20220604: Mastering the Basics of SQL Server Query Optimization - 1001fufu/Learning-Log GitHub Wiki
Parse -> bind -> optimization -> execution

Scan & Seek:
Anatomy of execution plan: Nested loop (inner join) -> seek Hash map (inner join) -> scan
a table without cluster index: heap vs a table with cluster index
- select * from table (no primary key -> no cluster index) -> table scan
- select * from table (primary key -> cluster index) -> cluster index scan
- select * from table where primary_key = $$ -> cluster index seek
- select * from table where other non-cluster index fields = $$ -> non-cluster index seek
- select other_fields from table where other_fields = $$ -> index seek + key lookup (inefficient)
hash join & hash aggregate Now, the query optimizer might choose a Hashmat aggregate for big tables where the data is not sorted.
DISTINCT:
A query using the distinct keyword can be implemented by a
- stream aggregate
- or hash AGGREGATE
- or distinct sort operator
Now, the distinct sort operators used to both remove the duplicates and sought its input.
If an index to provide sort of data is available, the optimizer can use that stream aggregate operator. If no index is available, SQL Server can introduce a distinct sort operator or a hash aggregate operator.
Join
SQL Server uses three operators to implement logical joins
- the nested loop,
- the merge,
- the hash.
Join (Nested loop):
The input shown at the top and a nested loop joint plan is known as the outer input, and the one at the bottom is the inner input.
The algorithm for a nested loop joint is very simple,
- the operator used to access the outer input is executed only once
- and the operator used to access the inner input as executed once for every single record that qualifies for that outer input.

Join (Merge Join):
One difference (Nested Loop vs Merge Join) is that in merge join, operators are executed only one time.
Another difference in the merge joined requires inequality operator and its input.
Now this is important and its input be sorted on the join predicate.
max(cost) = sum of inputs

Join (Hash Join):
Hash join requires an equality operator on the joint predicate. But unlike the merged joint, no need inputs to be sort. It's operators in both inputs are executed only once.
The hash joint works by creating a hash table in memory.
The up march will then use cardinality estimation to detect the smaller of the two inputs called the BUILD INPUTS.

Parallelism
It's a feature of SQL Server, which allows expensive queries to utilize more threads in order to complete quicker.
- Execution plans - tells you how a query will be executed, or how a query was executed.
- Result Operator - Represents SELECT statement and is the root element of the plan.
- Scan - An index scan or table scan is when SQL Server has to scan the data or index pages to find the appropriate records.
- Seek - a seek uses the index to pinpoint the records that are needed to satisfy the query.
- Bookmark Lookup- the process of finding the actual data in the SQL table, based on an entry found in a non-clustered index.
- RID lookup - if the table does not have clustered index, but a non-clustered index.
- Key Lookup - a bookmark lookup on a table with a clustered index.
- Covering Index - A covering index is a non-clustered index which includes all columns referenced in the query and therefore, the optimizer does not have to perform an additional lookup to the table in order to retrieve the data requested
- Aggregates - Perform a calculation on a set of values and return a single value.Aggregate functions perform a calculation on a set of values and return a single value. (AVG,MIN,MAX)
- Stream Aggregate - The operator for Stream Aggregate is very common, and it is the best way to aggregate a value, because it uses data that has been previously-sorted in order to perform the aggregation quickly.
- Hash Aggregate - This aggregate does not require (or preserve) sort order, requires memory, and is blocking Hash aggregate excels at efficiently aggregating very large data sets.
- Nested Loop Join - A Nested Loops join is a logical structure in which one loop (iteration) resides inside another one.
- Merge Join - Because the rows are pre-sorted, a Merge join immediately begins the matching process. It reads a row from one input and compares it with the row of another input.
- Hash Join - A Hash join is normally used when input tables are quite large and no adequate indexes exist on them. A Hash join is performed in two phases; the Build phase and the Probe phase and hence the hash join has two inputs i.e. build input and probe input.
- Parallelism - Parallelism is a feature in SQL Server which allows expensive queries to utilize more threads in order to complete more quickly.
- Cost Threshold for Parallelism - The optimizer uses that cost threshold to figure out when it should start evaluating plans that can use multiple threads.
Summary
- The I/O Cost and CPU cost are not actual operators, but rather the cost numbers assigned by the Query Optimizer during its calculations.
- Physical operators implement the operation described by logical operators. Each physical operator is an object or routine that performs an operation.
- The SORT operation is a very expensive task, and it usually requires a lot of memory.
- The easiest way to avoid a SORT is by creating an Index.
- Quite often, the queries that qualify for parallelism are high IO queries.
How statistics affect decision?
Cardinality: no. of rows in a table
Selectivity: % input rows that satisfy
no 1 cause of performance related issues - out of date statistics
- impact execution plan, recompile execution plan in plan cache
statistic maintenance - auto update to kick in
auto job: http://sqldbpros.com/wordpress/2010/10/fastest-way-to-update-stats-on-sql-server-with-fullscan/
-
Density - Density is a ratio that shows just how many unique values there are within a given column, or set of columns. A high density (low selectivity, few unique values) will be of less use to the optimizer because it might not be the most efficient way of getting at your data.
-
Histogram - A function that counts the number of occurences of data that fall into each of a number of categories (also known as bins) and in distribution statistics these categories are chosen so as to represent the distribution of the data. It’s this information that the optimizer can use to estimate the number of rows returned by a given value.
-
Cardinality - Cardinality estimates are a prediction of the number of rows in the query result. The query optimizer uses these estimates to choose a plan for executing the query. The quality of the query plan has a direct impact on improving query performance.
-
Sys.Stats - Contains a row for each statistics object that exists for the tables, indexes, and indexed views in the database in SQL Server.
-
AUTO_CREATE_STATISTICS - the SQL Server will automatically create statistics for non-indexed columns that are used in your queries.
-
AUTO_UPDATE_STATISTICS_ASYNC - When this option is enabled, the Query Optimizer will not wait for the update of statistics, but will run the query first and update the outdated statistics afterwards. Your query will execute with the current statistics and a background process will start to update the statistics in a separate thread.
-
AUTO_UPDATE_STATISTICS - relies on number of rows changed or updated to determine if statistics update is needed. However, when a table becomes very large, the old threshold (a fixed rate – 20% of rows changed) may be too high and the Autostat process may not be triggered frequently enough. This could lead to potential performance problems.
-
The SQL Server Query Optimizer uses this statistical information to estimate the cardinality, or number of rows, in the query result to be returned
-
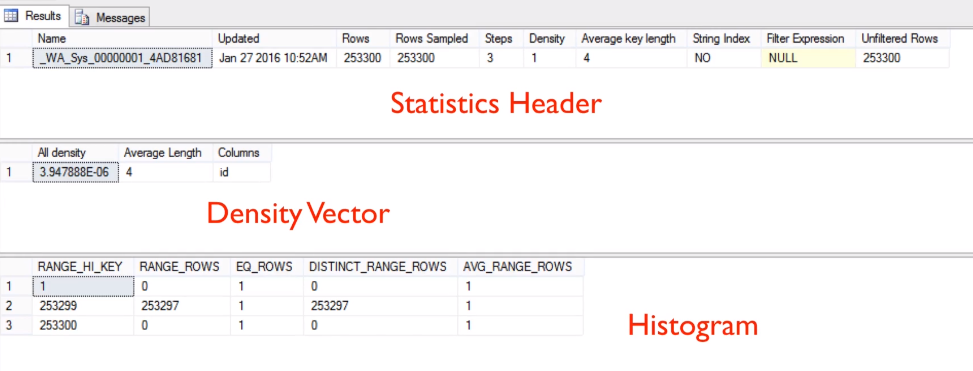
Each statistics object contains a histogram displaying the distribution of values of the column (or of the first column in the case of multi-column statistics). Multi-column statistics also contain a correlation of values among the columns (called densities), which are derived from the number of distinct rows or the column values.
-
Substantial data change operations (like insert, update, delete, or merge) change the data distribution in the table or indexed view and make the statistics goes stale or out-of-date.
-
With the default configuration (if AUTO_UPDATE_STATISTICS is on), the Query Optimizer automatically updates statistics when they are out of date.
-
Both histograms and string statistics are created only for the first column of a statistics object, the latter only if the column is of a string data type.
-
The statistics which are automatically generated by the Query Optimizer are always single-column statistics
-
The Query Optimizer always uses a sample of the target table when it creates or updates statistics, and the minimum sample size is 8 MB, or the size of the table if it's smaller than 8 MB.
Real World Problem:
The scan on large table:
set statistics IO on
set statistics profile on
- Using this output, you can easily compare the actual number of rows, shown on the Rows column, against the estimated number of records, as shown on the Estimate Rows column, for each operator in the plan.
- Another nice thing about the output is that we can easily see IO and CPU estimated usage. This can give us critical insight into just how costly the query is for the box, the SAN or both.
- Note: I've altered the column output of SET STATISTICS PROFILE ON for easy viewing.
Bad idea if table is a heap (table with no cluster index)
All sorts are bad.
unwinding the spool
- They are internal in memory or on disk caches for temporary tables. (that is why call lazy)
- creating covering index - remove lazy spool (temp table stored in cache that would be used multiple times in complex query.)
**summary: **
- Index Scans generally aren’t the sort of thing you’d want to see in a query plan. An index scan means that all the leaf-level pages of the index was searched to find the information for the query. Well, not necessarily all... the ones need to fulfill the query.
- A scan is the opposite of a seek, where a seek uses the index to pinpoint the records that are needed to satisfy the query.
- The missing indexes feature uses dynamic management objects and Showplan to provide information about missing indexes that could enhance SQL Server query performance.
- The problem with just blindly creating this index is that SQL Server has decided that it is useful for a particular query (or handful of queries), but completely and unilaterally ignores the rest of the workload.
- SET STATISTICS IO ON tells you the number of logical reads (including LOB), physical reads (including read-ahead and LOB), and how many times a table was scanned.
- Logical reads are how many time SQL Server pulled pages from the buffer pool to satisfy the query.
- A heap is a table without a clustered index. One or more non-clustered indexes can be created on tables stored as a heap. Data is stored in the heap without specifying an order.
- To guarantee the order of rows returned from a heap, you must use the ORDER BY clause.
- When a table is stored as a heap, individual rows are identified by reference to a row identifier (RID) consisting of the file number, data page number, and slot on the page. (Hence the operator name RID Lookup)
- The SORT operator sorts all rows received by the operator into order.
- It’s important to you keep in mind that, in some cases, the SORT operation is performed in the temporary database Tempdb which can lead to contention.
- The SORT operation is a very expensive task, and it usually requires a lot of memory.
- There are five types of Spool operations but they all share in common the way that they save their intermediate query results on the TempDB database.
- A spool reads the data and saves it on TempDB. This process is used whenever the optimizer knows that the density of the column is high and the intermediate result is very complex to calculate.