Sauvegardes - AtlasOfLivingAustralia/Documentation-en-francais GitHub Wiki
Comment faire une sauvegarde
Sauvegarde de l'entrepôt de données Cassandra
Sauvegarde Cassandra consiste basiquement à faire un instantané de l'entrepôt d'occurrence.
Cassandra est livré avec des outils en ligne de commande que nous allons utilisez pour cette tâche :
- cassandra-cli
- nodetool
Résumé de l'entrepôt d'occurrence Cassandra
Localisation de là où les données d'occurrence indexées sont stockées :
$ cd /data/cassandra/data/occ
(pour fournir la description du répertoire)
Connectez-vous à Cassandra et jetez un œil à l'aperçu des enregistrements stockés :
$ cassandra-cli
[default@unknown] use occ;
[default@occ] list occ limit 1;
Dans la dernière ligne, un UUID est généré automatiquement par Cassandra. Tant qu'un enregistrement est contenu par la même ressource de données déterminée par druid, l'UUID sera stable.
C'est également possible si vous souhaitez imprimer un enregistrement spécifique :
[default@occ] get occ where uuid = 'e47e0e31-ff9c-4f31-b598-34f452cb023f';
Faire un instantané
En supposant que c'est la première fois que nous faisons un instantané, ce répertoire devrait être vide avant que nous fassions la ligne suivante :
$ cd /data/cassandra/data/occ/occ && ls
(Par défaut, ce répertoire est la propriété de root, donc vous aurez besoin de l'instruction sudo.)
Maintenant, faites un instantané de occ, dans lequel nous stockons les données d'occurrence :
$ nodetool snapshot occ
Le terminal doit renvoyez quelque chose de similaire à ceci :
Requested creating snapshot for: occ
Snapshot directory: 1406163740504
Un répertoire 1406163740504 est créé sous /data/cassandra/data/occ/occ/snapshots. Si vous listez les fichiers sous le répertoire 1406163740504, vous remarquerez qu'il a les mêmes fichiers dans /data/cassandra/data/occ/occ. 1406163740504 est l'emplacement où vous sauvegardez l'entrepôt d'occurrences et /data/cassandra/data/occ/occ est le lieu où les données d'occurrence sauvegardées seront restaurées.
