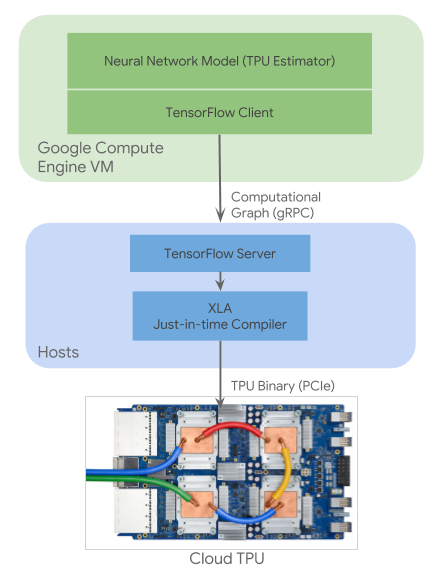
TPU - AshokBhat/ml GitHub Wiki
About
- Google designed ASIC for Deep learning
- In-order CISC instructions
- BFloat16 and INT8 support
- Designed to perform fast, bulky matrix multiplication
Products
| TPUv1 | TPUv2 | TPUv3 | TPUv4i | |
|---|---|---|---|---|
| GA | 2015 | 2017 | 2018 | 2020 |
| INT8 | :+1: | :+1: | :+1: | :+1: |
| BF16 | :x: | :+1: | :+1: | :+1: |
| FP32 | :x: | :+1: | :+1: | :+1: |
| Training | :x: | :+1: | :+1: | :x: |
| Inference | :+1: | :+1: | :+1: | :+1: |
| TOPS | 23 | 45 | 90 | 123 |
| Node | 28nm | 16nm | 16nm | 7nm |
| TDP(W) | 75 | 280 | 450 | 175 |
Background of TPUv1
Starting as early as 2006, we discussed deploying GPUs, FPGAs, or custom ASICs in our datacenters. We concluded that the few applications that could run on special hardware could be done virtually for free using the excess capacity of our large datacenters, and it’s hard to improve on free.
The conversation changed in 2013 when a projection where people use voice search for 3 minutes a day using speech recognition DNNs would require our datacenters to double to meet computation demands, which would be very expensive to satisfy with conventional CPUs.
Thus, we started a high-priority project to quickly produce a custom ASIC for inference (and bought off-the-shelf GPUs for training). The goal was to improve cost-performance by 10X over GPUs. Given this mandate, the TPU was designed, verified, built, and deployed in datacenters in just 15 months.
Source: "In-Datacenter Performance Analysis of a Tensor Processing Unit" Paper by Google.
PyTorch support
TensorFlow support