Contenido del curso - Chago0900/Portafolio-CE-2103 GitHub Wiki
Welcome to the best Portafolio-CE-2103 wiki!
Funciones principales (De alto nivel):
- Provee una API (Application Programming Interface) para desarrolladores
- Controla todos los recursos de la máquina
Funciones principales:
- Manejo de procesos
- Manejo de memoria (Código):
⮕ La parte del sistema operativo encargada se llama "Memory Manager" ⮕ A nivel de programación cada programa en ejecución o proceso tiene una estructura para su memoria, este diseño puede depender del lenguaje de programación en el que sea escrito, pero conceptualmente es similar.
⮕ Existen varios enfoques sobre cómo manejar la memoria apropiadamente:- No separar de la memoria física
- Espacios de dirección
- Memoria Virtual
- Manejo de archivos y discos
- Manejo de Input/Output (I/O)
Es una estructura dinámica de datos que almacena la información sobre las subrutinas activas de un programa en ejecución. Cuando hacemos una llamada a una función, un bloque en el tope de la pila es reservado para guardar las variables locales junto con algunos datos necesarios para garantizar el funcionamiento adecuado de la estructura (como la dirección a la que tendrá que retornar el hilo de ejecución cuando termine la función). Después de retornar, el bloque de la pila que ocupaba el llamado, se libera para poder utilizarse más adelante de ser necesario.
Se llama pila de ejecución porque es una estructura de datos que funciona bajo el concepto de LIFO (last in first out). Esto hace que sea más sencillo mantener el control de los bloques que deben ser liberados, puesto que será aquel que esté en el tope de la pila.
Es una estructura dinámica de datos utilizada para almacenar datos en ejecución. A diferencia de la pila de ejecución que solamente almacena las variables declaradas en los bloques previo a su ejecución, el heap permite reservar memoria dinámicamente, es decir, es el encargado de que la "magia" de la memoria dinámica ocurra. Las variables globales y estáticas también son almacenadas en él.
Como esta estructura de datos no sigue ninguna metodología, es un poco complicado mantener el control de los bloques de memoria reservados puesto que se pueden ocupar y liberar espacios en cualquier momento.

Un puntero es un tipo de datos cuyo valor es una dirección de memoria.
Cuando una variable de tipo puntero tiene almacenada una dirección de memoria, se dice que «apunta» al valor que está en esa dirección.
`#include <stdio.h>
int main () {
int var = 20; /* actual variable declaration */ int ip; / pointer variable declaration */
ip = &var; /* store address of var in pointer variable*/
printf("Address of var variable: %x\n", &var );
/* address stored in pointer variable */ printf("Address stored in ip variable: %x\n", ip );
/* access the value using the pointer */ printf("Value of *ip variable: %d\n", *ip );
return 0; } '
Resultado:
'
Address of var variable: bffd8b3c
Address stored in ip variable: bffd8b3c
Value of *ip variable: 20
`
- Algunos lenguajes como Java tienen Garbage Collector automatizado
- Normalmente funciona en dos fases:
⮕ Fase de marcado: Revisa si las celdas están siendo referenciadas o no
⮕ Fase de reclamo: Todas las celdas marcadas son retornadas al "memory pool"
Tres tipos de modelos:
• Modelo funcional
• Modelo objeto
• Modelo dinamico
Cada uno se compone por un conjunto de diagramas
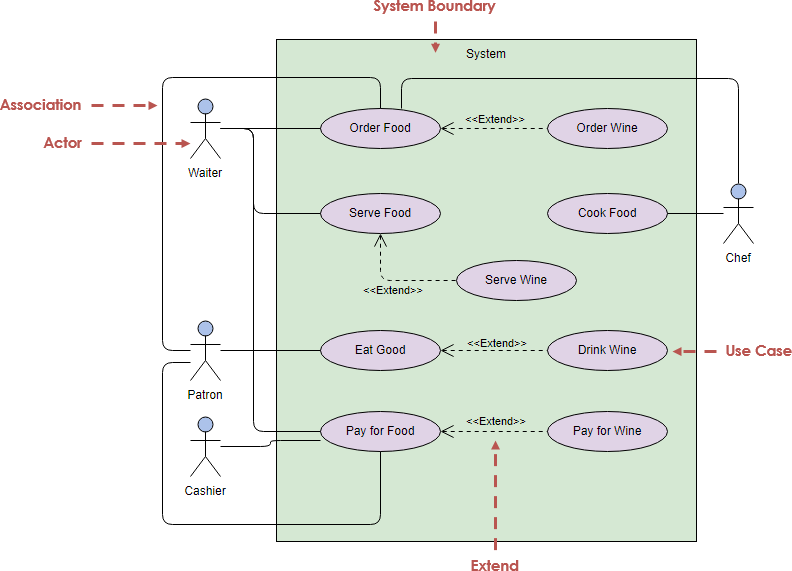
Casos de uso
• Especifica la comunicación y el comportamiento de un sistema mediante su interacción con los usuarios y/u otros sistemas.
