Transaction‐Level Modeling - 180D-FW-2024/Knowledge-Base-Wiki GitHub Wiki
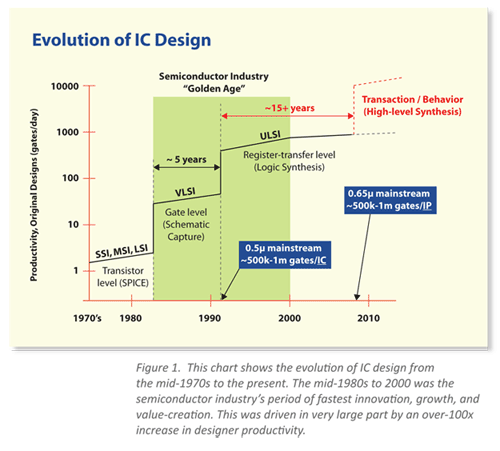
System-on-a-Chip’s (SOCs) [1] have played a large role in the advancement of computing in our daily lives. From computers as specialized as embedded systems on door locks to those as versatile as mobile phones; Even the systems behind the massive data centers on which LLM’s are trained rely on the advancing complexity and efficiency of SOCs. The all-time high demand for SOC architecture advancement has led to tighter and tighter turnaround time requirements. However, current gate-level modeling [2] techniques can take months to years for complex systems. Additionally, many early applications for these models do not require the cycle-accurate [3] computation and communication that they provide. For example, software developers hoping to test code on a platform based on the design specifications may only need approximate timing.
Transaction-Level Modeling (TLM) is a high-level abstraction technique that models data exchanges as "transactions" between components, abstracting away low-level signal details and precise timing to enable faster simulation by orders of magnitude. By abstracting low-level details while maintaining functional accuracy, Transaction-Level Models (TLMs) can still be used for system verification and hardware-software codesign. Thus, Transaction-Level Modeling can be utilized to greatly accelerate the innovation of SOCs in the future.
SOC design is a long, complex process. SOCs often have many different components, from processors and memory to communication units. These components also have numerous connections between them. Given the long design progress, engineers need a way to understand, verify, and optimize the designs of SOCs before they are physically fabricated.
This is where modeling comes in. Traditionally, gate-level modeling simulates the system on a transistor-level. This partially solved the problem of the long SOC design time, as physical fabrication is not necessary for testing. However, gate-level models themselves can take months to years to complete. Additionally, in early-stage applications, engineers don’t need complete control over how data moves through the system on the transistor level. Abstractions can be applied at many points in the model to save time and complexity without taking away from the usefulness of the model to engineers.
Thus, models can be split into two types - functional and performance models. Functional modeling focuses on ensuring that the system performs the right operations, while performance modeling looks at how well the system works in terms of speed, power consumption, and resource utilization. Both have unique time frames, requirements, and uses, yet traditional modeling techniques often require both functional and performance accuracy.
While most SOC designers utilize gate-level models as well as a higher level model, in many applications a unique level of abstraction is necessary. Consider the case of a team of SoC architects working to optimize register counts and connections between components. They hope to understand the power constraints of their system based on how many transactions are made, as well as if each component can transfer data to and from the necessary components. An algorithmic model would abstract these details away, as the intention is to only model the high level functionality of the system without implementation details. Meanwhile, a gate-level model would include multiple signals between components for each connection, adding repetitiveness and unnecessary accuracy. In this case the team of architects needs a model which simulates data flow between components accurately, but does not necessarily detail how exactly the data moves from one component to another.
The core concept of TLM is the transaction [5]—an abstraction for communication. As the name implies, TLMs operate at the transaction level, abstracting away low-level details of communication.
// RTL [4] model of data transfer over a bus
void Bus::transfer_data_rtl(sc_uint<8> data) {
for (int i = 0; i < 8; i++) {
wait(clk.posedge_event()); // Wait for clock edge
data_line.write(data[i]); // Transfer bit-by-bit
ack.write(true); // Acknowledge signal
wait(clk.negedge_event()); // Wait for clock edge
ack.write(false); // Reset acknowledge
}
}
// TLM model of data transfer over a bus
void Bus::transfer_data_tlm(sc_uint<8> data) {
tlm::tlm_generic_payload trans;
trans.set_data_ptr(reinterpret_cast<unsigned char*>(&data));
trans.set_data_length(8); // Set data length for transfer
socket->b_transport(trans, delay); // Send transaction
}
Figure 1. RTL vs. TLM data transfers
For instance, consider a data transfer over a bus. At the RTL level, which models the physical implementation, the model would include clock signals, an "ack" signal, and a bit-by-bit transfer of data. In TLM, however, the same data transfer can be represented by a simple function call, eliminating low-level signals and timing. This approach preserves the overall functionality of the communication while greatly reducing the complexity of the model.
While abstracting communication as transactions allows for significant performance increases, it still preserves crucial functionalities that algorithmic design abstraction does not. Because algorithmic-level models typically represent only the algorithms and control flow of a system, they may not model details such as data dependencies and operation latencies. On the other hand, transactions can be made both in parallel and sequentially, and delays can be included. Software developers may rely on these details to be accurate to the final product to avoid added debugging.
Figure 2. TLM Design and Verification Flow (accelera)
TLM can be integrated into the design flow between RTL and algorithmic modeling. In this type of design flow, the TLM simulation can be used to test low-level details such as data transfer protocols and hardware/software components while working months ahead of the RTL model. To illustrate this, we can walk through an example system design flow which incorporates TLM. The design would start with outlining system requirements and specifications which would apply to models at each level of the design flow. If these change, all models must be modified accordingly. At the next level would be an algorithmic model done in MATLAB or C/C++. Components would be tested as black boxes and their interactions would not be prioritized in this model. Instead, the control flow and algorithms would be verified. A [6] TLM Simulation would comprise the next level. In this model, components are compartmentalized as processes. Intra-process communication would be modeled with transactions, and the core functionality of the components would be transparent. At this level, different architectural decisions can be made. For example, bus widths, register sizes, and communication protocols could be modified in this model. Individual components at this stage could also be modeled using RTL, while communications stay abstracted using TLM. Integration tests can be run, and performance analysis can be done. Finally, at the RTL level, microarchitecture verification such as gate-level verification and timing analysis can be done.
After top-down design, meet-in-the-middle design can be employed. As the IP implementations change, certain details may change at the transaction level. For example, certain IPs may need added registers or interfaces based on debugging needs. Thus, the transaction-level details can be changed to meet both the lower level needs and the higher level system design.
struct CPU : sc_module {
tlm_utils::simple_initiator_socket<CPU> socket; // Initiator socket for transactions
SC_CTOR(CPU) : socket("socket") {
SC_THREAD(run); // Start the CPU thread to send transactions
}
void run() {
tlm_generic_payload trans; // Transaction object
sc_time delay = SC_ZERO_TIME; // No delay initially
// 1. Write Transaction
int write_data = 42;
trans.set_command(TLM_WRITE_COMMAND); // Set command to WRITE
trans.set_address(0x100); // Set memory address
trans.set_data_ptr(reinterpret_cast<unsigned char*>(&write_data)); // Set data pointer
trans.set_data_length(4); // Set data length
cout << "CPU: Writing data = " << write_data << " to address 0x100" << endl;
socket->b_transport(trans, delay); // Send the transaction
// 2. Read Transaction
int read_data;
trans.set_command(TLM_READ_COMMAND); // Set command to READ
trans.set_address(0x100); // Set memory address
trans.set_data_ptr(reinterpret_cast<unsigned char*>(&read_data)); // Set data pointer
cout << "CPU: Reading data from address 0x100" << endl;
socket->b_transport(trans, delay); // Send the transaction
cout << "CPU: Read data = " << read_data << endl;
}
};
In this struct, a CPU module is defined in SystemC. Importantly, it uses the TLM library to model a command issued by the CPU as a transaction. In this case, the transaction has an address, a data pointer, and a size. The blocking transport (b_transport) function allows transactions to be processed in a simplified, high-level sequence, making it easier to model data flow without simulating individual clock cycles or signals.
struct Memory : sc_module {
tlm_utils::simple_target_socket<Memory> socket; // Target socket for receiving transactions
int mem[256]; // Simple memory array
SC_CTOR(Memory) : socket("socket") {
socket.register_b_transport(this, &Memory::b_transport); // Register transport method
}
void b_transport(tlm_generic_payload& trans, sc_time& delay) {
tlm_command cmd = trans.get_command(); // Get command type (READ or WRITE)
sc_dt::uint64 addr = trans.get_address() / 4; // Get address and divide for word addressing
unsigned char* data_ptr = trans.get_data_ptr(); // Get data pointer
if (cmd == TLM_WRITE_COMMAND) {
// WRITE command: store data at address
int* data = reinterpret_cast<int*>(data_ptr);
mem[addr] = *data;
cout << "Memory: Stored data = " << *data << " at address 0x" << hex << addr * 4 << endl;
}
else if (cmd == TLM_READ_COMMAND) {
// READ command: retrieve data from address
int* data = reinterpret_cast<int*>(data_ptr);
*data = mem[addr];
cout << "Memory: Retrieved data = " << *data << " from address 0x" << hex << addr * 4 << endl;
}
// Set transaction status to OK
trans.set_response_status(TLM_OK_RESPONSE);
}
};
In this code segment, the Memory module is defined. The CPU and Memory use target-initiator socket binding, which is a type of connection that can be made which allows for transactions between the two modules. The CPU is the initiator, or the sender, and the Memory is the target, or the receiver. The transaction-level abstraction in TLM allows the CPU and Memory modules to focus on what data is transferred rather than how the signal timing or other low-level details are managed, simplifying the logic and emphasizing system behavior.
SC_MODULE(Top) {
CPU cpu; // Instantiate CPU
Memory memory; // Instantiate Memory
SC_CTOR(Top) : cpu("CPU"), memory("Memory") {
// Connect CPU's socket to Memory's socket
cpu.socket.bind(memory.socket);
}
};
int sc_main(int argc, char* argv[]) {
Top top("top"); // Create top module
sc_start(); // Start the SystemC simulation
return 0;
}
Finally, the Top module is a testbench or model of the top-level chip. In the constructor of the top-level chip object, a connection is made between the CPU and memory, modeling a hardware bus. In a more complex model, the top-level chiplet would call the constructors for all of the modules on the chip, such as different types of memory and logic blocks. Additionally, more connections would be made between these modules. The user could modify which modules were included, the implementations of these modules, and the connections between them. Then, they could write testbench top-level modules which could test the functionality of interactions between these modules. With this approach, extensive testing and performance evaluation of different system designs can be done before the RTL design is complete.
As demonstrated, TLM is a powerful technique which can expedite the SoC design process. It offers simulation speed improvement and system validation higher up in the design flow. However, it is not without its limitations.
Since TLMs are not cycle-accurate, RTL models (or other cycle-accurate models) must still be made for timing verification. To account for this, teams which choose to utilize TLM can allocate less resources to RTL modeling, leading to a net productivity increase.
As a relatively new technique, TLM may be utilized differently between users, causing poor model reusability. Although an established TLM standard has greatly improved the capability for companies and teams to collaborate and share models, this standard is rapidly evolving.
Despite these pitfalls, TLM remains a growing technique in the world of computer architecture design, and for good reason. As the standards mature, TLM will certainly become a key topic in computer architecture design. Companies like NVIDIA and Intel already use TLM to rapidly prototype and validate GPU architectures before committing to costly RTL implementations.
https://www.learnsystemc.com/ https://www.accellera.org/images/downloads/standards/systemc/TLM_2_0_LRM.pdf
https://community.cadence.com/cadence_blogs_8/b/fv/posts/tlm-driven-design-and-verification-solution https://accellera.org/resources/articles/icdesigntrans https://www.cecs.uci.edu/conference_proceedings/isss_2003/cai_transaction.pdf https://systemc.org/overview/systemc-tlm/ https://eprints.soton.ac.uk/263822/1/jpms-memocode07.pdf