Pointé vers une instance distante de Cassandra
Dans le cas où vous utiliser une instance de Cassandra à distance. Pour ce faire, mettez à jour listen_address: localhost dans/etc/cassandra/cassandra.yaml en remplaçant 'localhost' wpar le nom de domaine de la version distante de Cassandra.
Sauvegarde de l'index Solr
@Todo Synopsis
L'index Solr est stocké dans /data/solr/biocache/data. En regardant dans le répertoire data, vous voyez les répertoires index et tlog. data est l'unité que vous voulez sauvegarder.
Faire une copie de l'index Solr
$ cd /data/solr/biocache
$ sudo mkdir solr-index-backup
$ sudo chown tomcat7:tomcat7 solr-index-backup
A ce niveau-là, pour index et tlog qui sont dans solr-index-backup, vous pouvez les copier depuis /data/solr/biocache/data à partir de localhost ou d'un hôte distant. Une fois que ces contenus sont en place, assurez-vous qu'ils ont tomcat7 définis comme propriétaire et comme groupe ; tomcat7 est l'utilisateur/groupe par défaut sur Ubuntu qui exécute Tomcat.
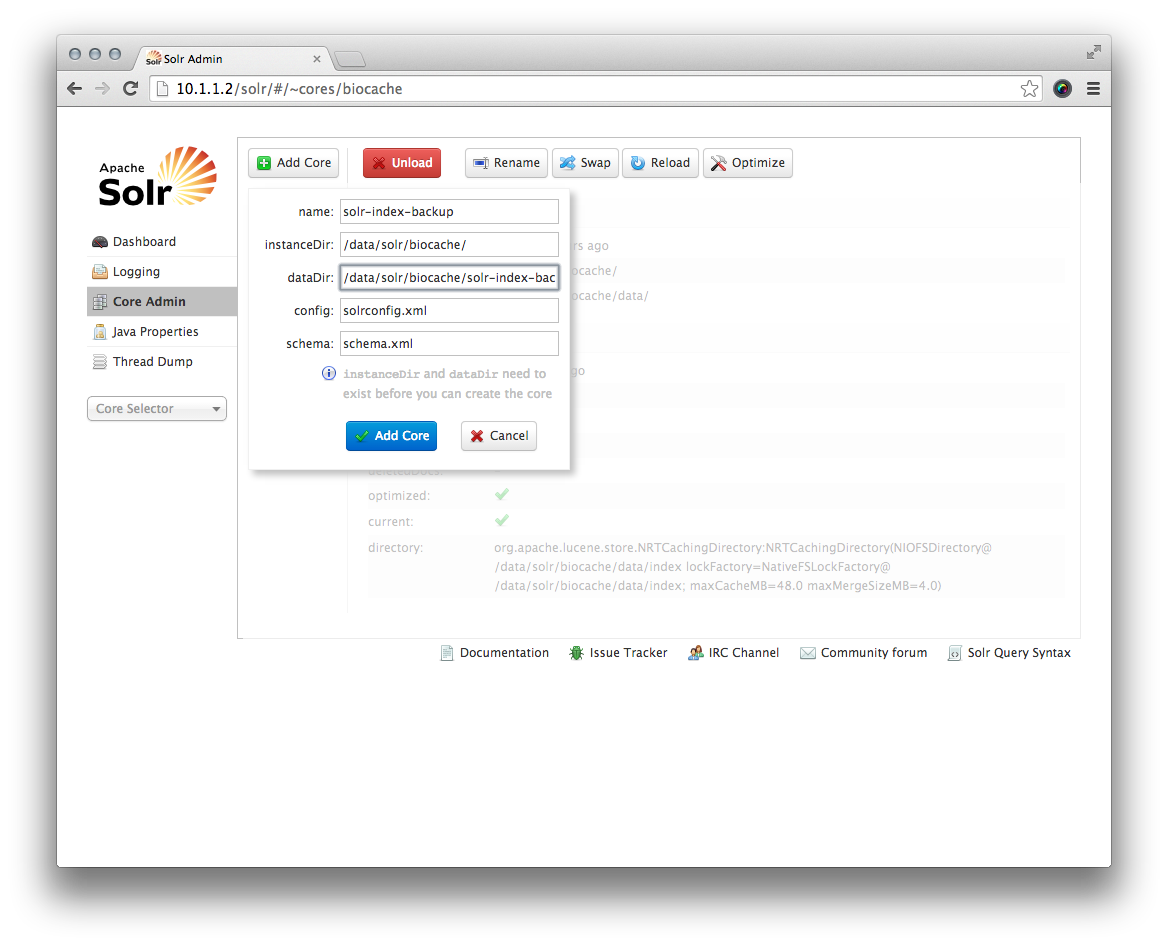
Maintenant, vous allez créer un noyau Solr qui utilise cette sauvegarde et qui peut être changé plus tard. Pour ce faire, naviguez dans votre navigateur vers la page d'administration Solr à l'adresse http://10.1.1.2/solr/#/~cores/biocache et cliquez sur 'Add core' puis entrez les valeurs comme montrez dans l'image :
Une fois que le nouveau core a été créé avec succès, cliquez sur le nouveau core et voyez si tous les détails de la section 'Core' et 'Index' sont tous les mêmes à l'exception des répertoires de fichiers:
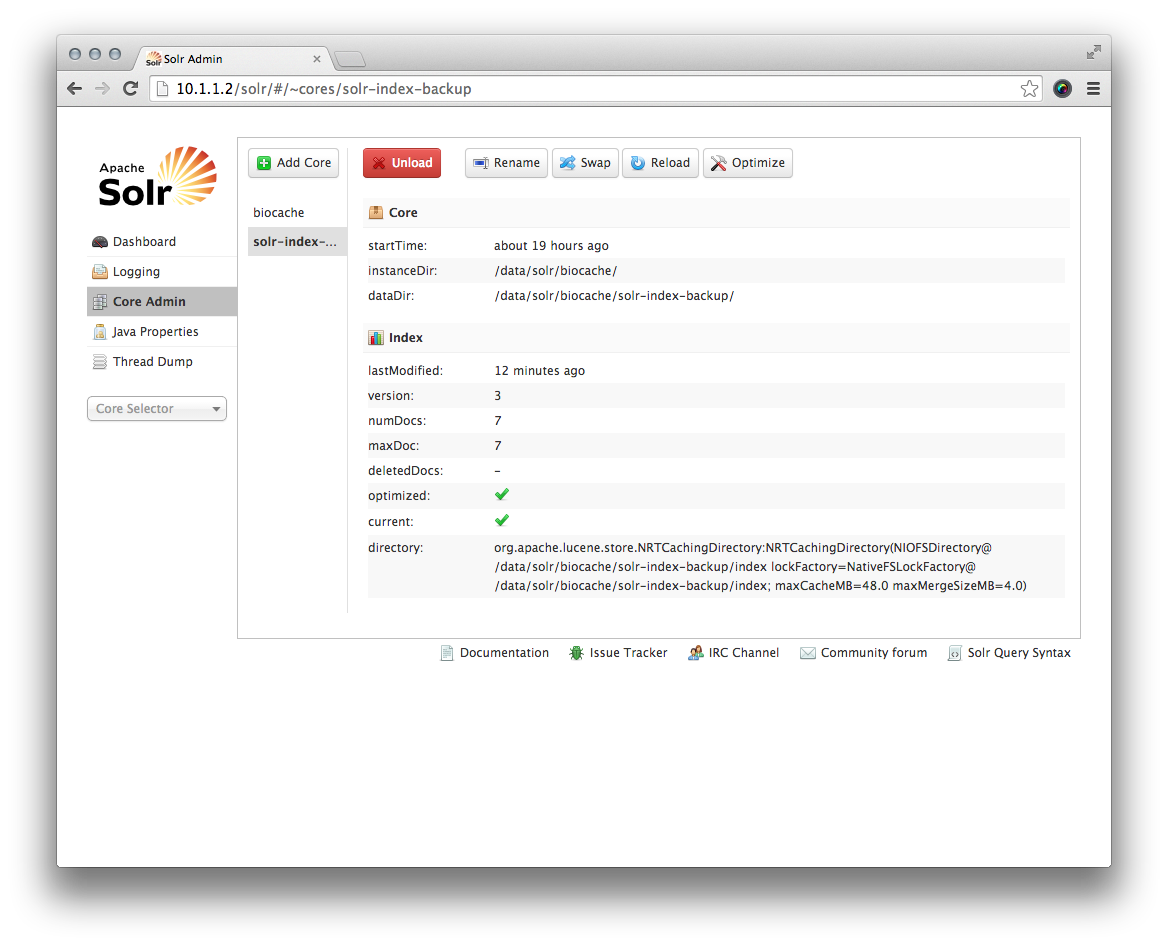
Lorsque vous êtes prêt, vous pouvez utiliser la fonction 'Swap' pour utiliser la sauvegarde.