• Tiene un diagrama y especificaciones
Modelo funcional:
Es usado para capturar comportamientos del sistema, subsitema, clase o componente
El caso de uso tiene un diagrama y especificaciones

Se define como un paradigma de la programación, una manera de programar específica, donde se organiza el código en unidades denominadas clases, de las cuales se crean objetos que se relacionan entre sí para conseguir los objetivos de las aplicaciones.
Objeto:
Se caracteriza por dos cosas:
• Cualidades
• Comportamientos
Todos los objetos son referencias
Abtracción:
Tomar algo complicado y expresarlo en términos propios // Modelar en base a conceptos básicos
Encapsulamiento:
Privar los atributos de ser cambiados, solo leídos
• Todos los atributos de los objetos deben ser private
Modificadores de acceso:
• Public:
• Private:
• Protected:
• Friendly… nada:
Overload:
Dos métodos con el mismo nombre, pero diferentes parámetros
Polimorfismo
Definir clases diferentes que tienen metodos iguales, pero se comportan diferente
Código:
Crear clases que sirvan de “molde” para crear objetos en la clase principal con aquellos atributos. Clases = Moldes de los objetos
Asegurar que el software realice su funcion correctamente y de la manera más óptima posible (costo, tamaño, rendimiento, etc).
Proceso eficiente: Seguimiento detallado durante la creación del software (comunicación con el cliente).
Buen proceso ⮕ mejor calidad de producto
Quality Control (QC): Evaluar un producto desarrollado y sus etapas
Quality Assurance (QA): Asegurar que el proceso de creación del producto es adecuado
Testing: Medida que verifica la calidad del producto final y sus etapas, ejecutándolo. Existen herramientas automatizadas. No se debe dejar hasta el final.
- Black Box:
- White Box:
Framework vs Toolkit:
International Standard Organization (ISO): Grado de satisfaccion de requerimientos funcionales y no funcionales de un software.
La organización se encarga de promover los parámetros y normas que deben cumplir la fabricación, comunicación y comercio de varias ramas industriales y que sirven también para la calidad de los procesos productivos, control de las empresas y de las organizaciones internacionales que se dedican al perfeccionamiento de la calidad y seguridad de productos en el mundo.
ISO/IEC 9126-1 Software Quality

Cómo evitar que el software se complique?
Sistema de resolución sistemática de problemas
- Se puede representar por pseudocódigo, diagramas de flujo, etc...
- Cada paso es definido con precisión
- Siempre con la misma entrada produce la misma salida
• Mantener listas de elementos ordenados es importante para facilitar las búsquedas
• Una lista de elementos desordenados no permite realizar búsquedas de manera eficiente
• Hay muchos algoritmos de ordenamiento
• La meta es encontrar algoritmos cada vez más eficientes
Selección Sort:
• Consiste en buscar el menor elemento, sacarlo de la lista, ponerlo en otra y repetir hasta que la lista original esté vacía
• Este enfoque es costoso en términos de espacio
• Se puede mejorar
static void selectSort() {
int end = size – 1;
for (int current = 0, current < end; current ++) {
swap (current, minimo(current, end)); / /current = primero de la lista
}
}
Bubble Sort:
• Consiste en “empujar” el mayor hacia el final de la lista
• Únicamente se comparan elementos adyacentes
class BubbleSort { void bubbleSort(int arr[]) { int n = arr.length; for (int i = 0; i < n-1; i++) for (int j = 0; j < n-i-1; j++) if (arr[j] > arr[j+1]) { // swap arr[j+1] and arr[i] int temp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = temp; } }
/* Prints the array */
void printArray(int arr[])
{
int n = arr.length;
for (int i=0; i<n; ++i)
System.out.print(arr[i] + " ");
System.out.println();
}
// Driver method to test above
public static void main(String args[])
{
BubbleSort ob = new BubbleSort();
int arr[] = {64, 34, 25, 12, 22, 11, 90};
ob.bubbleSort(arr);
System.out.println("Sorted array");
ob.printArray(arr);
}
}
Radixsort
class Radix {
// A utility function to get maximum value in arr[]
static int getMax(int arr[], int n)
{
int mx = arr[0];
for (int i = 1; i < n; i++)
if (arr[i] > mx)
mx = arr[i];
return mx;
}
// A function to do counting sort of arr[] according to
// the digit represented by exp.
