2 ‐ Instalação e Configuração do Elastic Stack - BktechBrazil/elasticstacktotal GitHub Wiki
O Elasticsearch é um motor de busca e análise distribuído, baseado em Lucene, projetado para lidar com uma grande variedade de tipos de dados e formatos. É um componente central do Elastic Stack, atuando como a espinha dorsal para armazenamento, pesquisa e análise de dados.
Funcionalidade Chave:
- Pesquisa e Análise de Dados: O Elasticsearch permite realizar buscas complexas e oferece recursos analíticos poderosos em tempo real, essenciais para interpretar grandes volumes de dados.
- Distribuído por Natureza: Projetado para operar em um ambiente distribuído, oferece alta disponibilidade e capacidade de escalonar horizontalmente, ajustando-se à crescente quantidade de dados e tráfego.
- Schema-Free: Utiliza um formato JSON para os dados, permitindo flexibilidade na indexação de diferentes tipos de dados sem a necessidade de um esquema pré-definido.
A arquitetura do Elasticsearch é projetada para ser altamente escalável e resiliente. Vamos explorar os principais componentes que compõem um cluster do Elasticsearch, incluindo shards, réplicas e tipos de nodes.
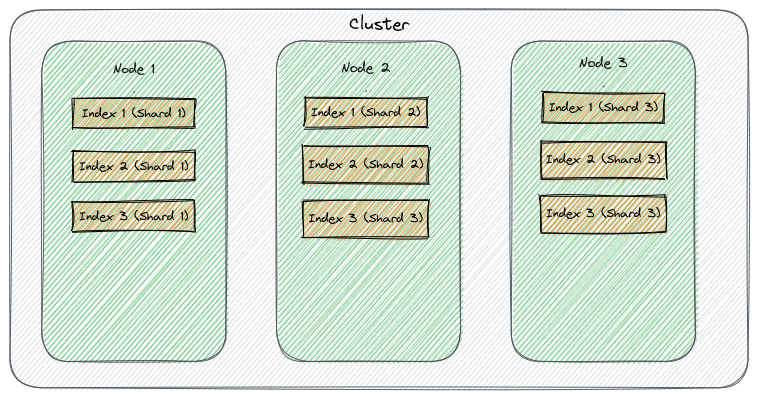
- Definição: Um cluster é uma coleção de um ou mais nodes (servidores) que juntos armazenam seus dados e fornecem recursos de indexação e pesquisa.
- Cluster ID: Cada cluster é identificado por um nome único, que é importante para a comunicação entre os nodes.
- Definição: Um node é um único servidor que faz parte do cluster e participa do armazenamento de dados, pesquisa, e outras operações essenciais.
-
Tipos de Nodes:
- Master Node: Responsável pela gestão do cluster, como a criação ou deleção de índices e a adição ou remoção de nodes.
- Data Node: Armazena dados e executa operações relacionadas a dados, como pesquisas e agregações.
- Ingest Node: Utilizado para pré-processamento de dados antes de serem indexados.
- Coordination Node: Encaminha operações para os nodes apropriados.
- Definição: Um índice é uma coleção de documentos que têm características semelhantes. É identificado por um nome único.
- Funcionalidade: O índice é a unidade de armazenamento e pesquisa no Elasticsearch.
-
Shard:
- Definição: Um shard é uma subdivisão de um índice. Cada índice pode ser dividido em múltiplos shards.
- Propósito: Isso permite a distribuição de dados e a realização de operações de forma paralela em diferentes nodes, melhorando o desempenho e a escalabilidade.
-
Réplica:
- Definição: Cada shard pode ter zero ou mais cópias chamadas réplicas.
- Propósito: Réplicas fornecem redundância de dados, o que aumenta a resiliência do sistema e permite consultas paralelas, melhorando a capacidade de leitura.
- Distribuição Automática de Shards: O Elasticsearch distribui automaticamente shards e réplicas pelos nodes do cluster, balanceando a carga e otimizando o uso de recursos.
- Recuperação de Falhas: Em caso de falha de um node, as réplicas nos outros nodes garantem que não haja perda de dados e que o sistema continue operando normalmente.
- Escalabilidade Horizontal: Adicionar mais nodes ao cluster permite que o Elasticsearch redistribua automaticamente shards e réplicas, aumentando a capacidade e o desempenho.
- Pesquisa Distribuída: As consultas são executadas em paralelo nos shards relevantes, resultando em respostas rápidas, mesmo com grandes volumes de dados.
| Banco de Dados Relacional | Elasticsearch |
|---|---|
| Banco de Dados | Índice |
| Tabela | Tipo |
| Linha | Documento |
| Coluna | Campo |
Explicações sobre a tabela:
-
Banco de Dados vs Índice: No Elasticsearch, um índice é como um 'banco de dados' em um sistema de banco de dados relacional. Os índices permitem que você divida seus documentos em grupos distintos.
-
Tabela vs Tipo: Anteriormente, no Elasticsearch, um 'tipo' era como uma 'tabela' em um banco de dados relacional. No entanto, a partir do Elasticsearch 6.0, os tipos estão em processo de desativação e todos os novos índices poderão conter apenas um tipo.
-
Linha vs Documento: No Elasticsearch, um 'documento' é como uma 'linha' em uma tabela de banco de dados relacional. Cada documento possui um conjunto único de campos e cada campo representa um dado específico naquele documento.
-
Coluna vs Campo: No Elasticsearch, um 'campo' é como uma 'coluna' em uma tabela de banco de dados relacional. Cada campo representa um tipo específico de dado, como texto, data, número etc., que é usado para indexar os documentos de maneira eficiente.
Sistema Operacional:
- Linux (Ubuntu 20.04 LTS utilizado como exemplo)
Requisitos:
- Espaço livre em disco de acordo com o tamanho da heap size e volume de dados a serem armazenados
As versões 8 do elasticsearch oferece a configuração de segurança de forma automática, ou seja, basta apenas descompactar o elasticsearch e iniciá-lo que ele irá realizar as seguintes configurações automáticas:
- Certificados e chaves para TLS são gerados para as camadas de transport e HTTP.
- As configurações de TLS são gravadas no arquivo elasticsearch.yml.
- Uma senha é gerada para o usuário elastic.
- Um token é gerado para o Kibana.
Vamos então iniciar nossa instância elasticsearch usando esse método:
sudo -i
useradd -d /opt/elastic -m elastic
chown elastic.elastic /opt/elastic -R
echo "elastic - nofile 65536" >> /etc/security/limits.conf
echo "vm.swappiness = 1" >> /etc/sysctl.conf
echo "vm.max_map_count = 262144" >> /etc/sysctl.conf
swapoff -a
sysctl -psu - elastic
cd /opt/elastic
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.12.1-linux-x86_64.tar.gz
tar zxfv elasticsearch-8.12.1-linux-x86_64.tar.gz
mv elasticsearch-8.12.1 elastic-instancia1
mkdir elastic-instancia1/config/certssu - elastic
cd /opt/elastic/elastic-instancia1
vi config/elasticsearch.yml
cluster.name: cluster-vinicius
node.name: node1cd /opt/elastic/elastic-instancia1
vi config/jvm.options.d/lab.options
-Xms1g
-Xmx1gcd /opt/elastic/elastic-instancia1
./bin/elasticsearch -p pid -dApós a instalação o seguinte resultado é exibido:
--------------------------- Security autoconfiguration information ------------------------------
Authentication and authorization are enabled.
TLS for the transport and HTTP layers is enabled and configured.
The generated password for the elastic built-in superuser is : G9nWw7MUdcRpPTUM_so+
If this node should join an existing cluster, you can reconfigure this with
'/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token <token-here>'
after creating an enrollment token on your existing cluster.
You can complete the following actions at any time:
Reset the password of the elastic built-in superuser with
'/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic'.
Generate an enrollment token for Kibana instances with
'/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana'.
Generate an enrollment token for Elasticsearch nodes with
'/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node'.
-------------------------------------------------------------------------------------------------
#### **Alterando a senha do usuário Elastic**
```bash
cd /opt/elastic/elastic-instancia1
./bin/elasticsearch-reset-password -i -u elastic
This tool will reset the password of the [elastic] user.
