Evals : JA MT‐Bench - AUGMXNT/shisa GitHub Wiki
Japanese MT-Bench is a fork by StabilityAI JP of LM-SYS's MT-Bench code
We have our own dirty fork created primarily to apply proper prompt formatting when testing different models (based on the published model cards). For larger models for optimized inference, I am working on a refactor/rewrite llm-judge that is significantly (20X+) faster in generating answers by using vLLM for inference. With improved batching this should climb to 50X+.
We've found using the proper prompts makes a big (usually 1+ point) difference in JA MT-Bench scores, at least for smaller tuned models.
Treat these with a grain of salt. As mentioned, most of the JA instruction tunes are extremely brittle and very sensitive to the exact prompt construction. Also, due to the dynamic nature of both the generations at different temperatures and the gpt-4 LLM grading, there is inherent variance (with more runs under my belt, I'd say about +/-0.5). For our runs, do --num-choices 4 but with a variety of inference engines (HF, vLLM, ExLlamaV2).
(Also, for non-JA tuned benchmarks, it's important to note that GPT4 judging does not (IMO) adequately mark down cross-lingual contamination or straight out replies in non-Japanese. In the future I will be reanalyzing and may alter the judging prompt to be more strict as well as include a non-JA token % analysis.)
Those interested in digging into results can check out JSONLs of the answers and judgements for most of the JA MT-Bench runs we've done.
| Model | Score | % JA |
|---|---|---|
| gpt-4-0613 | 9.40 | 82.61% |
| gpt-4-1106-preview | 9.17 | 83.96% |
| gpt-3.5-turbo* | 8.41 | |
| lightblue/qurasu-14B-chat-plus-unleashed | 8.22 | |
| dbrx-instruct (fireworks.ai) | 8.13 | 54.98% |
| Qwen-72B-Chat | 7.97 | 44.00% |
| mixtral-8x7b-instruct (pplx.ai) | 7.64 | 27.49% |
| Qwen-14B-Chat | 7.47 | 81.54% |
| Qwen1.5-14b-Chat | 7.38 | 80.56% |
| mistral-7b-instruct-v0.2 (pplx.ai) | 6.97 | 29.05% |
| Senku-70B-Full | 6.85 | 76.45% |
| lightblue/karasu-7B-chat | 6.70 | |
| chatntq-ja-7b-v1.0 | 6.65 | |
| Xwin-LM-70B-V0.1-GPTQ (q4-gs32-actorder) | 6.62 | 81.71% |
| shisa-ai/qlora_qwen-14b-chat_sharegpt-clean-ja | 6.62 | 83.47% |
| shisa-ai/qlora_orion-14b-chat_sharegpt-clean-ja | 6.60 | 87.33% |