static void countSort(int arr[], int n, int exp)
{
int output[] = new int[n]; // output array
int i;
int count[] = new int[10];
Arrays.fill(count,0);
// Store count of occurrences in count[]
for (i = 0; i < n; i++)
count[ (arr[i]/exp)%10 ]++;
// Change count[i] so that count[i] now contains
// actual position of this digit in output[]
for (i = 1; i < 10; i++)
count[i] += count[i - 1];
// Build the output array
for (i = n - 1; i >= 0; i--)
{
output[count[ (arr[i]/exp)%10 ] - 1] = arr[i];
count[ (arr[i]/exp)%10 ]--;
}
// Copy the output array to arr[], so that arr[] now
// contains sorted numbers according to curent digit
for (i = 0; i < n; i++)
arr[i] = output[i];
}
}
- Es un algoritmo eficiente para encontrar un elemento en una lista ordenada de elementos. Funciona al dividir repetidamente a la mitad la porción de la lista que podría contener al elemento, hasta reducir las ubicaciones posibles a solo una.

- Búsqueda de interpolación se parece al método por el cual la gente busca un directorio telefónico para un nombre (el valor de la clave por la que se ordenan las entradas del libro): en cada paso, el algoritmo calcula en qué parte del restante espacio de búsqueda el elemento buscado podría ser, basado en los valores clave en los límites del espacio de búsqueda y el valor de la clave buscada, por lo general a través de una interpolación lineal. El valor de la clave de hecho se encuentra en esta posición estimada se compara a continuación se busca el valor de la clave. Si no es igual, a continuación, en función de la comparación, el espacio de búsqueda restante se reduce a la parte antes o después de la posición estimada. Este método sólo funcionará si los cálculos sobre el tamaño de las diferencias entre los valores de las claves son sensibles.
- El "hashing" alude al proceso de generar un output de extensión fija, a partir de un input de extensión variable. Esto se logra mediante el uso de unas fórmulas matemáticas denominadas funciones hash (y que se implementan como algoritmos hashing).
A pesar de que no todas las funciones hash conllevan el uso de criptografía, las llamadas funciones hash criptográficas son una parte fundamental de las criptomonedas. Gracias a ellas, las blockchains y otros sistemas distribuidos son capaces de alcanzar niveles significativos de integridad y seguridad en los datos.
Tanto las funciones hash convencionales como las criptográficas son determinísticas. Que sean "determinísticas" significa que, en la medida que el input no se modifique, el algoritmo hashing producirá siempre el mismo output (también conocido como "digest")
Se trata de un algoritmo o técnica de resolución de problemas recursivamente, intenrando contruir una solcuión incrementalmente, parte por parte, removiendo aquellas soluciones que no se consideran óptimas
- Se refiere a una técnica matemática que se utiliza en la solución de problemas seleccionados, en los cuales se toma una serie de decisiones en forma secuencial.
Ejemplos: - Fibonacci
- Knapsack problem
- Cashier problem
- Se inspiran en los procesos de evolución biológica
- Algoritmos de búsqueda adaptativos
- Representan una especie de algoritmo de explotación inteligente
- No son directamente aleatorios. Utilizan información histórica
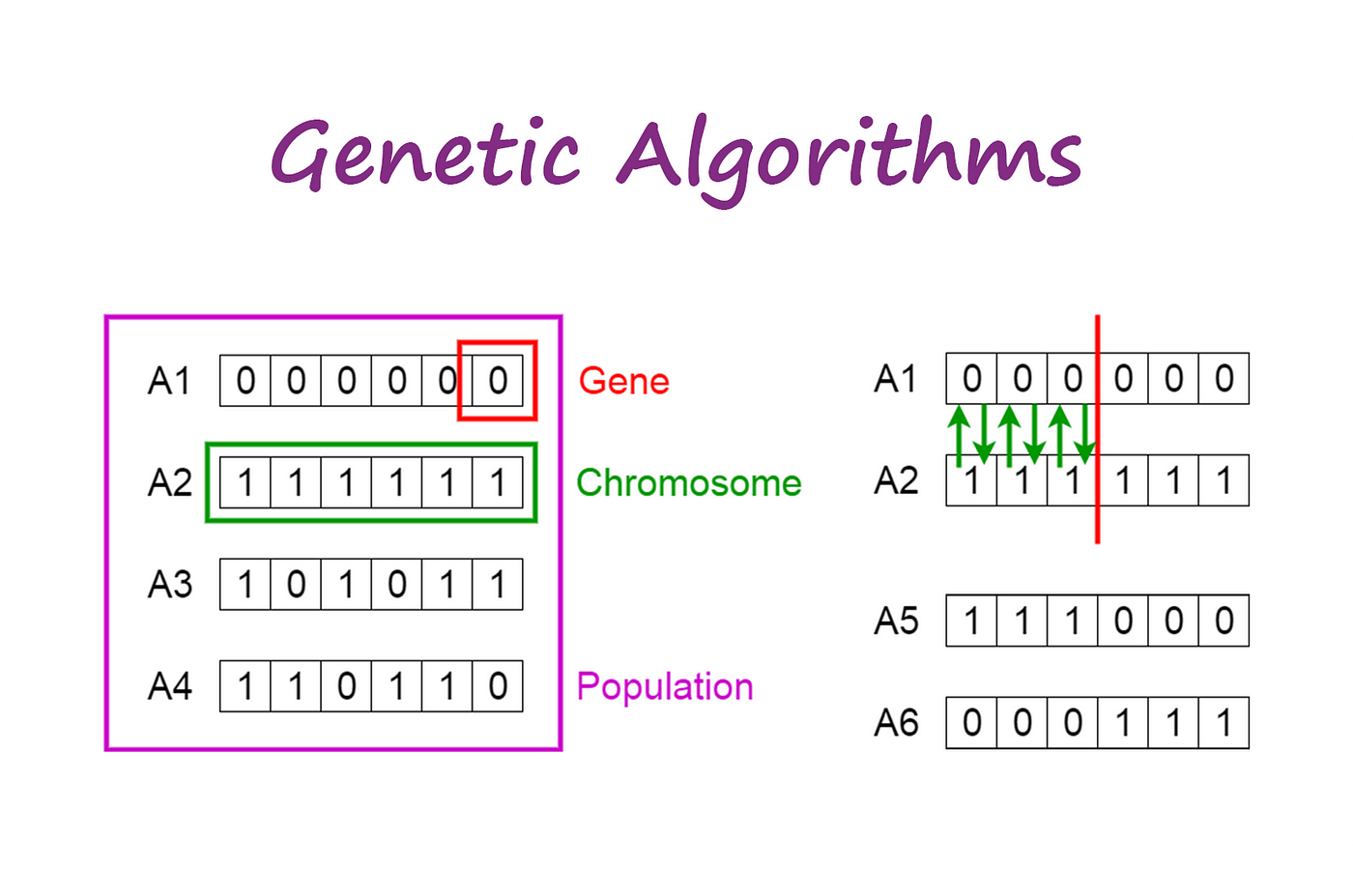
Fenotipo:
Características observables del individuo.
Genotipo: Código genético que determina las características del individuo
Técnicas para elegir padres:
- Wheel Selection
Despliega en el cliente el resultado de la ejecucion Servidor que ejecuta apps web
Informacion o paginas estaticas Albergan contenido html y lo despliega el cliente por http
Un entorno de trabajo o framework, es un conjunto estandarizado de conceptos, prácticas y criterios para enfocar un tipo de problemática particular que sirve como referencia, para enfrentar y resolver nuevos problemas de índole similar. Es un framework diseñado para apoyar el desarrollo de sitios web dinámicos, aplicaciones web y servicios web. Este tipo de frameworks intenta aliviar el exceso de carga asociado con actividades comunes usadas en desarrollos web. Por ejemplo, muchos framework proporcionan bibliotecas para acceder a bases de datos, estructuras para plantillas y gestión de sesiones, y con frecuencia facilitan la reutilización de código.
Los algoritmos de compresión sin pérdida, como también son conocidos, reducen el tamaño del archivo sin perder la calidad.
Esto puede aumentar su entropía y hacer que los archivos parezcan más aleatorios porque todos los bytes posibles se vuelven más comunes.
Cuando se guarda el archivo, se comprime, cuando se descomprime (abre) se recuperan los datos originales. Los datos del archivo solo se “tiran” temporalmente, para que el archivo se pueda transferir.
Este tipo de compresión se puede aplicar no solo a gráficos, sino a cualquier tipo de información de computadora, como hojas de cálculo, documentos de texto y aplicaciones de software.
Se utiliza para la compresión o encriptación de datos mediante el estudio de la frecuencia de aparición de caracteres. El algoritmo funciona a partir de un conjunto dado de símbolos con sus respectivos pesos. Los pesos son la frecuencia de aparición en una cadena. Por ejemplo, en la cadena Genciencia el peso del símbolo i es 2, ya que aparece en dos ocasiones. La salida del algoritmo es el mismo conjunto de símbolos de entrada codificado mediante un código binario con un tamaño menor.
• Contar cuantas veces aparece cada carácter en el fichero a comprimir. Y crear una lista enlazada con la información de caracteres y frecuencias.
• Ordenar la lista de menor a mayor en función de la frecuencia.
• Convertir cada elemento de la lista en un árbol.
• Fusionar todos estos árboles en uno único, para hacerlo se sigue el siguiente proceso, mientras la lista de árboles contenga más de un elemento:
o Con los dos primeros árboles formar un nuevo árbol, cada uno de los árboles originales en una rama.
o Sumar las frecuencias de cada rama en el nuevo elemento árbol.
o Insertar el nuevo árbol en el lugar adecuado de la lista según la suma de frecuencias obtenida.
• Para asignar el nuevo código binario de cada carácter sólo hay que seguir el camino adecuado a través del árbol. Si se toma una rama cero, se añade un cero al código, si se toma una rama uno, se añade un uno.
• Se recodifica el fichero según los nuevos códigos.
La codificación aritmética puede considerarse como una generalización de la codificación de Huffman, de hecho, en la práctica la codificación Aritmética viene precedida por la codificación de Huffman, pues es más fácil encontrar una aritmética para una entrada binaria que para una no binaria. Además, a menudo se utiliza en algún otro método de compresión, como la deflación y códec multimedia como JPEG y MP3 que tienen una cuantificación digital basada en la codificación de Huffman.
Además de la compresión de datos, el algoritmo de Huffman se utiliza en la seguridad informática, principalmente, para la codificación de textos o mensajes.
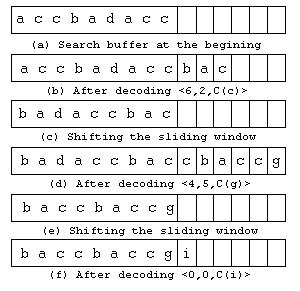
- Es un compresor basado en algoritmo sin pérdida se utilizan cuando la información a comprimir es crítica y no se puede perder información, por ejemplo en los archivos ejecutables, tablas de bases de datos, o cualquier tipo de información que no admita pérdida. El modelo lz77 es muy usado porque es fácil de implementar y es bastante eficiente.
En 1977 Abraham Lempel y Jacob Ziv presentaron su modelo de compresión basado en diccionario, para compresión de texto se refiere a la compresión sin pérdida para cualquier tipo de datos. Hasta la fecha todos los algoritmos de compresión desarrollados eran básicamente compresores estáticos. El nuevo modelo fue llamado lz77 (lz son la iniciales de sus creadores y 77 el año en que se creó).
En este algoritmo el codificador analiza el texto como una secuencia de caracteres, mediante una ventana deslizable compuesta por dos partes; un buffer de anticipación que es la opción que está a punto de ser codificada y un buffer de búsqueda (la ventana en sí), que es la parte dónde se buscan secuencias iguales a las existentes en el buffer de anticipación. Para codificar el contenido, o parte de él, del buffer de anticipación, se busca la secuencia igual en el buffer de búsqueda y la codificación resulta en indicar esta repetición como una tripleta [offset, longitud, carácter siguiente].
Donde:
* Offset es la distancia desde el principio del buffer de anticipación hasta el comienzo de la secuencia repetida.
* Longitud es la cantidad de caracteres repetidos.
* Carácter siguiente es el símbolo siguiente a la secuencia en el buffer de anticipación.
Pero, ¿cómo sabe el descompresor si lo que lee es un par desplazamiento/tamaño o un byte sin comprimir?. La respuesta es simple, usamos un prefijo, un bit que actúa como una bandera, de forma similar a un interruptor con dos estados que nos permite saber qué tipo de datos vienen a continuación. Si el prefijo es 0, entonces lo que viene es un byte sin comprimir. Si, por el contrario, el prefijo es 1, entonces lo que sigue a continuación es un par desplazamiento/tamaño. A estos prefijos también se les llama “banderas”. El par desplazamiento/tamaño es llamado una palabra clave. Una palabra clave es un grupo de bits (o bytes) que contienen alguna clase de información usada por el compresor y el descompresor. La otra salida posible de LZ77 es un literal, la cual es simplemente un byte sin comprimir, de manera que la salida de LZ77 puede ser de tres formas:
* Literales: son simplemente bytes sin comprimir.
* Palabras clave: en nuestro caso son pares tamaño/desplazamiento.
* Banderas: simplemente nos indican si los datos que hay a continuación son literales o palabras clave.
Los algoritmos de compresión LZ78 lograr mediante la sustitución de ocurrencias repetidas de datos con referencias a un diccionario que está construido en base a la secuencia de datos de entrada. Cada entrada del diccionario es de la forma dictionary[...] = {index, character}, donde el índice es el índice a una anterior entrada del diccionario, y el carácter se añade a la cadena representada por dictionary[index]. Por ejemplo, "abc" se almacena (en orden inverso) como sigue: dictionary[k] = {j, 'c'}, dictionary[j] = {i, 'b'}, dictionary[i] = {0, 'a'}, donde un índice de 0 especifica el primer carácter de una cadena. El algoritmo se inicializa último índice coincidente = 0 y próxima disponibles índice = 1. Para cada carácter del flujo de entrada, el diccionario se busca una coincidencia: {último índice coincidente, el personaje}. Si se encuentra una coincidencia, entonces el índice coincidente última se establece en el índice de la entrada coincidente, y nada es de salida. Si no se encuentra una coincidencia, entonces se crea una nueva entrada en el diccionario: Diccionario [siguiente índice disponible] = {index último juego, el personaje}, y las salidas del algoritmo índice de la última coincidencia , seguido de carácter , a continuación, restablece la última coincidencia de índice = 0 y incrementos siguiente índice disponible . Una vez que el diccionario está lleno, no se añaden más entradas. Cuando se alcanza el final de la secuencia de entrada, el algoritmo emite última de adaptación de índices . Tenga en cuenta que las cadenas se almacenan en el diccionario en orden inverso, que un decodificador LZ78 tendrá que tratar.
Fue publicado por Welch en 1984 como una implementación mejorada del LZ78. El algoritmo es simple de implementar y tiene el potencial de rendimiento muy alto en las implementaciones de hardware.
codifica secuencias de datos de 8 bits como de longitud fija códigos de 12 bits. Los códigos de 0 a 255 representan secuencias 1 caracteres que consiste de los correspondientes caracteres de 8 bits, y los códigos 256 a través de 4095 se crean en un diccionario para las secuencias encontradas en los datos a medida que se codifica. En cada etapa de compresión, bytes de entrada están reunidos en una secuencia hasta que el carácter siguiente haría una secuencia para la que no existe un código aún en el diccionario. El código para la secuencia (sin ese carácter) se añade a la salida, y se añade un nuevo código (para la secuencia con la que el personaje) al diccionario.