You will be prompted to enter the password.
Please confirm that you would like to continue [y/N]y
informe a senha 123456su - elastic
cd /opt/elastic/
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.12.1-linux-x86_64.tar.gz
tar zxfv kibana-8.12.1-linux-x86_64.tar.gz
mv kibana-8.12.1 kibana
cd kibana vi /opt/elastic/kibana/config/kibana.yml
server.host: "0.0.0.0"
# Configurando o nível de log e sua saida
logging.root.level: info
logging.appenders.default:
type: file
fileName: logs/kibana.log
layout:
type: jsonVamos gerar um novo token para que a kibana possa conectar no cluster. Para isso, vamos gerar o token na instância 1 conforme comandos abaixo:
su - elastic
cd /opt/elastic/elastic-instancia1
./bin/elasticsearch-create-enrollment-token -s kibanaGuarde o token gerado pois iremos utiliza-lo em breve!
su - elastic
cd /opt/elastic/kibana
./bin/kibanaObservação: No console o Kibana exibirá uma url. Abra seu navegador e acessa a url informada conforme exemplo abaixo:

A seguinte tela é exibida. Informe o token fornecido pelo elasticsearch para o ingresso do kibana conforme exemplo e depois clique no botão "Configure Elastic". Agora o Kibana solicita um token de validação para que a configuração possa iniciar. Esse token está na tela de start do Kibana

Observação: Algumas instalações podem solicitar um novo token pós fornecimento do token. Esse token de 6 caracteres está localizado no console quando vc iniciou o Kibana
su - elastic
cd /opt/elastic/kibana
./bin/kibana &su - elastic
cd /opt/elastic/kibana
kill -9 $(ps aux | grep node | grep cli/dist | cut -d " " -f 4)Vamos gerar um novo token para que a instância 2 possa ingressar no cluster. Para isso, vamos gerar o token na instância 1 conforme comandos abaixo:
su - elastic
cd /opt/elastic/elastic-instancia1
./bin/elasticsearch-create-enrollment-token -s nodeSalve o Token
cd /opt/elastic
tar zxfv elasticsearch-8.12.1-linux-x86_64.tar.gz
mv elasticsearch-8.12.1 elastic-instancia2Vamos agora ajustar os seguintes parâmetros do arquivo elasticsearch.yml na instância 2. Para isso siga o modelo abaixo:
cd /opt/elastic/elastic-instancia2
vi config/elasticsearch.yml
cluster.name: cluster-vinicius
node.name: node2
http.port: 9201
transport.port: 9301Crie o arquivo lab.options e adicione os valores de Xmx e Xms conforme exemplo abaixo:
cd /opt/elastic/elastic-instancia2
vi config/jvm.options.d/lab.options
-Xms1g
-Xmx1gSalve o arquivo e vamos iniciar a nossa instância 2.
cd /opt/elastic/elastic-instancia2
./bin/elasticsearch -p pid -d --enrollment-token <coloque o token aqui>Vamos gerar um novo token para que a instância 3 possa ingressar no cluster. Para isso, vamos gerar o token na instância 1 conforme comandos abaixo:
su - elastic
cd /opt/elastic/elastic-instancia1
./bin/elasticsearch-create-enrollment-token -s nodeSalve o Token
cd /opt/elastic
tar zxfv elasticsearch-8.12.1-linux-x86_64.tar.gz
mv elasticsearch-8.12.1 elastic-instancia3Vamos agora ajustar os seguintes parâmetros do arquivo elasticsearch.yml na instância 3. Para isso siga o modelo abaixo:
cd /opt/elastic/elastic-instancia3
vi config/elasticsearch.yml
cluster.name: cluster-vinicius
node.name: node3
http.port: 9202
transport.port: 9302Crie o arquivo lab.options e adicione os valores de Xmx e Xms conforme exemplo abaixo:
cd /opt/elastic/elastic-instancia3
vi config/jvm.options.d/lab.options
-Xms1g
-Xmx1gSalve o arquivo e vamos iniciar a nossa instância 3.
cd /opt/elastic/elastic-instancia3
./bin/elasticsearch -p pid -d --enrollment-token <coloque o token aqui>Em qualquer instancia execute o comando abaixo:
curl -X GET 'https://localhost:9200/_cat/nodes?v' -k -u elastic Deverá ser exibido 3 linhas contendo as informações das 3 instancias configuradas
Para configurar o Kibana com certificados autoassinados, você precisa gerar os certificados usando as ferramentas fornecidas pelo Elasticsearch e, em seguida, configurar o Kibana para usá-los. Abaixo está um guia passo a passo sobre como realizar esse processo.
**Pré-Requisitos Como root instalar o Unzip
su - root
apt install unzipO Elasticsearch fornece uma ferramenta chamada elasticsearch-certutil para gerar certificados. Você usará esta ferramenta para criar um certificado autoassinado que será utilizado pelo Kibana.
-
Abra o terminal no servidor onde o Elasticsearch está instalado.
-
Execute o seguinte comando para gerar uma chave de CA e seu certificado:
su - elastic bash cd /opt/elastic/elastic-instancia1 ./bin/elasticsearch-certutil ca --days 365 --pem --out /opt/elastic/kibana/config/ca.zip cd /opt/elastic/kibana/config unzip ca.zip
Esse comando cria um arquivo (
ca.zip) no diretórioconfig/kibana/.
cd /opt/elastic/elastic-instancia1
./bin/elasticsearch-certutil cert --ca-key /opt/elastic/kibana/config/ca/ca.key --ca-cert /opt/elastic/kibana/config/ca/ca.crt --dns localhost --ip 127.0.0.1 --days 365 --pem --name kibana --out /opt/elastic/kibana/config/kibana.zip
cd /opt/elastic/kibana/config
unzip kibana.zipEsse comando cria um arquivo (kibana.zip) no diretório config/kibana/.
Após gerar os certificados, você precisa configurar o Kibana para utilizá-los. Faça isso editando o arquivo de configuração kibana.yml.
-
Abra o arquivo
config/kibana.ymlno editor de sua preferência. -
Adicione ou atualize as seguintes configurações para apontar para os certificados que você acabou de criar:
server.ssl.enabled: true server.ssl.certificate: /opt/elastic/kibana/config/kibana/kibana.crt server.ssl.key: /opt/elastic/kibana/config/kibana/kibana.key
-
Salve e feche o arquivo
kibana.yml.
Após ajustar a configuração, você precisa reiniciar o Kibana para aplicar as alterações.
-
Se você estiver usando um sistema baseado em systemd, pode usar o seguinte comando:
cd /opt/elastic/kibana kill -9 $(ps aux | grep node | grep cli/dist | cut -d " " -f 4) ./bin/kibana &
-
Se você iniciou o Kibana manualmente, basta parar o processo atual e iniciá-lo novamente.
Após reiniciar o Kibana, acesse-o usando um navegador web e verifique se a conexão está segura, observando o ícone de cadeado na barra de endereço do navegador. Como os certificados são autoassinados, o navegador pode alertar sobre a segurança do certificado, mas você pode prosseguir para acessar o Kibana.
Esses passos garantem que a comunicação entre os usuários e o Kibana seja criptografada, aumentando a segurança do seu ambiente Elastic Stack.
O Elasticsearch oferece várias ferramentas de linha de comando que auxiliam na gestão, manutenção e interação com o cluster. Aqui estão alguns dos principais scripts de linha de comando e suas respectivas funções:
Observação: Todos os scripts citados estão dentro de do diretório padrão do Elasticsearch em $ES_PATH/bin
- Descrição: Este é o comando principal para iniciar uma instância do Elasticsearch. Quando executado sem parâmetros, ele inicia o servidor Elasticsearch com a configuração padrão.
- Função: Iniciar o servidor Elasticsearch.
- Descrição: Ferramenta utilizada para gerenciar o keystore do Elasticsearch, um arquivo seguro onde são armazenadas configurações sensíveis, como senhas.
- Função: Adicionar, listar ou remover entradas no keystore.
