Computational Imaging in Computer Vision - 180D-FW-2024/Knowledge-Base-Wiki GitHub Wiki
Introduction
Computer Vision is a vast field that is very new and yet relies on princples that have existed for centuries in the likes of linear algebra, mathematics, and physics phenomena with optics and light refraction. It utilizes principles from signal processing, optics. I will dive deep into the basic computational imaging methods that we use to cleverly process images with classical techniques all the way to modern techniques such as Machine Learning, Feature Extraction, etc.
This is very important for real world situations such as cameras that only capture low quality images, poor lighting, blurred images, or trying to look at the image through a different perspective such as synthetic rotation so we can see nuances that were never visible before in the image.
Signal Processing Theories
In signal processing, it plays a pivotal role to transform the raw pixels in image data to important visual information. Since Images are considered as 2D signals, convolution is a fundamental tool to combine two functions which is very important for edge detection, feature enhancement, and many other techniques in computational imaging for computer vision.
This is extremely powerful if we use deconvolution to grab a blurry input image and perform a deconvolution operation to minimize the blur in pixels. Here is one example where signal processing is used to perform such an operation on the image. In the example below, this is a an image with blurred features and it is essentially through a de-convolved process to grab specific features albeit not being complete.
Linear Algebra
Linear algebra is a major building block in Computer Vision for image processing and detection systems or manipulations of the image. Images in Computer Visions are typically represented as matrices where each pixel is correspondent to an element in the 2D grid system. For grayscale it holds single intensity value and colored images have each pixel contain red green and blue values (RGB). Two important matrices we use are called Prewitt and Sobel filters where it helps get edges of an image for object detection. Linear Algebra helps combat noice by averaging the values through matrix operations and localization accuracy. Below I will talk about the Sobel Filter in particular and its application. It is a filter with weights typically in a 3x3 dimensional matrix. First we convert it into homogenous coordinates and then transform the matrix. This is very useful in the sense that it detects areas of high spatial frequency to emphasize changes in x and y direction.
The Sobel Filters detects edges with the matrices applied using a convolution as mentioned in the signal processing section. When these matrices are applied each pixel value is replaced by a weighted sum of the surrounding pixels in the filter. By combining outputs of both vertical and horizontal oriented filters, the gradient magnitude identifies the edges within the image which is essential for computer vision in object detection.
Corner Detection utilizing Multivariable Calculus
Corner detection is an essential purpose in Computer Vision where it identifies points in an image where edges intersect. This utilizes gradients which are partial derivatives to channel and identify local intensity in multiple directions. This use of partial derivatives captures changes in pixel intensity in both the horizontal and vertical direction. When the gradient of an image is computed with these derivatives, it reveals the intensity or brightness in the pixels of the image which is very useful for feature extraction in an image and finding out where an image can be easily identifiable. One such popular principle that is used is called the Harris Corner Dectector where it uses a scoring function deriving from gradient and curvatures with first and second derivative to result in eigenvalues of the matrix. This improves reliability of feature matching and understanding the scene of the image.
What occurs below is that there is a window function with an applied Taylor expansion and I_x and I_y are the image derivatives in the x and y directions. Then a score is created where it is determined if the window contains a corner or not. When the magnitude of the eigenvalues reach the top right of Harris Corner Diagram below, that means a corner is detected and it is likely a suitable window opportunity for clear object detection.
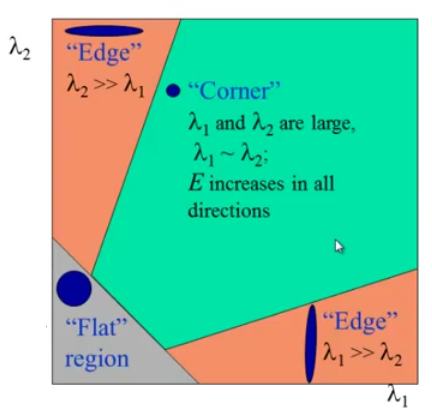
Continuing on corner detection which is fundamental in CV applications, the equation R has M being the second moment matrix derived from the image x and y coordinate gradients that capture intensity in x and y direction. The determinant of the Matrix measures overall change and trace represents the sum of changes along the axis. The probabilistic approach here is the scoring function where it tracks two metrics with a tunable parameter k that balances the sensitivity between edge and corner detection. This is essential for the detected features to be robust and reliable.
Color Depth
What is very important in computational imaging is the number of bits used to represent a single pixel in an image. If you are using Red Green Blue pixel values (RGB) these are generally from 0 to 255 intensity value. 24 bits per pixel is a standard for color depth as it is good for intensity values and display of image. For imaging systems, this helps with shading profiles so that a single pixel can be analyzed for image processing. For example, you use a 2D intensity pattern and project it and utilize a photodetector to write a reflection of it. You can then combine three images of different color schemes to reconstruct a more clear and visually accurate image. Color depth photodetction is a very useful tool for colored image reconstruction.
