Distributed web crawler - sovonnath/system-design GitHub Wiki
Distributed web crawler
Requirements:
- Crawl and index the web only for html pages
- Optimize the latency to crawl the web
- Be polite
NFR:
- Total web pages = 1B
- Each page is 10 Kb in average
API: There are no api for this. This is a back end application.
HLD: Before we optimize this for a distributed environment, let's just build this for one data center.
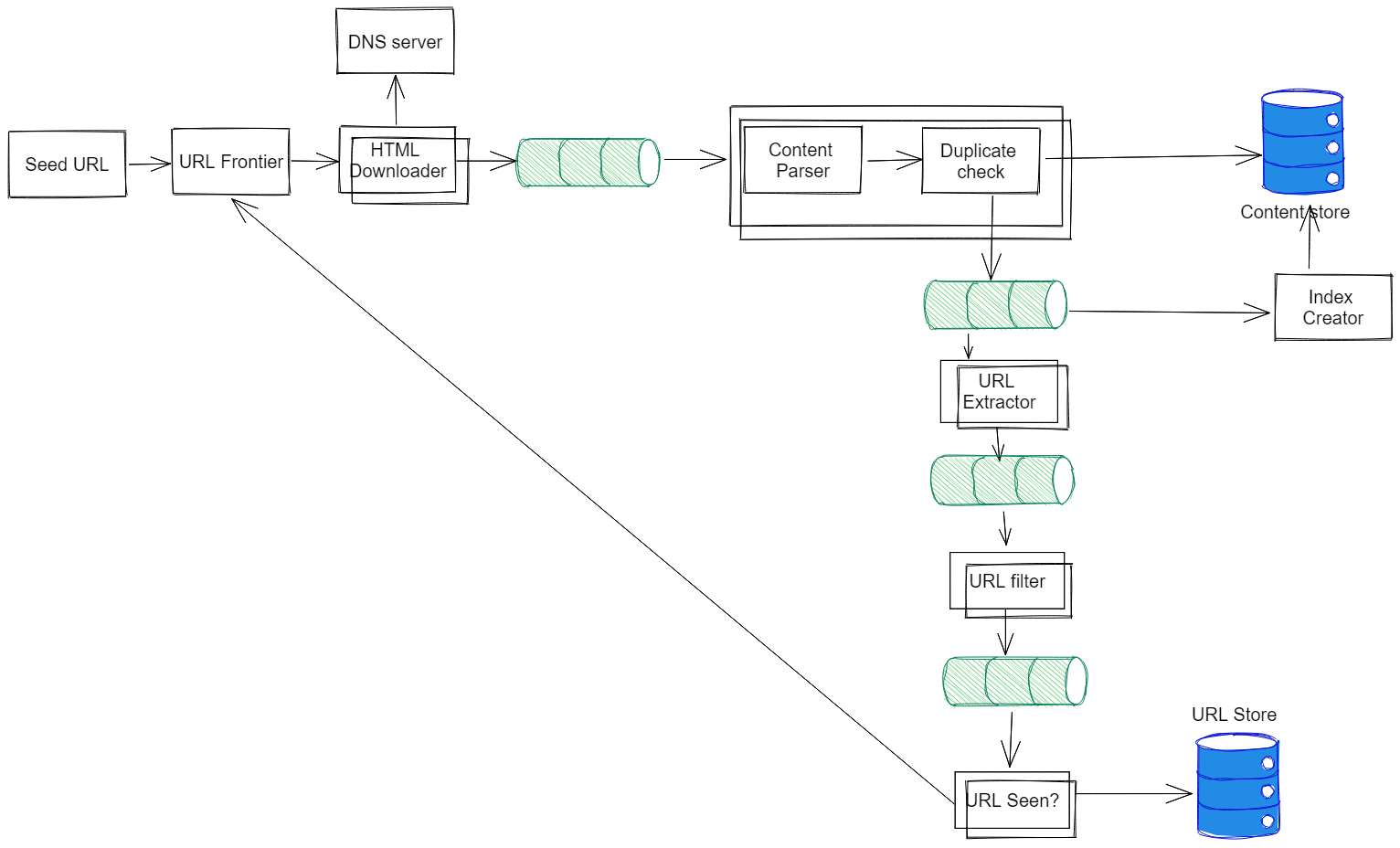
Some of the options for distributed computing are:
-
Just have all of this run from one data center and have a shared storage but shard the crawler based on the URL
Pros: this is simple
Cons: this will increase the latency for the application to download the content
-
Geographically distribute the crawlers but keep the storages in one datacenter
Pros: Relatively simple but still we get the benefit of reduced crawling latency
Cons: There may still be latency when we are storing the content and other data
-
Implement this by distributing the crawlers in various data centers
Pros: This will reduce the latency of downloading the data
Cons: Increased coordination
Based on this option 3 looks to be the most appropriate.
In order for this to work as distributed web crawler that is across the globe we have to share the following:
- Crawl-Jobs: It is the list of URLs to be crawled.
- Seen-URLs: It is a list of URLs that have already been crawled.
- Seen-Content: It is a list of fingerprints (hash signature/checksum) of pages that have been crawled.
Reference: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.9.9637&rep=rep1&type=pdf