Vision transformer - AshokBhat/ml GitHub Wiki
About
- Vision Transformer (ViT)
- Transformer model for vision processing tasks
- Introduced in 2020
Comparison
ViT demonstrates excellent performance when trained on sufficient data, outperforming a comparable state-of-the-art CNN with four times fewer computational resources.
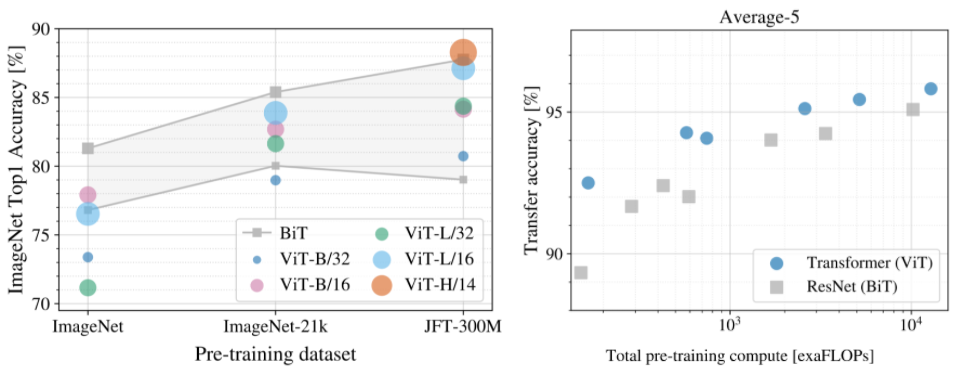
Source: https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html