Triton Inference Server - AshokBhat/ml GitHub Wiki
About
- Open-source inference serving software
- To deploy AI models
Hardware support
- README says
Triton is optimized to provide the best inferencing performance by using GPUs, but it can also work on CPU-only systems
Backends
TensorRT
PyTorch
TensorFlow
- On Jetsons, does not use docker images
- On non-Jetson systems, use docker images (with NGC TensorFlow docker used by default)
TFLite backend (armnn_tflite)
OpenVINO
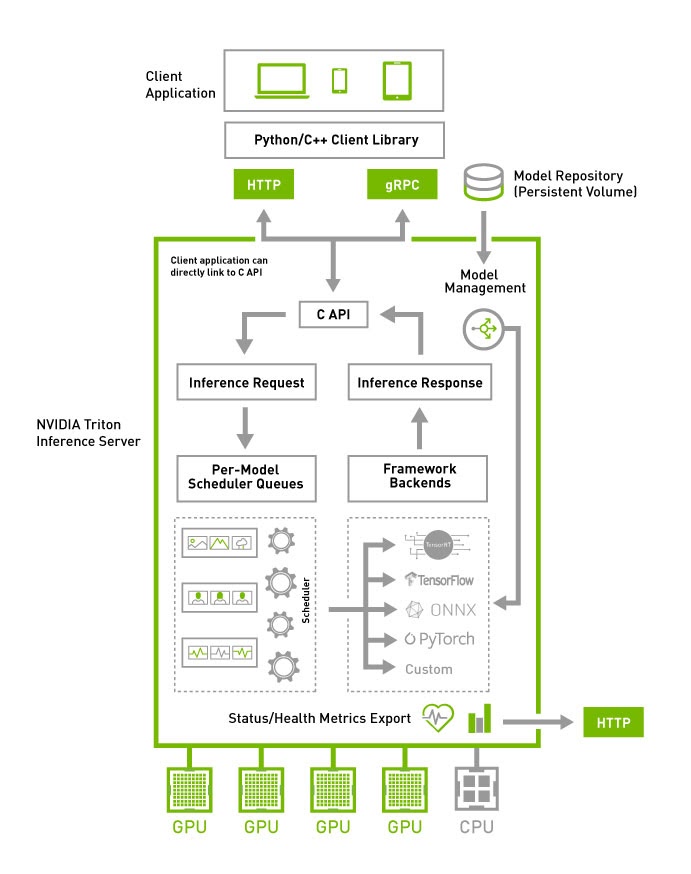
Block diagram
See also