- Descrição: Utilitário para gerenciar aspectos específicos de nós do Elasticsearch. Pode ser usado para tarefas como mudar a alocação de shards ou realizar operações de recuperação em nível de nó.
- Função: Gerenciar operações em nível de nó no cluster Elasticsearch.
- Descrição: Comando usado para gerenciar plugins do Elasticsearch. Permite instalar, remover e listar plugins.
- Função: Instalar, remover e listar plugins no Elasticsearch.
- Descrição: Script utilizado para configurar senhas para usuários internos do Elasticsearch após a ativação do X-Pack security.
- Função: Configurar senhas de usuários internos de forma interativa ou automática.
- Descrição: Ferramenta de linha de comando para ajudar na recuperação de shards. Pode ser usada para reparar shards corrompidos ou para remover a alocação de um shard específico.
- Função: Auxiliar na recuperação e reparo de shards.
- Descrição: Interface de linha de comando que permite a execução de consultas SQL no Elasticsearch, facilitando a interação com os dados de forma mais familiar para quem está acostumado com SQL.
- Função: Executar consultas SQL no Elasticsearch.
- Descrição: Ferramenta para facilitar a criação e gestão de certificados SSL/TLS para o Elasticsearch, ajudando na configuração de comunicação segura entre os nós do cluster.
- Função: Gerar e gerenciar certificados SSL/TLS para o cluster.
- Descrição: Utilitário para ajudar na migração de configurações entre diferentes versões do Elasticsearch, garantindo a compatibilidade e facilitando upgrades.
- Função: Auxiliar na migração de configurações do Elasticsearch.
- Descrição: Uma ferramenta introduzida em versões mais recentes do Elasticsearch que permite redefinir as senhas de usuários internos do Elasticsearch. É particularmente útil em situações onde a senha de um usuário é perdida ou precisa ser alterada por razões de segurança.
- Função: Redefinir senhas de usuários internos de forma interativa ou automática, oferecendo um método direto para atualizar credenciais sem necessitar acessar o sistema de gerenciamento de usuários completo.
Essas ferramentas de linha de comando são essenciais para a administração e operação eficaz de clusters Elasticsearch, proporcionando uma variedade de funcionalidades para gerenciamento, segurança, manutenção e interação com os dados.
A API _CAT do Elasticsearch é uma API concisa voltada para a monitorização e obtenção de informações sobre o estado do cluster Elasticsearch de maneira legível para humanos. Ela fornece uma visão geral rápida do desempenho, saúde e estatísticas do cluster, facilitando a identificação de problemas e o monitoramento do estado geral do sistema.
Aqui estão as funções da API _CAT do Elasticsearch apresentadas em formato de tabela, incluindo uma breve descrição e o exemplo de chamada para cada função:
| Função | Descrição | Exemplo de Chamada |
|---|---|---|
/_cat/health |
Fornece uma visão instantânea da saúde do cluster. | GET /_cat/health?v |
/_cat/nodes |
Exibe informações básicas sobre os nós do cluster. | GET /_cat/nodes?v |
/_cat/indices |
Lista todos os índices no cluster e fornece informações detalhadas sobre cada um. | GET /_cat/indices?v |
/_cat/shards |
Apresenta informações detalhadas sobre os shards de cada índice. | GET /_cat/shards?v |
/_cat/master |
Mostra informações sobre o nó mestre do cluster. | GET /_cat/master?v |
/_cat/allocation |
Fornece informações sobre a alocação de disco de cada nó. | GET /_cat/allocation?v |
/_cat/count |
Retorna uma contagem de documentos em um ou mais índices. | GET /_cat/count/index_name?v |
/_cat/recovery |
Exibe informações sobre o processo de recuperação de dados nos índices. | GET /_cat/recovery?v |
/_cat/aliases |
Lista todos os aliases de índice e para quais índices eles apontam. | GET /_cat/aliases?v |
/_cat/thread_pool |
Fornece detalhes sobre os thread pools em cada nó. | GET /_cat/thread_pool?v |
Cada uma dessas funções da API _CAT oferece uma maneira eficiente de monitorar e gerenciar o Elasticsearch, proporcionando insights rápidos sobre diversos aspectos do cluster.