[SR 3]SRResNet SRGAN - ChaeyeonSon/PaperReading GitHub Wiki
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
SRGAN
- Keyword : SR에 Generative Adversarial Network(GAN) 구조 적용; perceptual loss function = adversarial + content loss; content loss = perceptual similarity, VGG에서 feature map 에서의 MSE; Mean-opinion-score : 사람이 직접 perceptual quality 평가한 점수
1. Introduction
기존의 MSE loss 는 높은 scaling factor 에서 texture detail 이 없는 문제 발생
-> VGG network의 high-level feature map을 이용하는 perceptual loss 정의
1.1. Related Work
- Image super-resolution
edge-directed SR algorithm, multi-scale dictionary, neighborhood embedding ...
CNN -> LISTA, DRCN ... - Design of convolutional neural networks
batch normalization, recursive CNN(DRCN), residual block, skip-connection - Loss functions
pixel-wise loss such as MSE -> texture같은 high-frequency detail lost b/c average하는 것이 overly-smooth discriminator loss (GAN; minimize squared error in the feature spaces of VGG19) 비슷하게 pretrained VGG network에서 추출된 feature들로 error measure -> SR과 artistic style-transfer에서 인식적으로도 신빙성있는 결과
1.2. Contribution
- 16 blocks deep ResNet(SRResNet) optimized for MSE
- GAN based Network(SRGAN) optimized for new perceptual loss(MSE-based content loss -> feature maps of the VGG network)
- confirm with an extensive mean opinion score(MOS) test
2. Method
-
Adversarial network architecture
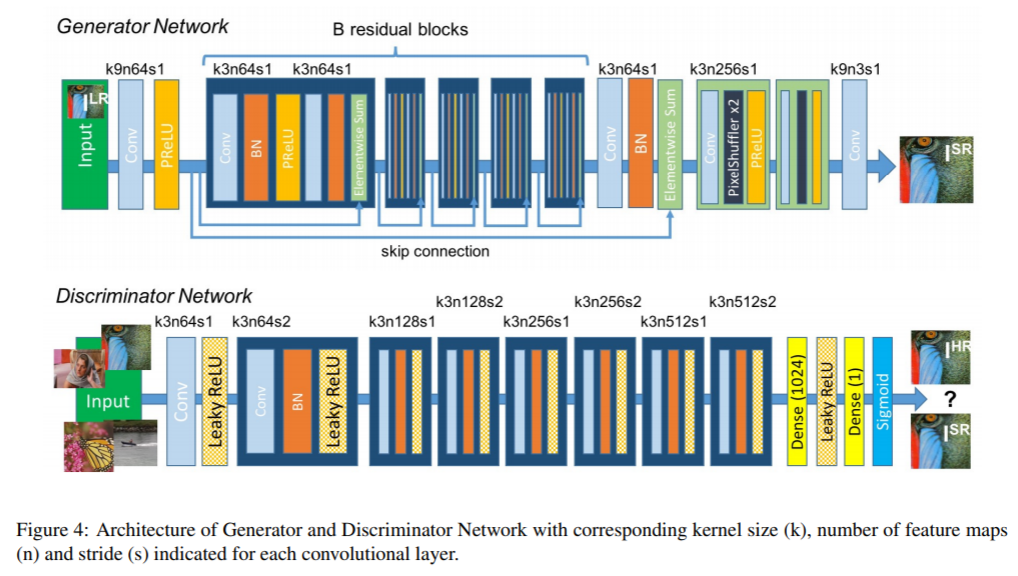
학습의 기본적 원리는 generator G가 SR인지 실제 HR 인지 구별하도록 학습된 discriminator D 를 속이도록 학습하는 것이다. 따라서 generator가 real image 같은 solution을 만들어 내게 된다. -
Perceptual Loss function
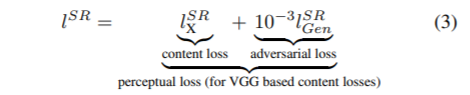 <- content loss는 mse or VGG Loss
<- content loss는 mse or VGG Loss- content loss :
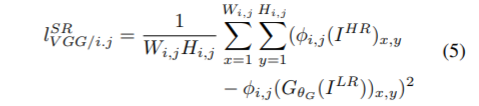 <- phi_i,j 는 VGG19에서 i번째 max pooling layer 전 j번째 convolution에서 얻어진 feature map
<- phi_i,j 는 VGG19에서 i번째 max pooling layer 전 j번째 convolution에서 얻어진 feature map - adversarial loss :
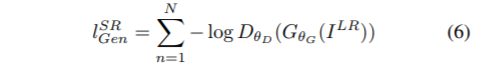
- content loss :
3. Experiment
-
Training detail :
-random sample of 350 thousand images from ImageNet database
-LR image는 HR image 에 bicubic kernel with factor r=4로 downsampling 해서 얻음.
-mini batch 는 16개의 random cropped 96x96 sub image
-Adam optimizer with beta = 0.9
-10^5 iteration까지는 learning rate 10^-4 그 이후 10^5는 10^-5로 학습. -
Mean opinion score (MOS) testing
26명의 평가자에게 SR이미지에 integral score from 1 (bad) to 5 (excellent) 를 매겨달라고 요청.
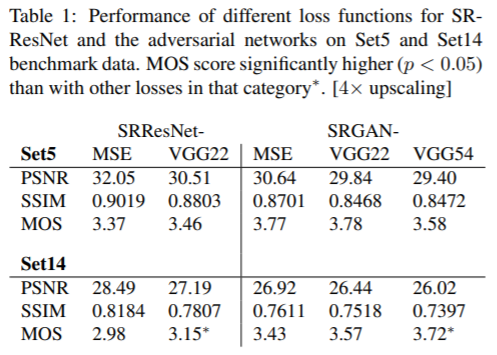
SRGAN-MSE 는 content loss 를 MSE로 사용, SRGAN-VGG22는 lower-level features를 나타내는 피쳐맵에서 loss define, SRGAN-VGG54는 higher level features의 피쳐맵에서 정의(이미지의 content 에 더욱 집중할 가능성).
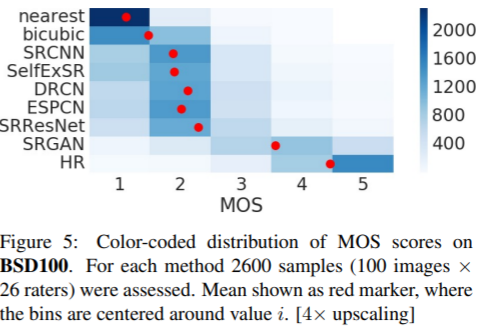
SRGAN이 가장 photo realistic 하게 outperform 하다는 것을 볼 수 있다.
4. Discussion
-SSIM이나 PSNR같은 기존의 quality check 방식은 실제 human vision 관점에서 photo realistic 을 체크하기 어렵다는 것을 보였다.
-SRGAN에서 네트워크가 깊어지면 high-frequency 때문에 점점 학습하기 어려워 진다.
-content loss에서 VGG loss는 깊은 레이어의 피쳐맵일 수록 perceptual하게 좋은 결과를 보여줌. 깊은 레이어의 피쳐맵은 content에 집중하고, adversarial loss는 texture detail에 집중하는 것을 확인.
-적용 상황에 따라 이상적인 loss function이 다름. ex) 메디컬 쪽에서 finer detail을 그럴듯하게 만들어내는 것은 적합치 않다.