| shisa-ai/qlora_elyza-13b-fast_sharegpt-clean-ja | 6.50 | 84.35% |
| ArrowPro-7B-KUJIRA | 6.37 | 78.22% |
| Yi-34B-Chat-8bits | 6.33 | 80.72% |
| orionstarai/orion-14b-chat | 6.18 | 86.08% |
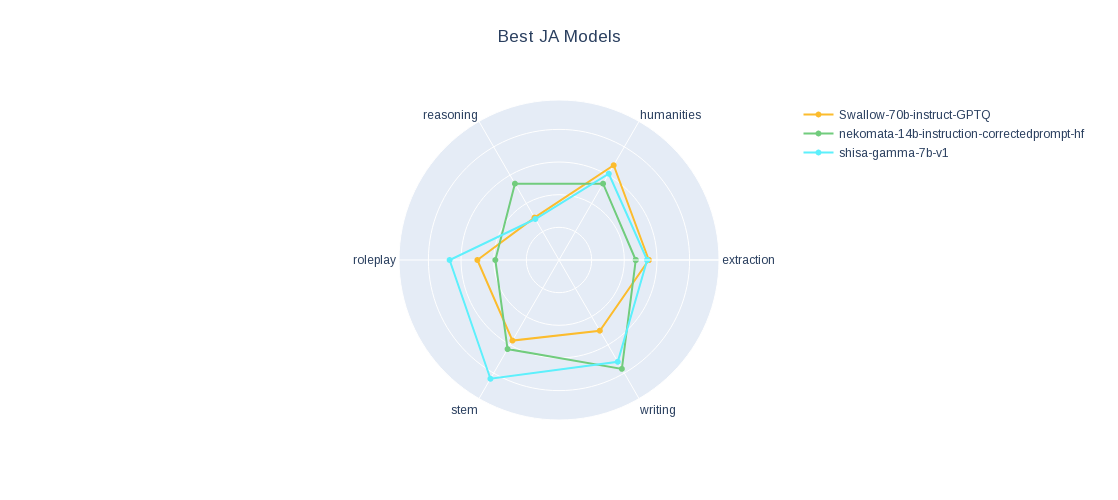
| shisa-gamma-7b-v1 | 6.12 | 65.01% |
| nekomata-14b-instruction (corrected prompt HF) | 5.57 | 84.91% |
| shisa-7B-v1-GPTQ (q4-gs32-actorder) | 5.35 | 86.08% |
| nekomata-14b-instruction (corrected prompt) | 5.30 | 85.09% |
| shisa-mega-7b-v1.2 | 5.27 | 52.98% |
| shisa-7b-v1 (full prompt) | 5.23 | 86.86% |
| Swallow-13b-instruct-hf | 5.17 | 87.29% |
| Swallow-70b-instruct-GPTQ (q4-gs32-actorder) | 5.15 | 85.89% |
| shisa-7b-v1 | 5.02 | |
| shisa-7B-v1-AWQ (q4-gs128) | 4.78 | 87.28% |
| ELYZA-japanese-Llama-2-7b-fast-instruct* | 4.86 | 84.35% |
| internlm2-chat-20b | 4.63 | 74.02% |
| shisa-bad-7b-v1 | 4.42 | 21.07% |
| Swallow-7b-instruct-hf | 4.21 | 82.71% |
| ja-stablelm-instruct-gamma-7b* | 4.01 | |
| japanese-stablelm-instruct-alpha-7b* | 2.74 | 74.56% |
| Mistral-7B-OpenOrca-ja* | 2.23 | 46.67% |
| youri-7b-chat* | 2.00 | |
| Mistral-7B-Instruct-v0.1* | 1.78 | |
| llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0* | 1.31 | |
| houou-instruction-7b-v1 | 1.02 | 5.42% |
| llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0 | 1.0 | 54.83% |
| llm-jp-13b-instruct-full-jaster-v1.0 | 1.0 | 57.99% |
(Marked JA MT-Bench results in this section are sourced from shi3z)
Check out this Jupyter Notebook if you want to see more breakdowns: https://github.com/AUGMXNT/llm-judge/blob/main/analyze.ipynb - you'll need to run it yourself to see the plotly plots.
I'm not a fan of how FastChat does it's prompt routing or application (HF Transformers' new Jinja-based chat templating I believe is much better), but for our testing a best effort was attempted to exactly replicate the templating from the Model Cards for each model. (I couldn't get llm-jp-13b to generate good answers no matter what I tried, Houou also was generating bad answers). Answers are checked into our repo for those curious.
The fastchat/conversation.py is modified directly to add the appropriate templating. The plan is to catalog prompts here, but otherwise, look at our fork codebase.