AI and Machine Learning in Computer Vision
Artificial intelligence (AI) and machine learning (ML) integration in the field of computer vision has revolutionized computational imaging. Both artificial intelligence and machine learning has enabled breakthroughs in image reconstruction, denoising, and super-resolution. Traditional computer vision methods often rely on explicitly defining physical rules and processes, which can restrict their effectiveness. On the other hand, deep learning-based approaches such as convolutional neural networks (CNNs) and vision transformers (ViT) are able to automatically learn relevant patterns from the data, potentially leading to more accurate and more data curated results. For instance, vision transformers (ViT) have been proven to be a better deep-learning model over convolutional neural networks (CNN) by processing the entire images holistically, achieving top of the line performance in object detection and object segmentation. ViT achieves this through self-attention mechanism, in which images are split into patches and analyzed as sequences to capture long-range dependencies between pixels while CNN relies on localized receptive fields to detect hierarchical features but struggle with global context. Furthermore, generative adversarial networks (GANs) enhance tasks like super-resolution by training a generator to synthesize realistic details and a discriminator to evaluate outputs in iterative fashion. In contrast, traditional methods such as scale-invariant feature transform (SIFT) and speeded-up robust features (SURF) that relies on handcrafted feature extraction that limits their adaptability to complex and dynamic environments. These advancements underscore artificial intelligence’s role in computational imaging, balancing innovation with persistent technical challenges.
Hybrid-AI Enabled Computational Imaging
Combining deep learning with classical computer vision algorithms addresses the limitations in adaptability and computational efficiency. ViT does an excellent job in holistic image analysis. However, ViT requires a lot of computational resources, making them not feasible to be used in resourced-constrained edge devices. For instance, while ViT has superior performance in comparison to CNN, ViT requires three to five times the computational demands that of convolutional neural networks CNN. Hybrid systems is one of the best solutions for this by integrating vision transformers ViT with CNN for real-time lightweight processing and traditional algorithms such as SIFT and SURF for its low-level tasks; getting the lightweight implementation benefit of traditional algorithms and the capabilities of AI approaches. The core components of hybrid systems include algorithmic synergy and hardware-software co-design. ViT is used to analyze global context for tasks such as tumor segmentation, while CNN is used to handle the localized feature extraction. Then, classical computer vision algorithms are integrated for specific tasks, for instance as optical flow algorithms for motion tracking. Hardware-software co-design is extremely crucial for optimized performance, especially for edge computing, in which with lightweight ViT distilled version can reduce the parameters by 70%, essentially making it cheaper to run. Applications of hybrid-AI computational imaging are broad. It spans from medical diagnostics to edge devices. In medical imaging, hybrid systems achieve 99% specificity in early-stage tumor identification. For edge devices, advanced architectures enable 4K HDR video processing on smartphone devices. Despite all of the advancements, challenges surrounding hybrid-AI computational imaging persists, especially in the realm of data bias and energy efficiency.
Conclusion
In summary, Computer Vision is a dynamic and rapidly evolving field to this day that bridges mathematics principles and signal processing methods with modern techniques such as Machine Learning to be able to extract features. Leveraging concepts such as convolution, matrix transformations, gradients from calculus, can help enhance image quality, edge detection and identifying corners in images. Techniques such as Sobel filters and Harris Corner Detection blend several mathematical tools to allow for precise object recognition and scene reconstruction. Color depth is also a parameter to take advantage of for image reconstruction to combine recognition processes and utilize pixel intensity values to garner more visually appealing results. As computational power and more clever methods are discovered, the potential for Computer Vision is vast and evolving.
Works Cited
https://docs.opencv.org/4.x/dc/d0d/tutorial_py_features_harris.html
https://imagej.net/imaging/deconvolution
https://distill.pub/2016/deconv-checkerboard/
https://towardsdatascience.com/magic-of-the-sobel-operator-bbbcb15af20d
https://opg.optica.org/oe/fulltext.cfm?uri=oe-21-20-23068&id=267566
https://www.nature.com/articles/s41598-024-72254-w
https://pmc.ncbi.nlm.nih.gov/articles/PMC11393140/
https://arxiv.org/html/2404.16564v1
https://openreview.net/pdf?id=R-616EWWKF5
https://research.google/pubs/vitgan-training-gans-with-vision-transformers/
https://viso.ai/deep-learning/image-reconstruction/
https://docs.opencv.org/4.x/dc/d0d/tutorial_py_features_harris.html
https://imagej.net/imaging/deconvolution
https://www.medrxiv.org/content/10.1101/2024.06.21.24309265v1.full
https://src.acm.org/binaries/content/assets/src/2024/haoran-you.pdf
https://www.redhat.com/en/topics/edge-computing/what-is-edge-ai
https://www.edge-ai-vision.com/2024/03/vision-transformers-vs-cnns-at-the-edge/