Data mappings - AtlasOfLivingAustralia/documentation GitHub Wiki
⚠️ Note: Steps 1–4 on this page (Collectory configuration of provider codes, institutions, and collections) apply to all Living Atlas deployments. Step 5 (processing and indexing) describes the legacybiocache-storeapproach. For new installations, use pipelines for data processing instead of biocache commands.
- Introduction
- Overview
- STEP 1: Find DwC-A Provider Values (institutionCode and collectionCode) in occurrence dataset
- STEP 2: Create Institutions and/or Collections (if they do not exist)
- STEP 3: Add Provider Codes and Map Provider Codes in your LA Collectory
- STEP 4: Add Record Consumers for Data Resources
- STEP 5: Re-process and re-index in biocache
- Example
- Testing
- In case don't have collectionCode in your datasets
- Missing mappings
Data mappings link Institutions and/or Collections in your LA Collectory with DwC-A institutionCode and collectionCode values in Occurrence records so that Data Resources are linked with their respective LA entities when ingested by biocache. We explain here how to map institutionCode and collectionCode in our DwC-A occurrences files to Institutions and Collections in the LA Collectory service, so that records and counts are associated with them in the Collectory service.
To form these links we map institutionCode and collectionCode acronym values in our DwC-A dataset with their equivalent Collections and Institutions in the LA Collectory.
NOTE: Here, we refer to Institutions and Collections collectively as ‘Providers’, which are not the same as and should not be confused with LA ‘dataProviders’.
These links are all optional:
- Some Living Atlases are not using Data Providers
- LAs which are largely connecting specimen data, and similarly some Living Atlases which are largely observational aren't using Institutions…
- Create LA Provider Codes from Provider values in incoming DwC-A datasets
- Create target LA Providers (Institutions and Collections having UIDs in your LA)
- Map incoming Provider Codes to target LA Providers using LA Provider Maps
- Flag target LA Providers as Record Consumers in LA Data Resources
- Process/Index LA Data Resource in biocache store
To create the Provider Map below, we first need to know what Provider values are in the incoming datasets. These values do not necessarily map to values in the LA Collectory, and biocache doesn't automatically detect them even if they are the same.
There are several ways to obtain a list of acronyms to be added as LA Provider Codes:
- Download occurrence DwC-A to a local file
- Open the file using Excel
- Get unique values from columns
institutionCodeandcollectionCode
IMPORTANT : works with resources having a number of occurrences lower than the maximum number of lines in Excel (around 1 million)
# Imagine that the institutionCode is in the 3rd column and collectionCode in the 4th
export INST_IDX=3
export COLL_IDX=4
echo "Institution codes:"
cat occurrence.txt | tail -n +2 | awk -F" " -v a="$INST_IDX" '{print $a}' | sort | uniq
echo "Collection codes:"
cat occurrence.txt | tail -n +2 | awk -F" " -v a="$COLL_IDX" '{print $a}' | sort | uniq
The -F indicates the field separator so can be a TAB (introduced in bash with Ctlr-v + TAB) a comma or whatever field separator you are using.
If you have logger warns enabled you can see the codes during a first re-index, with lines like:
INFO : [DataLoader] - The current institution codes for the data resource
INFO : [DataLoader] - The current collection codes for the data resource
- Create LA Institutions that correspond to the institutionCode Provider Values found in STEP 1 above.
https://collectory.URL_to_your_LA_portal/institution/list
- Create LA Collections that correspond to the collectionCode Providers values found in STEP 1 above.
https://collectory.URL_to_your_LA_portal/collection/list
Using the list of institutionCodes and collectionCodes found in STEP 1 above, we create those tokens as Provider Codes and map them with Provider Maps to entities having UIDs in our LA Collectory.
If the provider codes do not exist, enter them using “Manage provider codes” page:
https://collectory.URL_to_your_LA_portal/providerCode/list
To avoid pagination and get a longer list, you can type something like:
https://collectory.URL_to_your_LA_portal/providerCode/list?offset=0&max=100
Using Provider Codes created above, show a list and create/update provider maps between LA Provider Codes and LA Institutions and/or Collections on the following pages:
https://collectory.URL_to_your_LA_portal/providerMap/list
You can also get a longer list with:
https://collectory.URL_to_your_LA_portal/providerMap/list?sort=id&max=100&offset=0&order=asc
If you haven’t already (and before ingesting with biocache) create an LA Data Resource for the incoming dataset and configure it to enable Provider Map linking of data.
If the dataResource is linked to a collection:
- https://collectory.URL_to_your_LA/dataResource/editConsumers/drXXX?source=co
You should see a list of available LA Collections. Drag Collection(s) into the ‘Record Consumers’ box. Update and verify.
Link the dataResource to an institution :
- https://collectory.URL_to_your_LA/dataResource/editConsumers/drXXX?source=in
You should see a list of available LA Institutions. Drag Institution(s) into the ‘Record Consumers’ box. Update and verify.
biocache process -dr drXXX
biocache index -dr drXXX
Or
biocache ingest -dr drXXX
Lets use this dataResource as example:
https://colecciones.gbif.es/public/show/dr684
First we get the field inst/col indexes (see that index starts in zero):
egrep "<id index|institutionCode|collectionCode" meta.xml
<id index="0" />
<field index="6" term="http://rs.tdwg.org/dwc/terms/institutionCode"/>
<field index="7" term="http://rs.tdwg.org/dwc/terms/collectionCode"/>
And now we get the codes, printing that fields (but now we use the index + 1 in awk), sorting and getting unique values:
$ export INST_IDX=7
$ export COLL_IDX=8
$ cat occurrence.txt | tail -n +2 | awk -F" " -v a="$INST_IDX" '{print $a}' | sort | uniq
IEOCA
$ cat occurrence.txt | tail -n +2 | awk -F" " -v a="$COLL_IDX" '{print $a}' | sort | uniq
IEO
So in:
https://colecciones.gbif.es/providerCode/list?offset=0&max=100
we look for IEOCA and IEO if they don't exist we create it:

And now the provider map:
https://colecciones.gbif.es/providerMap/list?sort=id&max=100&offset=0&order=desc

Later we go to the collectory data resource, in our example:
https://colecciones.gbif.es/dataResource/show/dr684
and we set the record consumers

Your can check if some institution and collection well mapped (*):
https://collections.ala.org.au/ws/lookup/inst/<institutionCode>/coll/<collectionCode>
For instance:
https://colecciones.gbif.es/lookup/inst/IEOCA/coll/IEO
And via the ws check the linkedRecordConsumers, in our example:
https://colecciones.gbif.es/ws/dataResource/dr684
And recordsProviderMapping in:
https://colecciones.gbif.es/ws/collection/co245
{
"provider": {
"name": "GBIF ES IPT",
"uri": "https://colecciones.gbif.es/ws/dataProvider/dp2",
"uid": "dp2"
},
"institution": {
"name": "Instituto Español de Oceanografía. Centro Oceanográfico de Canarias",
"uri": "https://colecciones.gbif.es/ws/institution/in105",
"uid": "in105"
},
"linkedRecordConsumers": [
{
"name": "Colección de fauna marina del Centro Oceanográfico de Canarias",
"uri": "https://colecciones.gbif.es/ws/collection/co245",
"uid": "co245"
},
{
"name": "Instituto Español de Oceanografía. Centro Oceanográfico de Canarias",
"uri": "https://colecciones.gbif.es/ws/institution/in105",
"uid": "in105"
}
],Also this simple non-official util helps to check data mappings in the collectory.
(*) Note: If you use chrome, check this extension or similar to visualize well json pages. Firefox do this well out of the box.
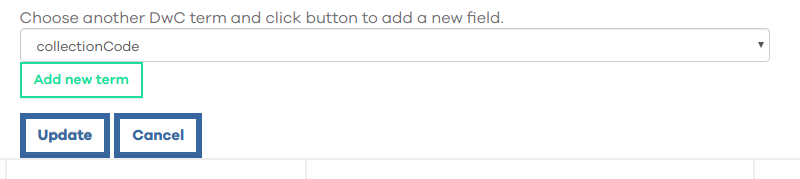
If some of your publishers do not include collectionCode in their datasets a solution is to include a default collectionCode using the "Default values for DwC fields".
A capture of adding default collectionCode in data resource edition:
You can search for collections or institutions without mappings:
SELECT c.id, c.acronym, c.name FROM collection c WHERE c.id NOT IN (SELECT pm.collection_id FROM provider_map pm);
SELECT i.id, i.acronym, i.name FROM institution i WHERE i.id NOT IN (SELECT pm.institution_id FROM provider_map pm);Also you can search for drs without institution:
and without collection code:
The same in pipelines indexes:
and: