
O(N^2)이고 100MHz에서 4초 걸렸다면, 1초??
주어진 함수의 시간복잡도를 계산하고
100MHz 싱글코어 CPU에서 f(x)의 수행시간이 00일때
200MHz 싱글코어 CPU에서 f(x)의 수행시간은?
알고리즘 시간복잡도 예제 15종 | 블로그 | 딩그르르 (dingrr.com)
-
부동소수점(IEEE 754기준으로)
-
부동소수점의 산술연산
- 덧셈과 곱셈은 교환법칙이 성립한다.
a + b = b + a이고a x b = b x a이다. - 결합법칙은 꼭 성립하는 것은 아니다.
(a + b) + c가 반드시a + (b + c)와 같지는 않다. - 분배법칙도 꼭 성립하는 것은 아니다.
(a + b) x c는a x c + b x c와 다를 수 있다. - 왜냐하면 연산도중 지수/가수부로 표현가능한 범위를 넘어서서 언더/오버플로가 발생하여 정보가 소실될 수 있기 때문이다.
- 덧셈과 곱셈은 교환법칙이 성립한다.
-
단정도/배정도란
- single precision(단정밀도): 32비트 / bias of 127
- double precision(배정밀도): 64비트 / bias of 1023
- long double precision: 80비트
-
표현방식
-
부호: 가장왼쪽 비트(Most Significant Bit, 최상위 비트),
0: 양수1: 음수 -
지수: 2^8-1개의 수를 표현할 수 있다. 최상위비트를 부호표현에 사용하는 대신
바이어스(biased) 표현법을 통해 양수화해서 표현한다.바이어스 표현법: 2의 보수 + 바이어스 상수(32bit의 경우 127)
-
가수:
1.xxxx형식으로 바꾸고 실수부는 언제나 1이므로 생략하고, 소수부만 표현한다. -
오차: 가수의 길이 23을 넘어가면 넘어간 수만큼 0이 생긴다. 길이가 24면 2의 배수가 되고, 길이가 25면 4의 배수가 되며 점점 오차가 커진다. 지수부 2^(2^8) 보다 큰 수 또는 0~2^(-2^8) 보다 작은 수는 정확히 표현할 수 없다.
-
-
정확도 관련 문제
- 소거: 거의 같은 두 값을 빼는 것은 정확성을 매우 많이 잃게 된다. 이 문제가 아마도 가장 일반적이고 심각한 정확도 문제이다.
- 정수로의 변환 문제: (63.0/9.0)을 정수로 변환하면 7이 되지만 (0.63/0.09)는 6이 된다. 이는 일반적으로 반올림 대신 버림을 하기 때문이다.
- 제한된 지수부: 결과값이 오버플로되어 무한대값이 되거나 언더플로되어 비정규 값 또는 0이 될 수 있다. 만약 비정규 값이 되면 유효숫자를 완전히 잃어버린다.
- 나눗셈이 안전한지 검사하는데 문제가 생김: 제수(나눗수)가 0이 아님을 검사하는 것이 나눗셈이 오버플로되고 무한대값이 되지 않는 걸 보장하지 않는다.
- 같음을 검사하는데 문제가 생김: 수학적으로 같은 계산결과가 나오는 두 계산 순서가 다른 부동소수점 값을 만들어낼 수 있다. 프로그래머는 어느정도의 허용 오차를 가지고 비교를 수행하지만, 그렇다고 해서 문제가 완전히 없어지지 않는다.
-



단정도(single precision), 배정도(double precision)이란? (tistory.com)
부동소수점 수의 표현, 부동소수점 산술 연산 (tistory.com)