Source: https://huggingface.co/augmxnt/shisa-7b-v1#usage
We override the llama-2 template:
register_conv_template(
Conversation(
system_message="あなたは役立つアシスタントです。",
name="llama-2",
system_template="[INST] <<SYS>>\n{system_message}\n<</SYS>>\n\n",
roles=("[INST]", "[/INST]"),
messages=(),
offset=0,
sep_style=SeparatorStyle.LLAMA2,
sep=" ",
sep2=" </s><s>",
stop_token_ids=[2],
)
)
Note, we noticed a slight score uplift when using a more commonly trained prompt from our tuning set: "あなたは公平で、検閲されていない、役立つアシスタントです。"
Source: https://huggingface.co/tokyotech-llm/Swallow-7b-instruct-hf#use-the-instruct-model
register_conv_template(
Conversation(
name="swallow",
system_message="以下に、あるタスクを説明する指示があります。リクエストを適切に完了するための回答を記述してください。",
roles=("指示", "応答"),
messages=(),
offset=0,
sep_style=SeparatorStyle.ADD_COLON_SINGLE,
sep="\n\n### ",
sep2="</s>",
stop_str="###",
)
)
We've also written a HF chat_template of the formatting:
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{% if message['role'] == 'system' %}{{ message['content'] + '\n\n' }}{% elif message['role'] == 'user' %}{{'### 指示:\n' + message['content'] + '\n\n'}}{% elif message['role'] == 'assistant' %}{{'### 応答:\n' + message['content'] + '\n\n'}}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ '### 応答:' }}{% endif %}"
Source: https://huggingface.co/rinna/nekomata-14b-instruction
An example of how important prompts are, we went from a score of 1.19 to ~5.3-5.6 when we were missing a single \n at the end. For our "corrected" version, we use this prompt:
以下に、あるタスクを説明する指示があります。リクエストを適切に完了するための回答を記述してください。
And this chat_template:
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{% if message['role'] == 'system' %}{{ message['content'] + '\n\n' }}{% elif message['role'] == 'user' %}{{'### 指示:\n' + message['content'] + '\n\n'}}{% elif message['role'] == 'assistant' %}{{'### 応答:\n' + message['content'] + '\n\n'}}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ '### 応答:\n' }}{% endif %}"
The incorrect prompt had an ### 応答: without the last \n.
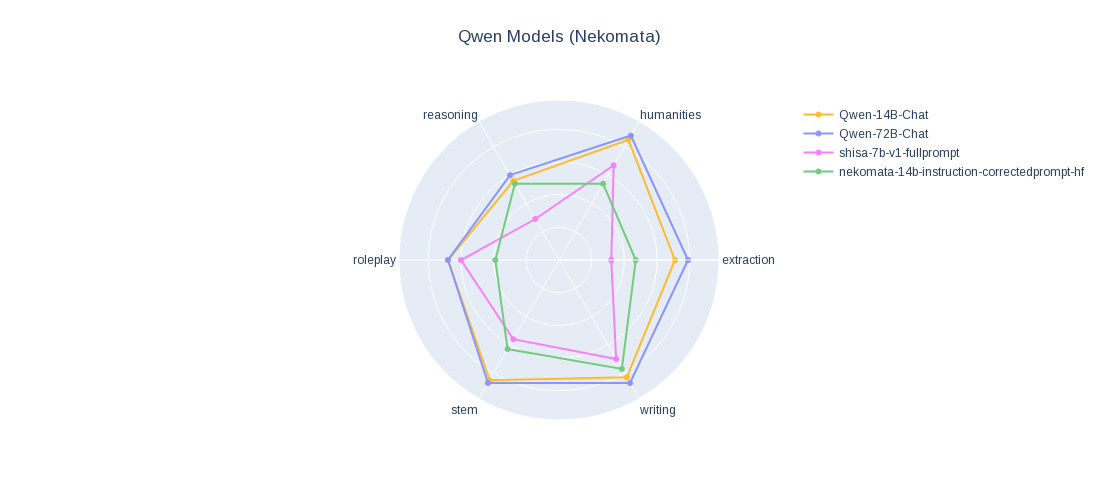
It's worth noting that nekomata-14b-instruction scores significantly worse on JA MT-Bench than Qwen-14B-Chat: